
Rebuilding Intellisense
Hi, my name is Boris Jabes. I’ve been working on the C++ team for over 4 years now (you may have come across my blog, which has gone stale…). Over the past couple of years, the bulk of my time has been spent on re-designing our IDE infrastructure so that we may provide rich functionality for massive code bases. Our goal is to enable developers of large applications that span many millions lines of code to work seamlessly in Visual C++. My colleagues Jim and Mark have already published a number of posts (here, here and here) about this project and with the release of Visual Studio 2010 Beta 1 this week; we’re ready to say a lot more. Over the next few weeks, we will highlight some of the coolest features and also delve into some of our design and engineering efforts.
In this post, I want to provide some additional details on how we built some of the core pieces of the C++ language service, which powers features like Intellisense and symbol browsing. I will recap some of the information in the posts I linked to above but I highly recommend reading the posts as they provide a ton of useful detail.
The Problem
Without going into too much detail, the issue we set about to solve in this release was that of providing rich Intellisense and all of the associated features (e.g. Class View) without sacrificing responsiveness at very high scale. Our previous architecture involved two (in)famous components: FEACP and the NCB. While these were a great way to handle our needs 10+ years ago, we weren’t able to scale these up while also improving the quality of results. Multiple forces were pulling us in directions that neither of these components could handle.
1. Language Improvements. The C++ language grew in complexity and this meant constant changes in many places to make sure each piece was able to grok new concepts (e.g. adding support for templates was a daunting task).
2. Accuracy & Correctness. We need to improve accuracy in the face of this complexity (e.g. VS2005/2008 often gets confused by what we call the “multi-mod” problem in which a header is included differently by different files in a solution).
3. Richer Functionality. There has been a ton of innovation in the world of IDEs and it’s essential that we unlock the potential of the IDE for C++ developers.
4. Scale. The size of ISV source bases has grown to exceed 10+ million lines of code. Arguably the most common (and vocal!) piece of feedback we received about VS2005 was the endless and constant reparsing of the NCB file (this reparsing happened whenever a header was edited or when a configuration changed).
Thus, the first step for us in this project was to come up with a design that would help us achieve these goals.
A New Architecture
Our first design decision involved both accuracy and scalability. We needed to decouple the Intellisense operations that require precise compilation information (e.g. getting parameter help for a function in the open cpp file) from the features that require large-scale indexes (e.g. jumping to a random symbol or listing all classes in a project). The architecture of VS2005 melds these two in the NCB and in the process lost precision and caused constant reparsing, which simply killed any hope of scaling. We thus wanted to transition to a picture like this (simplified):
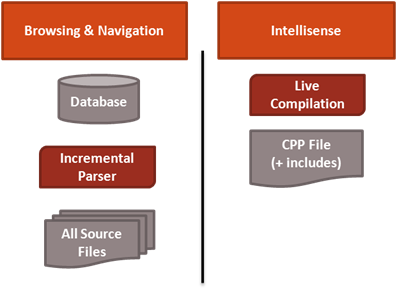
At this point, we needed to fill in the blanks and decide how these components should be implemented. For the database, we wanted a solution that could scale (obviously) and that would also provide flexibility and consistency. Our existing format, the NCB file, was difficult to modify when new constructs were added (e.g. templates) and the file itself could get corrupted leading our users to delete it periodically if things weren’t working properly in the IDE. We did some research in this area and decided to use SQL Server Compact Edition, which is an in-process, file-oriented database that gives us many of the comforts of working with a SQL database. One of the great things of using something like this is that gave us real indexes and a customizable and constant memory footprint. The NCB on the other hand contained no indexes and was mapped into memory.
Finally, we needed to re-invent our parsers. We quickly realized that the only reasonable solution for scalability was to populate our database incrementally. While this seems obvious at first, it goes against the basic compilation mechanism of C++ in which a small change to a header file can change the meaning of every source file that follows, and indeed every source file in a solution. We wanted to create an IDE where changing a single file did not require reparsing large swaths of a solution, thus causing churn in the database and even possibly locking up the UI (e.g. in the case of loading wizards). We needed a parser that could parse C++ files in isolation, without regard to the context in which they were included. Although C++ is a “context sensitive” language in the strongest sense of the word, we were able to write a “context-free” parser for it that uses heuristics to parse C++ declarations with a high degree of accuracy. We named this our “tag” parser, after a similar parser that was written for good old C code long ago. We decided to build something fresh in this case as this parser was quite different than a regular C++ parser in its operation, is nearly stand-alone, and involved a lot of innovative ideas. In the future, we’ll talk a bit more about how this parser works and the unique value it provides.
With the core issue of scalability solved, we still needed to build an infrastructure that could provide highly accurate Intellisense information. To do this, we decided to parse the full “translation unit” (TU) for each open file in the IDE editor* in order to understand the semantics of the code (e.g. getting overload resolution right). Building TUs scales well – in fact, the larger the solution, the smaller the TU is as a percentage of the solution size. Finally, building TUs allows us to leverage precompiled header technology, thus drastically reducing TU build times. Using TUs as the basis for Intellisense would yield highly responsive results even in the largest solutions.
Our requirements were clear but the task was significant. We needed rich information about the translation unit in the form of a high-level representation (e.g. AST) and we needed it available while the user was working with the file. We investigated improving on FEACP to achieve this goal but FEACP was a derivation of our compiler, which was not designed for this in mind (see Mark’s post for details). We investigated building a complete compiler front-end designed for this very purpose but this seemed like an ineffective use of our resources. In the 1980s and 1990s, a compiler front-end was cutting-edge technology that every vendor invested in directly but today, innovation lies within providing rich value on top of the compiler. As a result there has been a multiplication of clients for a front-end beyond code generation and we see this trend across all languages: from semantic colorization and Intellisense to refactoring and static analysis. As we wanted to focus on improving the IDE experience, we identified a third and final option: licensing a front-end component for the purposes of the IDE. While this may seem counter-intuitive, it fit well within our design goals for the product. We wanted to spend more resources on the IDE, focusing on scale and richer functionality and we knew of a state-of-the-art component built by the Edison Design Group (commonly referred to as EDG). The EDG front-end fit the bill as it provides a high-level representation chock-full of the information we wanted to build upon to provide insight in the IDE. The bonus is that already handles all of the world’s gnarly C++ code and their team is first in line to keep up with the language standard.
With all these pieces in place, we have been able to build some great new end-to-end functionality in the IDE, which we’ll highlight over the coming weeks. Here’s a sneak peek at one we’ll talk about next week: live error reporting in the editor.
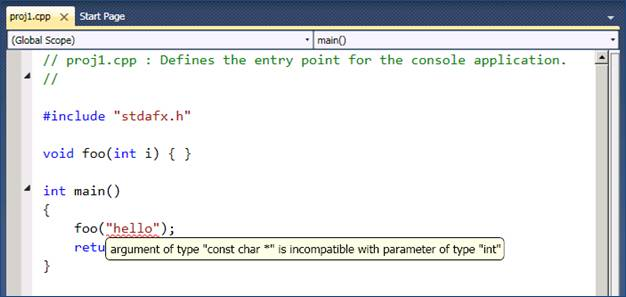
* – We optimize by servicing as many open files as possible with a single translation unit.
 Light
Light Dark
Dark
0 comments