
Microsoft Visual Studio 2017 Supports Intel® AVX-512
For this post we welcome John Morgan from Intel Corporation as guest author on the Visual Studio Blog. John has been with Intel for nine years, but his contributions to the Microsoft compiler stretch back through two decades and three other companies. He gratefully acknowledges help with this post from others at Intel and Microsoft.
This post explores Intel® Advanced Vector Extensions 512 (Intel AVX-512), and how they are supported in Microsoft Visual Studio 2017, particularly in Microsoft Visual C++, Microsoft Macro Assembler (MASM), and the Microsoft Visual Studio IDE debugger, along with typical applications for vector calculations, such as artificial intelligence/machine learning, multimedia encoding and decoding, and high-performance computing workloads like simulation, and climate/weather modeling.
Introduction
Both Microsoft and Intel® are in the business of change. By changing what computers can do, we change what people can do with computers, and that changes people’s lives. An important part of that change is the ability to handle bigger calculations to gain more actionable insights than ever before, so tasks like intelligent data retrieval and autonomous driving are science, and not just science fiction. To meet the demand for more data computation Intel introduced the Intel AVX-512 family of instructions, which are available in the new generation of Intel® Xeon® processors and some of the new Intel® Core™ X-series desktop processors, as well as current Intel® Xeon Phi™ processors. Microsoft Visual Studio 2017 supports Intel AVX-512, and with Visual Studio 2017 version 15.3 we’re enhancing that support to include more Intel AVX-512 instructions than ever before.
Vector Computation
Intel AVX-512 raises the bar for vector computing. Like the Intel Advanced Vector Extension (Intel AVX) instruction set extension that preceded it, Intel AVX-512 allows a single instruction to perform a calculation on multiple values at once, and, as the name implies, it extends this capability up to 512 bits at a time. However, this is not all it does. New features make it easy to perform calculations that were not practical before. Masking lets you vectorize conditional code, embedded broadcast lets you use scalar values directly in calculations, embedded rounding control lets you control rounding or exceptions on a particular instruction without having to alter the control register, and new instructions perform calculations that might have taken dozens of instructions before. These new and enhanced capabilities are important for workloads like machine learning (artificial intelligence) as well as audio and video compression, and classic HPC workloads like simulation.
Machine learning involves both training to create a network and using the deployed network, and vector calculations with various data types can be used in both steps. Intel AVX-512 supports vectors with a variety of integer and floating-point types from double-precision floating-point to vectors of byte-size integers. It also has a set of enhanced conversion instructions that allow greater flexibility in balancing performance, accuracy, and storage efficiency.
Vector calculations are also used in video and audio compression. Multimedia compression often uses aspects of human perception to discard unneeded data and allow a data stream to be reduced to a small fraction of the uncompressed size. Most of the computation to do this can be done with vector operations. The most popular formats often have special hardware support, but general vector computations can be used for less-common and future formats.
The most important high-performance computation (HPC) workflows are also done using vector calculations. These include weather and climate modeling, seismology, oil and gas exploration, medical imaging, and more. Intel AVX-512 provides a flexible and convenient capability for doing these kinds of tasks.
What is Intel AVX-512?
Intel AVX-512 has a set of foundational instructions and instruction forms, and extends that with several additional sets for special purposes, totaling about 700 new and modified instructions. These instructions handle basic arithmetic operations, type conversions, and more specialized operations. As the computing market changes and new operations are needed, new Intel AVX-512 instruction set extensions may be added to meet those needs. Microsoft Visual Studio support for these extensions will be built on the foundational support of Intel AVX-512 in Microsoft Visual Studio 2017.
More information on Intel AVX-512 can be found at https://www.intel.com/content/www/us/en/architecture-and-technology/avx-512-overview.html, and in Volumes 1 and 2 of the Intel® 64 and IA-32 Architectures Software Developer’s Manual.
Visual Studio 2017
So, what exactly does Microsoft Visual Studio 2017 version 15.3 let you do with Intel AVX-512? The most essential part of Intel AVX-512 support is in Microsoft Visual C++, where you can define 512-bit vector variables, assign their values to other variables of the same type, and pass them to and from functions as arguments and return values. There are over 1300 new intrinsic functions that correspond to the Intel AVX-512 instructions in currently released Intel processors, including variations for masking with default values of zero, masking with specified default values, and, where applicable, embedded rounding or exception control. These functions cover 512-bit vector operations, and scalar operations for most AVX-512 instructions. Support for 128-bit and 256-bit vector operations, and additional scalar functions is planned for a future release. The use of intrinsic functions requires programmers to learn how to use them for best effect, but offers better control than automatic code generation. Microsoft Visual Studio 2017 also includes support for Intel AVX-512 in the Microsoft Visual Studio IDE debugger, and Microsoft linker (dumpbin). Beyond that, Visual Studio 2017 version 15.3 adds support for over 700 new and modified Intel AVX-512 instructions in the Microsoft Macro Assembler (MASM).
Example
Let’s look at an example, first with basic Intel AVX-512 instructions, and then the equivalent C code. Here is a version of the Quicksort pivot function that was chosen because it is good for illustrating Intel AVX-512 features. This function takes a value called the pivot and an input list, and separates the list into a list of values greater than the pivot, and a list of values smaller than the pivot. The output lists are contiguous so that the final output doesn’t have to be collated. This variation sorts a list of indices that refer to single-precision floating-point values (which could be embedded in larger objects) in another table. The indices are in multiples of 32-bits, so they must be multiplied by 4 to get the byte offset of the comparison value.
Now don’t let your eyes glaze over as you look at the vector processing loop from the assembly language version of this routine, because understanding the important parts isn’t hard.
; RBX points to array of values
; RCX is number of elements
; RSI points to incoming array of dword indices
; RDI points to outgoing array of dword indices
; RAX is set to the upper end of the outgoing indices
; RDX is used as a temporary register
; ZMM30 contains the pivot value in all elements
vector_loop:
; load next 16 indices
vmovdqu32 zmm1, zmmword ptr [rsi]
add rsi, 64
; gather comparison values
kxnorw k1, k1, k1 ; set 16 mask bits in K1
vgatherdps zmm2 {k1}, [rbx + 4 * zmm1]
; compare with pivot value
vcmpltps k1, zmm2, zmm30 {sae}
; store indices for values below pivot
vpcompressd [rdi] {k1}, zmm1
; count how many values were stored
kmovw edx, k1
popcnt edx, edx
; move pointers by number of elements stored at
; the beginning and end of output table
lea rax, [rax + 4 * rdx - 64]
lea rdi, [rdi + 4 * rdx]
; store offsets for values >= pivot
knotw k1, k1
vpcompressd [rax] {k1}, zmm1
; check if can process 16 more elements
sub rcx, 16 ; subtract elements we intend to process
jnb vector_loop ; if enough left go process them
AVX-512 vector instructions specify the size of vector elements
The first instruction is VMOVDQU32. This instruction loads 16 dword indices into ZMM1, which is a 512-bit vector register that shares its lower 256 bits with YMM1. It is similar to VMOVDQU, but specifies that the input is a vector of 32-bit integers. In this instance that’s not important, but it would be important for masking, which will be explained in a moment.
Masking with Gather and Scatter
The next AVX-512 instruction uses KXNORW to set the lower 16 bits of the mask register k1. This idiom is similar to how you might subtract a register from itself to get a zero value, but complemented to get 1 bits. Mask registers are used to select which elements of a vector will be operated on. In this case the following VGATHERDPS instruction will be operating on 16 elements, so it needs a mask with 16 bits set. Masking is optional for most AVX-512 instructions, but gather and scatter instructions are special because they clear bits in the mask as values are loaded or stored, which allows them to resume if they are interrupted before they are done. Gather was introduced in AVX2, and these instructions load vector elements based on an address with a vector component, in this case ZMM1. It loads each element from the address that is the sum of the base register (if specified), the vector index element, and the constant offset. Scatter instructions are similar, except they store values instead of loading them. There are also special instructions to check if a scatter instruction would try to write more than one value to the same address. Since only one value can be stored, that would be an error, and likely indicates that there is a dependency that needs to be taken into account.
Embedded Exception Suppression and Rounding Control
The following instruction is VCMPLTPS, which sets the low 16 bits in K1 if the corresponding values that the gather instruction loaded are less than the pivot value in ZMM30. Note that in 64-bit mode EVEX-encoded instructions can use up to 32 vector registers instead of the 16 registers provided for AVX and SSE. This instruction also specifies “{sae}” for “suppress-all-exceptions” which means that any exceptions from the comparison will be suppressed even if they are not masked in the floating-point control register (MXCSR). A comparison does not generate a floating-point result, but many instructions do, and for most AVX-512 instructions where the result might need to be rounded you can specify the rounding mode like this: “{rz-sae}”. The “rz” means round the result toward zero (truncate), but you can also specify rounding up, down or toward the nearest representable value. (When you specify a rounding mode, exceptions will be suppressed.)
Embedded Broadcast
Suppression of exceptions and embedded rounding control can only be specified for full-length vector operations without a memory source operand. There is also an option that can only be specified for memory operands, which is embedded broadcast. Vector calculations often have scalar operands that must be applied to each vector element, such as the pivot value in the example. These values can be loaded into a register using an instruction such as VBROADCASTSS as in the example, but embedded broadcast allows such values to be used directly from memory. For example, if RBP points to the pivot value this instruction could do the comparison:
vcmpltps k1, zmm2, dword bcst [rbp]
The “bcst” keyword signals that the referenced value is a scalar that should be broadcast into a vector for the operation. If the reference is to a list of values from which a vector worth of values is extracted, the traditional memory reference syntax would be used:
vcmpltps k1, zmm2, dword ptr [rbp]
The “bcst” keyword is used to distinguish between the scalar reference and the vector reference, although non-Microsoft tools may do this in other ways.
VPCOMPRESSD and more about masking
The instruction after the comparison is VPCOMPRESSD, which stores only the vector elements corresponding with mask bits that are set. These are the indices that correspond to the values that were less than the pivot value, so they are stored at the head of the output list. VPCOMPRESSD does not clear the mask value, so you don’t have to copy it if you want to use it again. Note that this one instruction does most of the work of building an output list. There is no comparable way to do this using SSE or AVX instructions.
Finishing the loop
The following two instructions KMOVW and POPCNT count the number of elements stored with VPCOMPRESSD so the head and tail pointers to the output buffers can be updated, which is what the next two LEA instructions do. (I am pre-decrementing the output pointer because VCOMPRESSD stores values from low addresses to higher ones.)
Finally, KNOTW inverts the mask bits, and VPCOMPRESSD uses the inverted mask to store the remaining indices at the tail of the output list. Then all that is left is to repeat until there isn’t another full vector worth of values to process.
That’s a total of 14 instructions to process 16 values, with no unpredictable branches. Since you can’t vectorize this loop at all with AVX or SSE instructions, the only comparison is against scalar code, which takes 10 instructions, including an unpredictable branch, to do one value.
The Example in C code
You probably don’t want to use assembly language to write your code. You probably want to code in a high-level language, so let’s look at what this function might look like in C.
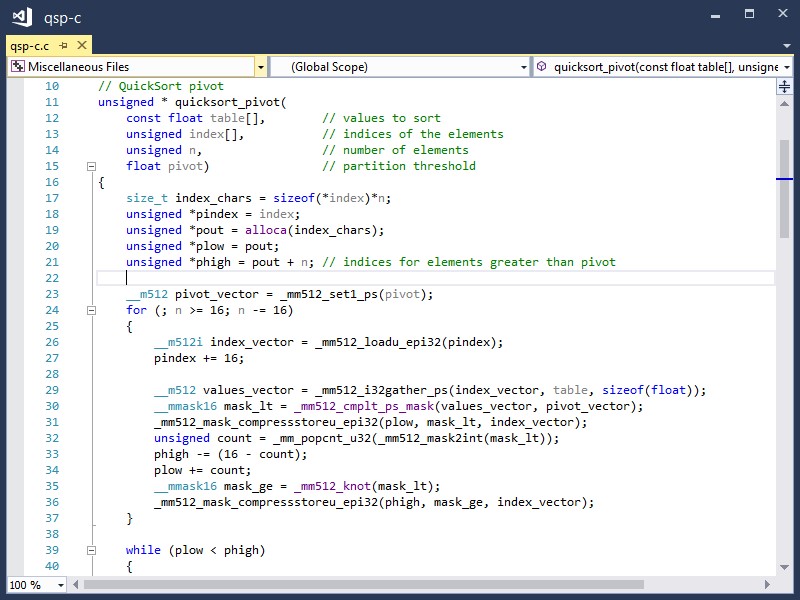
If you compare this with the assembly language version you will see that the vector functions invoked correspond closely with Intel AVX-512 instructions. The _mm512_load_epi32 function corresponds with VMOVDQU32, _mm512_i32gather_ps corresponds with VGATHERDPS, etc. You can map between Intel AVX-512 instructions and intrinsic functions using either the Intel Intrinsics Guide website or Volume 2 of the Intel® 64 and IA-32 Architectures Software Developer’s Manual. The declarations for the Intel AVX-512 functions available in Microsoft Visual C++ are in the zmmintrin.h header, and are included along with other intrinsic function declarations when you include either intrin.h or immintrin.h.
Disassembly of AVX-512 instructions
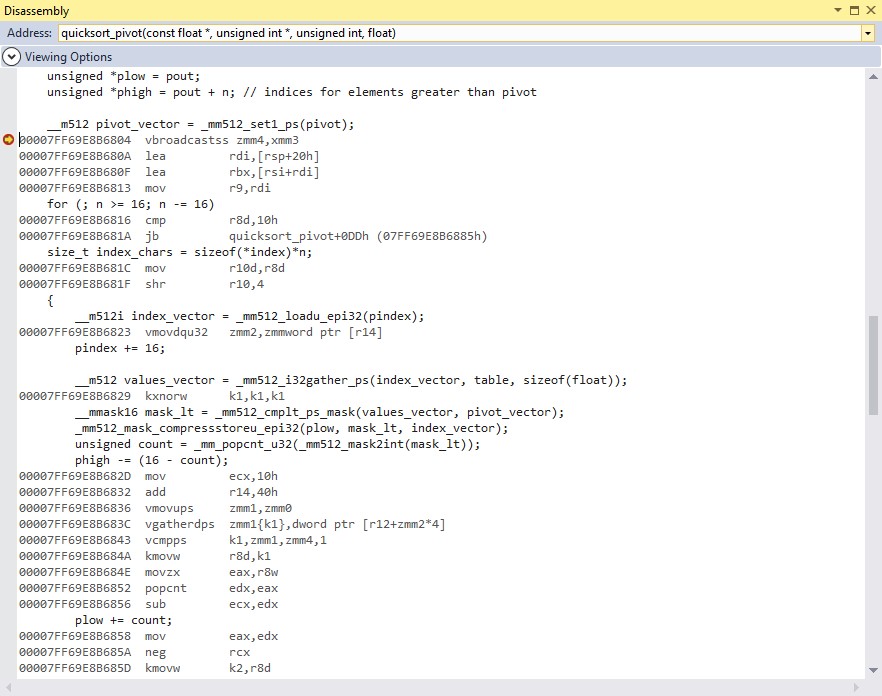
After executing to a breakpoint at the _mm512_set1_ps function above and opening a disassembly window (below) you can see that the C code generates instructions that are similar, but not quite the same as the assembly language version shown above.
Examining Vector Registers
Being able to look at 512-bit vector values is a lot more useful than looking at Intel AVX-512 instructions. Suppose that you want to look at the index_vector and values_vector variables after the _mm512_i32gather_ps function call. You can see these values in a watch window like the one below.
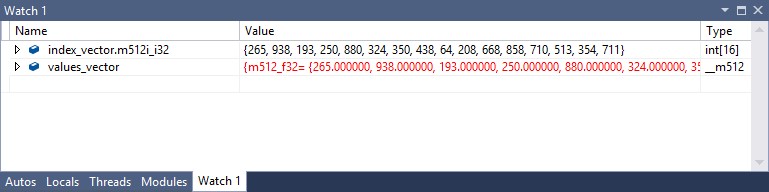
You can set a watch on each of these by right-clicking the variable name, just as you would have done with any other variable. You will notice that the index_vector is further qualified by “.m512i_i32”, while values_vector is not. The __m512i type is a union of vectors with elements that can be integers from 8 to 64 bits, and signed or unsigned, so to be sure you see the actual values you specify the 32-bit elements by clicking on the expansion arrow and selecting the m512i_i32 option. The base element type for __m512 is single-precision floating-point, so selecting a display type isn’t necessary for values_vector. (The floating-point vector values match the index values because that’s the way they were initialized, not because they need to match.) In addition to the watch window, you can view 512-bit vector values in all of the expected places, such as locals and register value windows.
Looking to the Future
We implemented over 1500 Intel AVX-512 intrinsic functions in Microsoft Visual C++ for Visual Studio 2017 version 15.3, and we have more to do. The available functions are mostly for 512-bit vectors or floating-point scalar values. We plan to add more functions for 256-bit and 128-bit vectors and floating-point scalars in an upcoming release, which will more than double the number of AVX-512 functions available. There are also many additional optimizations for the new AVX-512 features that we are planning to roll out over several releases.
You are also important to our plans, so stay tuned! In a future blog post we will dive deeper into Intel AVX-512, and show its performance benefits with examples compiled with Visual Studio. As always, we are interested in your feedback. Post your comments below and requests on Visual Studio UserVoice.
Thanks!
Disclaimers
Example code is provided for illustrative purposes only, and no claim of performance or suitability for any other purpose is implied.
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. Check with your system manufacturer or retailer or learn more at https://www.intel.com.
Intel, the Intel logo, Intel Core, Intel Xeon, and Intel Xeon Phi are trademarks or registered trademarks of Intel Corporation in the U.S. and/or other countries. *Microsoft, Visual Studio, and Visual C++ are trademarks or registered trademarks of Microsoft Corporation in the U.S. and/or other countries. Other names and brands may be claimed as the property of others. © 2017 Intel Corporation
 Light
Light Dark
Dark
0 comments