
DirectX 12 Multiadapter: Lighting up dormant silicon and making it work for you
Are you one of the millions of PC users with a laptop or a desktop system with an integrated GPU as well as a discrete GPU? Before Windows 10 and DirectX 12, all the performance potential from the second GPU goes unused. With DirectX 12 and Windows 10, application developers can use every GPU on the system simultaneously!
Are you an elite power gamer with multiple graphics cards? Well, by giving the applications direct control over all of the hardware on the system, applications can optimize more effectively for the ultra-high end, squeezing even more performance out of the most powerful systems available today and in the future.
We’re calling this DX12 feature “Multiadapter”, and applications can use it to unlock all that silicon that would otherwise be sitting dormant doing nothing.
At //build 2015 we both announced the Multiadapter feature and showed several examples of how it can be used.
Square Enix and DirectX 12 Multiadapter
Square Enix created a demo called “WITCH CHAPTER 0 [cry]” running on DirectX 12 and we were very happy to be able to show it at //build 2015.
With about 63 million polygons per scene and 8k by 8k textures, the demo showed the unprecedented level of detail you can achieve with DirectX 12 and Windows 10.

Square Enix’s DirectX 12 demo rendering in real-time on stage at //build 2015
The demo utilized four NVIDIA GeForce GTX Titan X cards enabling Square Enix to achieve extremely realistic cinematic level rendering; only instead of pre-rendered content, this was being rendered in real-time!
This demonstrated the upper end of what’s possible using multiple high power GPUs and DirectX 12.
Take a look at the live demo video from April 30th’s Keynote Presentation.
Now let’s take a look at how DirectX 12’s Multiadapter is also designed to extract all the power from a variety of mixed power hardware.
Explicit Multiadapter control in Unreal Engine 4
We used Epic Games’ DX12 Unreal Engine 4 to split the rendering workload across an integrated Intel GPU and a discrete NVIDIA GPU to showcase how it is possible to use two disparate GPUs simultaneously to maximize performance.
To show how this extra boost can help gamers, we set up a race between a single discrete NVIDIA GPU and a Multiadapter configuration consisting of the same single discrete GPU + an integrated Intel GPU. In this race, each configuration rendered 635 frames of the UE4 Elemental demo as quickly as it was able to.
The results below show that the Multiadapter configuration manages to beat the single adapter configuration in a race to 635 frames. At the end of the benchmark, we can calculate the overall fps where Multiadapter comes out as the definitive winner.

Multiadapter already beating single adapter at ~6 seconds
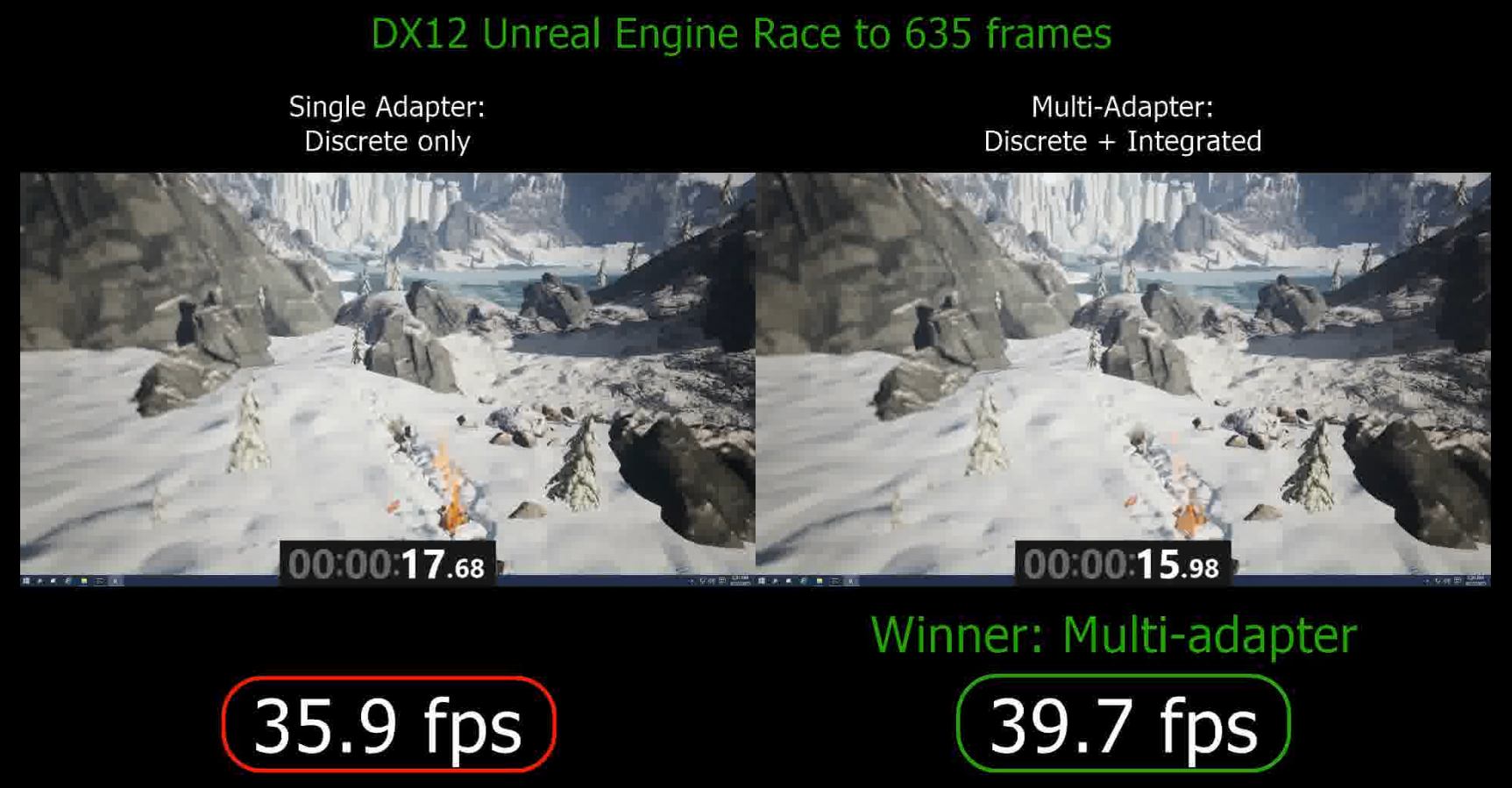
Final results of the fixed-frame-count benchmark
How does it work?
We recognized that most mixed GPU systems in the world were not making the most out of the hardware they had. So in our quest to maximize performance, we set out to enable separable and contiguous workloads to be executed in parallel on separate GPUs. One such example of separable workloads is postprocessing.
Virtually every game out there makes use of postprocessing to make your favorite games visually impressive; but that postprocessing work doesn’t come free. By offloading some of the postprocessing work to a second GPU, the first GPU is freed up to start on the next frame before it would have otherwise been able to improving your overall framerate.
Analyzing the results
The below image shows the real workload timeline of the Intel and NVIDIA GPUs (to scale). You can see how the workload that would normally be on the NVIDIA GPU is being executed on the Intel GPU instead.
In the demo, we even make use of DirectX 12’s Multiengine feature to complement the Multiadapter feature. You can see that the copy operations on NVIDIA’s copy engine execute in parallel with the NVIDIA 3D engine operations improving performance even more.
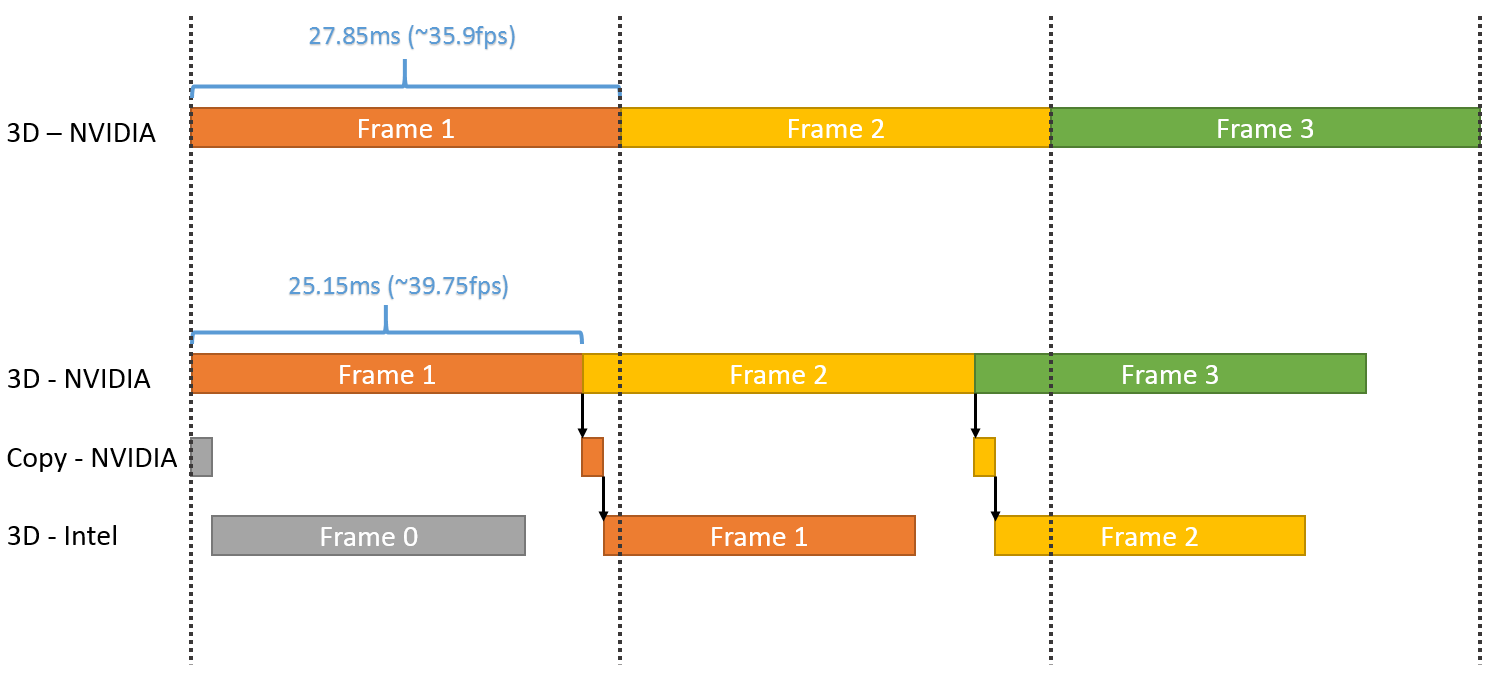
GPU workload timeline (to scale)
Taking a look at the Intel workload, we can see that we still have some unused GPU time that we can take advantage of. The final GPU utilization results were:
- NVIDIA: ~100% utilization on average
- Intel: ~70% utilization on average
Looking to the future, this tells us that the opportunity exists to extract even more performance out of the demo hardware.
For more details, take a look at Max McMullen’s talk at //build 2015 (when available):
https://channel9.msdn.com/Events/Build/2015/3-673
You can also take a look at a video of the actual benchmark here:
https://channel9.msdn.com/Blogs/DirectX-Developer-Blog/DirectX-12-Multiadapter-Unreal-Engine-4
Opening doors to new possibilities
DirectX 12 already helps you maximize performance by bringing apps closer to the metal. At //build 2015, we have shown you a glimpse of the performance possibilities with DirectX 12 and how it can light up that precious but dormant silicon already in your machine using Multiadapter.
The fine grained-control over ALL of the hardware in the system offered by DirectX 12 gives game developers the power to use techniques that were simply not possible in DirectX 11. Our Multiadapter demos only scratch the surface of what creative game developers can do now that they have the ability to directly use ALL of the graphics hardware in the system, even if such hardware has different capabilities and is from different manufacturers.
 Light
Light Dark
Dark
0 comments