
Windows Command-Line: Backgrounder
This is the first of a series of posts in which we’ll explore all things command-line – from the origins of the command-line and the evolution of the terminal, to what we’re doing to overhaul and modernize the Windows Console & command-line in future Windows releases.
Posts in the “Windows Command-Line” series
Note: This chapter list will be updated as more posts are published:
- Backgrounder [this post]
- The Evolution of the Windows Command-Line
- Inside the Windows Console
- Introducing the Windows Pseudo Console (ConPTY)
- Unicode and UTF-8 Output Text Buffer
Whether you’re a seasoned veteran, or are new to computing (welcome all), we hope you’ll find these posts interesting, informative, and fun. So, grab a coffee and settle in for a whirlwind tour through the origins of the command-line!
A long time ago in a server room far, far away …
From the earliest days of electronic computing, human users needed an efficient way to send commands and data to the computer, and to be able to see the results of their commands/calculations.
One of the first truly effective human-computer interfaces was the Tele-Typewriter – or “Teletype”. Teletypes were electromechanical machines with keyboards for user input, and an output device of some kind – printers in the early days, screens in more recent devices – which displayed output to the user.
The characters that the operator typed were buffered locally and sent from the Teletype to a nearby mini or mainframe computer as a series of signals along an electrical cable (e.g. RS-232 cable) at 10 characters per second (110 baud/bits per second – bps):

Note: David Gesswein’s awesome PDP-8 site has a lot more information on the ASR33 (and the PDP-8 and associated tech), including photos, videos, etc. The program running on the computer would receive the typed characters, decide what to do with them, and might optionally, asynchronously send characters back to the Teletype. The Teletype would print /display the returned characters for the operator to read and respond to.
In the years that followed, the technology improved, boosting transmission speeds up to 19,200bps, and replacing the noisy and expensive-to-operate printer with a Cathode Ray Tube (CRT) display most often associated with computer terminals of the ‘80s and ‘90s, including the ubiquitous DEC VT100 terminal:

While the technology improved, this model of the terminal sending characters to programs running on the computer, and the computer responding with text output to the user, remained, and remains today, as the fundamental interaction model for all command-lines & terminals on all platforms!
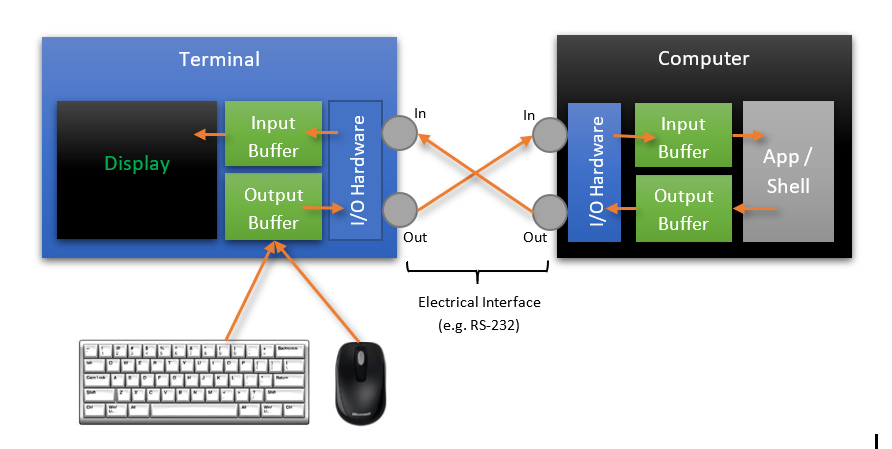
Part of the elegance of this model is the fact that each component part of the system remained simple and consistent: The keyboard emitted characters which were buffered for output as electrical signals to the connected computer. The output device simply wrote the characters emitted by the connected computer onto the display technology (e.g. paper/screen).
And because each stage of the system communicated with the next stage by simply passing streams of characters, it is a relatively simple process to introduce different communications infrastructure, adding, for example, modems which allow streams of input and output characters to be sent over great distances via telephone lines.
Text Encoding
It’s important to remember that terminals and computers communicate via streams of characters: When a key on the terminal’s keyboard is pressed, a value representing the typed character is sent to the connected computer. Press the ‘A’ key and the value 65 (0x41) is sent. Press the ‘Z’ key and the value 90 (0x5a) is sent.
7-bit ASCII Text Encoding
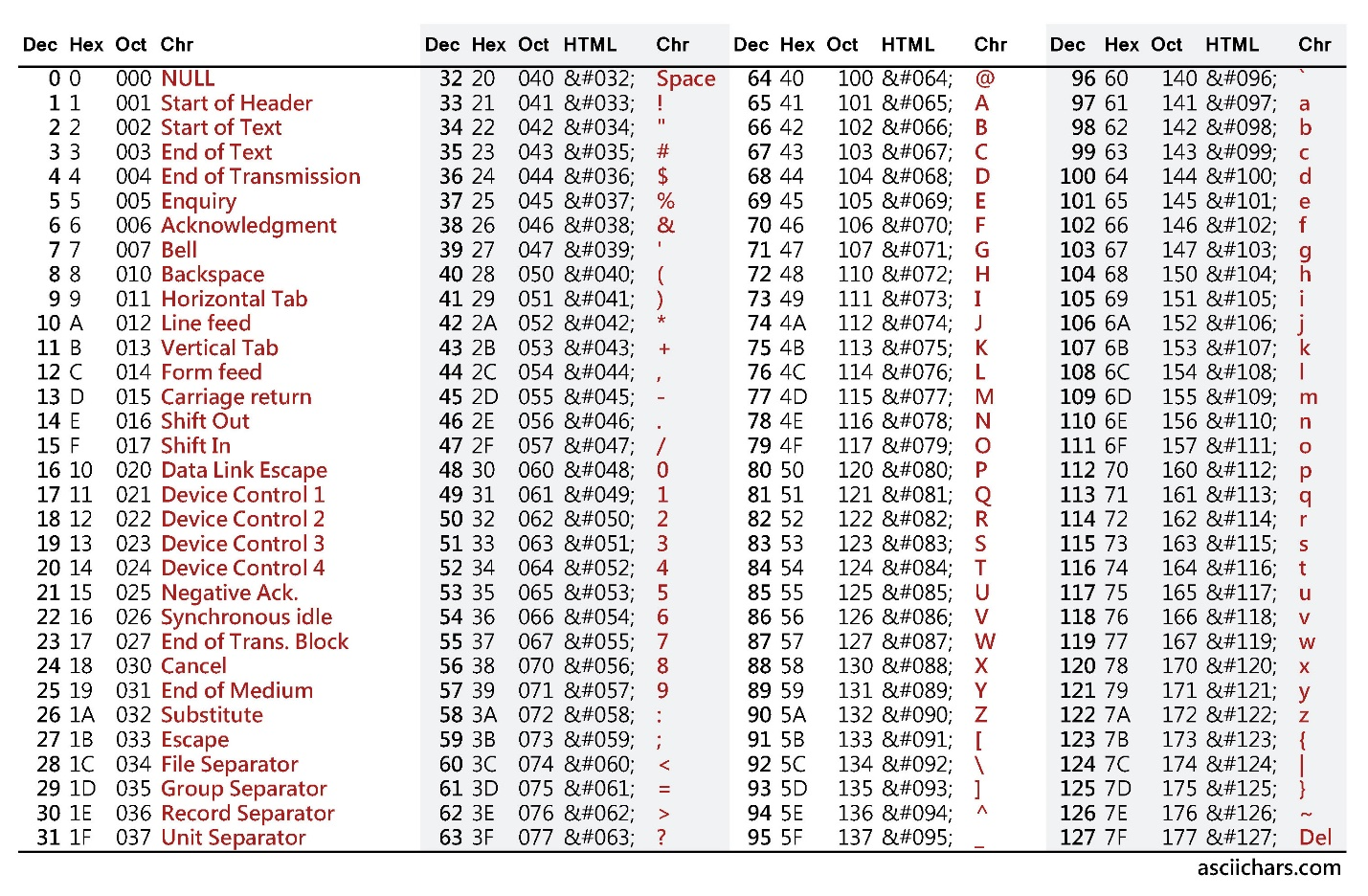
The list of characters and their values is defined in the American Standard Code for Information Interchange (ASCII) standard (ISO/IEC 646 / ECMA-6) “7-bit coded character set” which defines
- The 128 values that represent the printable Latin A-Z (65-90), a-z (97-122), 0-9 (48-57)
- Many common punctuation characters
- Several non-displayable device control codes (0-31 & 127)
When 7 bits aren’t enough – Code-Pages
However, 7 bits do not provide enough space to encode many diacritics, punctuation, and symbols used in other languages and regions. So, with the addition of an additional bit, the ASCII character table can be extended with additional sets of “Code-Pages” that define characters 128-255 (and may re-define several other non-printable ASCII characters).
For example, IBM defined code-page 437 which added several block characters like ╫ (215) and ╣(185) and symbols including π (227) and ± (241), and redefined printable characters for the normally non-printable characters 1-31:

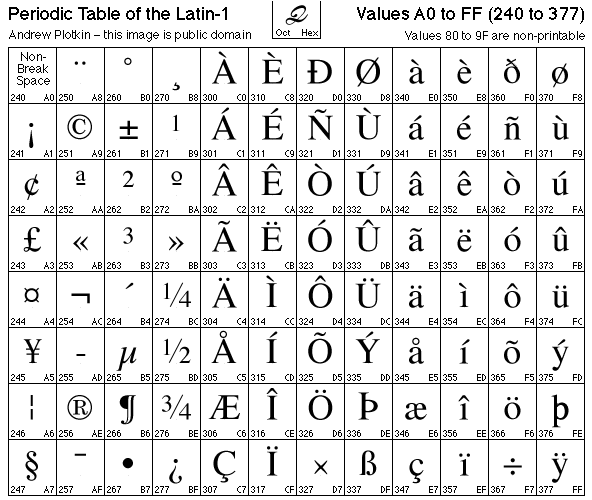
The Latin-1 code-page defines many characters and symbols used by Latin-based languages:
Many command-line environments and shells allow the user to change code-pages, which causes the terminal to display different characters (depending on the available fonts), especially for characters with a value of 128-255. However, note that the wrong code-page can cause the displayed text to look “mojibaked”. And, yes, “mojibake” is a real term! Who knew? 😉
When 8 bits aren’t enough – Unicode
While code-pages provided a solution for a while, they have many shortcomings, including the fact that they do not allow text for multiple code-pages/languages to be displayed at the same time. So, a new encoding was required that would allow the accurate representation of every character and script of every language known to man, with plenty of room to spare! Enter, Unicode.
Unicode is an international-standard (ISO/IEC 10646) that (currently) defines 137,439 characters covering 146 modern and historic scripts, plus many symbols and glyphs including the many emoji in widespread use across practically every app, platform, and device 😊 The Unicode standard is regularly updated, adding additional writing systems, adding/correcting emoji symbols, etc.

When many-bytes are too many – UTF-8!
The space required to represent all the symbols defined by Unicode, especially complex characters, emoji, etc. could be very large and may require several bytes to uniquely and systematically define every displayable character.
Thus, several encodings have been developed that trade storage space vs. time/effort required to encode/decode the data: UTF-32 (4 bytes / char), UTF-16/UCS-2 (2 bytes / char), and UTF-8 (1-4 bytes / char) are among the most popular Unicode encodings.
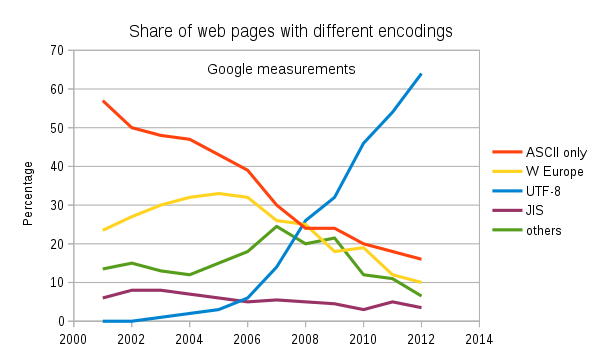
Thanks in large part to its backward-compatibility with ASCII and its storage efficiency, UTF-8 has emerged as the most popular Unicode encoding on the internet, and has seen explosive adoption ever since 2008 when it overtook ASCII and other popular encodings:
So, while most terminals started by supporting 7-bit and then 8-bit ANSI text, most modern terminals support Unicode/UTF-8 text.
So, what IS a Command Line, and what is a Shell?
The “Command-Line” or CLI (Command Line Interface/Interpreter) describes the most fundamental mechanism through which a human operates a computer: A CLI accepts input typed-in by the operator and performs the requested commands.
For example, echo Hello writes the text “Hello” to the output device (e.g. screen). dir (Cmd) or ls (PowerShell/*NIX) lists the contents of the current directory, etc.
In earlier computers, the commands available to the operator were often relatively simple, but operators quickly demanded more and more sophistication, and the ability to write scripts to automate mundane or repetitive, or complex tasks. Thus command-line processors grew in sophistication and evolved into what are now commonly known as command-line “shells”.
In UNIX/Linux the original UNIX shell (sh) inspired a plethora of shells including the Korn shell (ksh), C shell (csh) and Bourne Shell (sh), which itself begat the Bourne Again Shell (bash), etc.
In Microsoft’s world:
- The original MS-DOS (command.com) was a relatively simple (if quirky) command-line shell
- Windows NT’s “Command Prompt” (cmd.exe) was designed to be compatible with legacy MS-DOS command.com/batch scripts, and added several additional commands for the new, more powerful operating system
- In 2006, Microsoft released Windows PowerShell
- PowerShell is a modern object-based command-line shell inspired by the features of other shells, and was built upon and incorporates the power of the .NET CLR & .NET Framework
- Using PowerShell, Windows users can control, script, and automate practically every aspect of a Windows machine, group of Windows machines, network, storage systems, databases, etc.
- In 2017, Microsoft open-sourced PowerShell and enabled it to run on macOS and many flavors of Linux and BSD!
- In 2016, Microsoft introduced Windows Subsystem for Linux (WSL)
- Enables genuine unmodified Linux binaries to run directly on Windows 10
- Users install one or more genuine Linux distros from the Windows Store
- Users can run one or more distro instances alongside one another and existing Windows applications and tools
- WSL enables Windows users to run all their favorite Windows tools and Linux command-line tools side-by-side without having to dual-boot or utilize resource-hungry Virtual Machines (VM’s)
We’ll revisit Windows command-line shells in the future, but for now know that there are various shells, and they accept commands typed by the user/operator, and perform a wide variety of tasks as required.
The Modern Command-Line
Modern-day computers are vastly more powerful than the “dumb terminals” of yesteryear and generally run a desktop Operating System (e.g. Windows, Linux, macOS) sporting a Graphical User Interface (GUI). These GUI environments allow multiple applications to run simultaneously within their own “window” on the user’s screen, and/or invisibly in the background.

The clunky, hulking electromechanical Teletype machines have been replaced with modern terminal applications that run within an on-screen window, but still perform the same essential functions as the terminal devices from the past.
Similarly, command-line applications, to which terminal apps are connected, work in the same way that they always did: They receive input characters, decide what to do with those characters, (optionally) do work, and may emit text to be displayed to the user.
But instead of communicating via slow TTY serial communications lines, terminal apps and command-line applications on the same machine communicate via very high-speed, in-memory Pseudo Teletype (PTY) communications.
Of course, while modern terminals primarily communicate with command-line applications running locally, they can also communicate with command-line applications running on other machines on the same network, or even remote machines running on the other side of the world via the internet. This “remoting” of the command-line experience is a powerful tool which is popular on every platform, especially *NIX platforms.
So, where are we?
In this post, we took a historical tour through the most important aspects of the command-line that are common to both *NIX and Windows: Terminals, Shells, Text & text encoding.
It will be important to remember the information above as we continue to our next post where we’ll learn more about the Windows Console, what it is, how it works, how it differs from *NIX terminals, where it has challenges, and what we’re doing to remedy these challenges, and bring the Windows Console into the 21st Century!
Stay Tuned – more to come!!
 Light
Light Dark
Dark
1 comment
Great post about the history of terminals!
So do the whole series of this blog about terminals. Thank you very much! 🙂