
How we approach testing VSTS to enable continuous delivery
I like to write, from time to time about our experiences, successes, failures and learnings from delivering Visual Studio Team Services (VSTS), a large scale service, on a cloud delivery cadence. My most recent post reflected on how cool it is to be able to deliver customer fixes within a day or two. And I’ve written many times about our practice of delivering all our work to production every sprint (or, in some cases, even more often).
Usually my posts are sparked by something I see happen. Today I got an email about progress on our efforts towards reliable tests and it made me think about sharing it.
When we first started the journey towards accelerated delivery we began by accelerating all the processes we’d had in place for years. It quickly became apparent that doing that would never get us to where we wanted to be and we had to be prepared to do things very differently. In the intervening 6 years or so, we have gone through many transformations – how we plan, track progress, deploy, manage feedback, monitor, architect, develop and test. Change has been constant over the 6 years and we’re no where near finished – I’m not sure we’ll ever finish. If we’d tried to do it all at once. I’m sure we would have failed. Taking it one or two key practices at a time has worked out well for us and allowed us to bring the team and the code base along for the ride. A little over 2 years ago, we realized that one of our biggest remaining impediments to our goal of “continuous delivery” was test – everything about test: our org, roles, frameworks, tests, harnesses, analysis, …
Two years ago, we had 10’s of thousands of tests. They were written by “testers” to test code written by “developers”. While there were some advantages of this model – like clearly measurable and controllable investment in test, expertise and career growth in the testing discipline, etc. there were also many disadvantages – lack of accountability on the developers, slow feedback cycle (introduce bug, find bug, fix bug), developers had little motivation to make their code “testable”, divergence between code architecture and test architecture made refactoring and pivoting very hard/expensive, and more.
A very high percentage of our tests were end-to-end functional “integration tests”. Often they automated UI or command line interfaces. This meant that they were very fragile to small/cosmetic changes and were very slow to run. Because UI code isn’t really designed to be testable there were often random timing issues and the test code was littered with “Sleep(5000)” to wait for the UI to reach a steady state. Not only was that incredibly fragile (sometimes the UI would take a while – network hiccup or something), it also contributed greatly to the tests taking a very long time to run.
The result of all of this is that full testing would take the better part of a day to run, many more hours to “analyze the results” to identify false failures and days or weeks to repair all the tests that were broken due to some legitimate change the in the product.
So, 2 years ago, we started on a path to completely redo testing. We combined the dev and test orgs into a consolidating “engineering” org. For the most part, we eliminated the distinction between people who code and people who test. That’s not to say every person does an identical amount of each, but every person does some of everything and is accountable for the quality of what they produce. We also set out to completely throw away our 10’s of thousands of tests that took 8 years to create and replace them with new tests that were done completely differently.
We knew we needed to reduce our reliance on fragile, slow, expensive UI automation tests. We created a taxonomy to help us think about different “kinds” of tests:
- L0 – An L0 test is a classic Unit Test. It exercises an API. It has no dependencies on the product being installed. It has no state other than what’s in the test.
- L1 – An L1 is like a Unit Test, except it can rely on SQL Server being in the environment. Our product is very SQL Server dependent and, in my opinion, trying to mock SQL is unwise/impractical for the depth of dependency that we have. Also, of course, a bunch of our code is in SQLServer stored procs and we need to test that too.
- L2 – An L2 test is written against a fully deployed TFS/Team Services “instance” but with some key things mocked out. The mocking is done to simplify testing and eliminate fragility. The best example is that we mock out authentication so we don’t have to deal with creating test identities, managing secrets, etc. Some L2s are UI automation but only a smallish percentage.
- L3 – An L3 test is an end-to-end functional test against a production TFS/VSTS instance. You might call it “Testing in Production” Many of these are UI automation. The truth is that we’ve only recently gotten to the point that we’re ready for rolling out L3 tests and we only have a few. Over time, the count will grow some but it will always be a tiny fraction of L0 and L1.
Early in the process, we created this diagram to demonstrate what we were after in the transformation. TRA, BTW, stood for “Tests Run Anywhere” – that’s what we called our last generation testing framework and it was an advance over the previous generate where tests could only run in controlled lab environments (developers couldn’t run the tests on their own).
![]() We’re probably 95% done with the transition now and here’s where we are today:
We’re probably 95% done with the transition now and here’s where we are today:

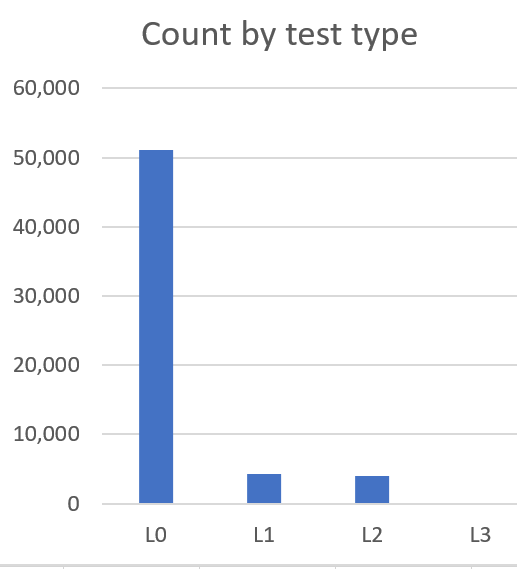 We run the L0 and L1 tests as part of every Pull Request – so every checkin gets that much validation. We then run rolling runs of L2s all day. A big part of that time, btw is installing and configuring an instance to test against. We haven’t established a consistent practice for running L3’s though, I expect, they will be run as part of every release definition to validate post-deployment.
We run the L0 and L1 tests as part of every Pull Request – so every checkin gets that much validation. We then run rolling runs of L2s all day. A big part of that time, btw is installing and configuring an instance to test against. We haven’t established a consistent practice for running L3’s though, I expect, they will be run as part of every release definition to validate post-deployment.
This is all coupled, of course, with other process changes (like feature flags and ring based deployment). I’m focusing on testing here but you really can’t separate them. We couldn’t really rely on Test in Production the way we are headed without also doing ring based deployments, for instance. But this whole post was kicked off by a mail I got about test reliability – so everything above here is really context 🙂
The changes above go a long way to helping test reliability – but doesn’t solve it 100%. Tests are still code. Code has bugs. Tests can fail for even when the code they are testing is working correctly. The most insidious form of these are “flakey” tests – tests that pass sometimes and fail others. Years ago, we used to have a bug resolution called “pass on re-run”. And that meant a test failed and someone went to debug it and every time they ran the test, it passed so they just resolved the bug. I used to rant about how bad this was. There’s a bug there – it might be a product bug and it might be a test bug but it’s a bug and it needs to get fixed.
Flakey tests also erode developer confidence in the tests. If a test fails and you are pretty sure your changes can’t have affected it, you have an urge to ignore the failure. The problem is sometimes your change did break it or maybe it’s a latent bug that the team allows to perpetuate because the tests aren’t “trustworthy”. It’s also just plain inefficient to be constantly dealing with rejected runs and debugging sessions that yield nothing due to flakey tests. It must be the case that when a test fails, the vast majority of the time, there really is a product bug to go fix.
Over the past many months, we’ve been instituting a formal test reliability process. Our test reliability runs are rolling runs that run 24×7. A reliability run picks the latest successful CI build, runs all the tests and looks at the results. Any test that fails is considered flakey (because it previously passed on the same build). The test is disabled and a bug is filed. When the run completes, it again picks the most recent succeeding CI build (might be the same one if there’s not a newer one) and repeats. Once the bug associated with a flakey test is resolved, the test is automatically re-enabled.
Here’s a graph of our test run reliability over the past year We rolled out the new reliability system in sprint 116.
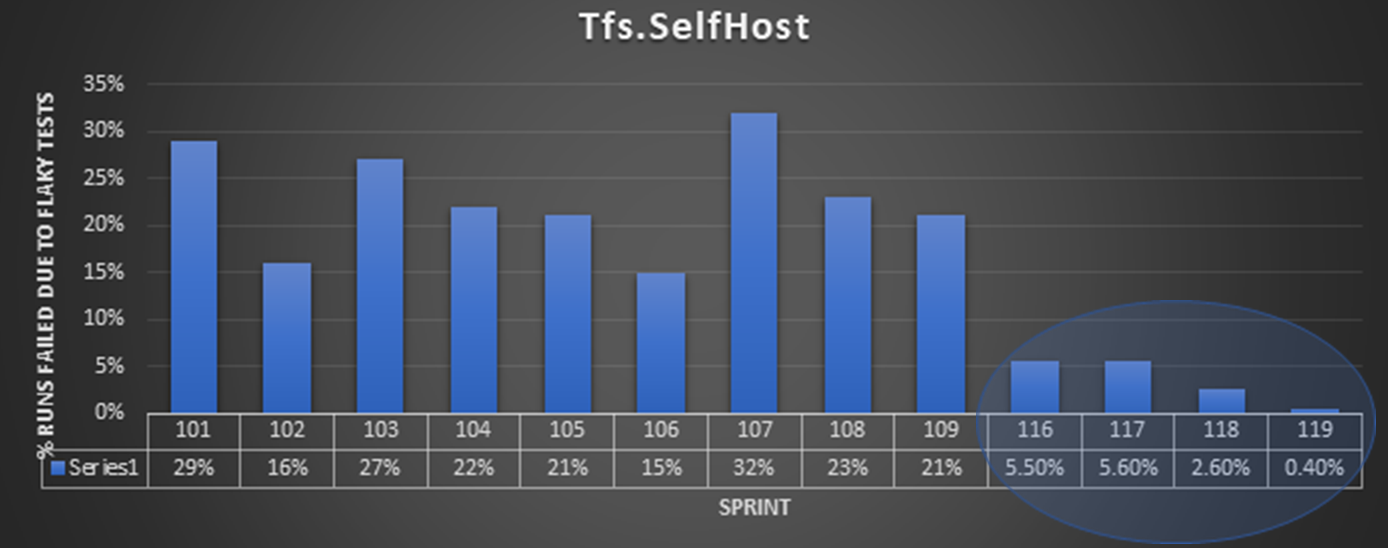
Now you might say, “well, all you’ve showed me is that you disabled a bunch of tests in sprint 116.”. Clearly cutting a bunch of test coverage would be a bad outcome. The system tracks resolution time on these bugs and in the sprint 116 -> 119 time period, there were 170 test reliability bugs with an average resolution time of 3.75 days – so tests weren’t disabled for too long.
Now, as you may guess, not all the bugs the reliability system finds are test bugs – sometimes they are race conditions in the product itself. It’s a small percentage but we’ve definitely seen some. In my book the opportunities to fix those is even better.
Right now, the reliability system is only rolled out for L2 tests. There aren’t many L3s yet and the L2s are, by their nature, much less reliable than L0’s and L1’s so we started there.
Overall, this effort to completely redo our test system over the past 2+years has been a massive investment. Every single sprint many feature teams across my team invested time in this. In some sprints it was most of what a feature team did. I’d hate to even try to calculate the total cost but we couldn’t go where we are trying to go with the business without doing it, so I know, in the long term it was worth it. I have to admit that 18 months into it and lots of missed opportunity cost later, I started to agitate about when we were going to be “done” with it. It was a bit nerve fraying to see it continue to drag on but, it was a big investment and not every team did the work at the same time. And I kept reminding myself how much better it was going to be when we were done.
While we’re still not completely done with this transition, we’re close enough that I think of us as done. No feature teams are reporting work on this as a significant part of their work in their sprint mails and we are starting to reap the benefits in improved quality, agility and engineer satisfaction. As this has been drawing to a close, we’ve already started our next big engineering investment – containerization of all of our services. We think the benefits here are going to be innumerable, including improving our tests – by making test deployments faster, easier to do compat testing and more. Once we’ve made a bit more progress on that, I’ll write something up.
No engineering team should ever stop investing in improving their engineering systems.
UPDATE: Oh and one more point I meant to make… As we wrap up this work, we are looking at how to ship this automation and workflow in the VSTS/TFS product so it will be a little easier for you all to implement it than it was for us. I hope to get something on the published roadmap before too long. UPDATE: I don’t like doing updates because people don’t get notified about the change but I stumbled across some additional interesting data. I was reading one of our Monthly service reviews and saw this piece of data about my team’s test runs: o All of the VSTS L0/L1/L2/L3 tests are now using MSTest V2. They clock ~450 runs per day with each run having ~45300 tests (typical working day). That is in the order of 20 Million test executions per day.
Another piece of data I came across was a chart showing the migration of our “old” tests to “new” tests over more than a 2 year period (each sprint is 3 weeks). The data is a little “dirty”. There were more “old tests” discovered along the way so the initial count is actually lower than reality. Old tests, because they were much more heavy weight also tended to exercise more surface area where as “new” tests are more focused and therefore more numerous. Gold is the old TRA tests and various shades of blue are the L0/L1/L2/L3 tests.

Thanks, Brian
 Light
Light Dark
Dark
1 comment
Hi Brian,
I came accross this article just now, and it’s a very interesting one, so thank you very much for that.
We also have a system which is very heavy on its relationship with SQL Server but also has lots of Web API endpoints and MVC controllers/actions such as yours I believe.
I always find myself trying to figure out what kind of test I can have for L0 – how much have you guys spent on refactoring your code to make something that you can write these L0 tests. What are really these tests?
I’m also interested in understanding what was your approach for creating the L1 tests.
Thanks,
Ami