
Implement automatic failover with load balanced sets to ensure high availability of VM workloads in Azure where only one VM can respond to requests at a time
NOTE: I implemented the below example using the Azure Government cloud, however this technique will work exactly the same using the public Azure cloud. If you are using the public Azure cloud take a look at our Application Gateway offering, it does layer 7 load balancing and supports sticky sessions (http://azure.microsoft.com/en-gb/services/application-gateway/)
So you have an application that you want to move to the cloud. You have heard that you have to run at least two virtual machines behind a load balancer to get an SLA, however your application is not architected to run behind a load balancer. Perhaps it keeps session state on the web server and you aren’t ready to go through the process of externalizing it. Perhaps it is one of a million of other items of technical debt that are concerning you.
In this article I am going to describe a technique to overcome this, however in the long run I highly recommend resolving the architectural issues in the application that are preventing you from running it behind a load balancer in a traditional manner as this technique is a workaround and doesn’t allow you to take full advantage of the computing power you are paying for. That said it can provide a quick time to market for lift and shift applications with minor code changes.
Before we get started take a look at my other article on how I set up my 3 VMs and wrote a little client app to showcase the load balancing and failover behavior of load balanced sets. http://blogs.msdn.com/b/azuregov/archive/2015/06/15/configuring-high-availability-for-iaas-virtual-machines.aspx
If we are going to want to run two copies of our application but route all the traffic to one of them, we have to figure out a way to automatically elect one of them as the leader and then keep the load balancer in the loop as to who the leader is so it can route traffic accordingly.
The Patterns and Practices team has written a great article on the Leader Election Design Pattern https://msdn.microsoft.com/en-us/library/dn568104.aspx. The article also includes a code sample that takes advantage of blob leases in Azure storage “to provide a mechanism for implementing a shared distributed mutex.” With that problem solved, we can keep the load balancer notified by placing this code behind a custom probe (more info here http://blogs.msdn.com/b/piyushranjan/archive/2014/01/09/custom-probe-for-iaas-load-balanced-sets-in-windows-azure-and-acl-part-1.aspx). By combining these two techniques we can achieve the mission at hand.
The first step is to add the code to our application. To do this I need two bits, first lets borrow the BlobLeaseManager class from the P&P sample (https://code.msdn.microsoft.com/Leader-Election-Code-ad269c3e/sourcecode?fileId=108418&pathId=1652985471). Just copy this entire file into your project.
Next we will need to write our custom endpoint. You can grab the code from my proof of concept here:
In the above sample you can see that I am creating a single action on my controller for the load balancers probe to hit. The code is pretty self-explanatory, but the basic idea is that if we can get/renew the lease we return a 200 OK to the load balancer, however if another node has the lease then we return a Service Unavailable message to the load balancer, thus instructing the load balancer not to route traffic to this node.
The next step is to configure the load balancer to hit our custom endpoint. As you can see below the endpoint is configured tell the load balancer to interrogate HTTP on port 80, and specifically ask for the URI that we just wrote the code for..
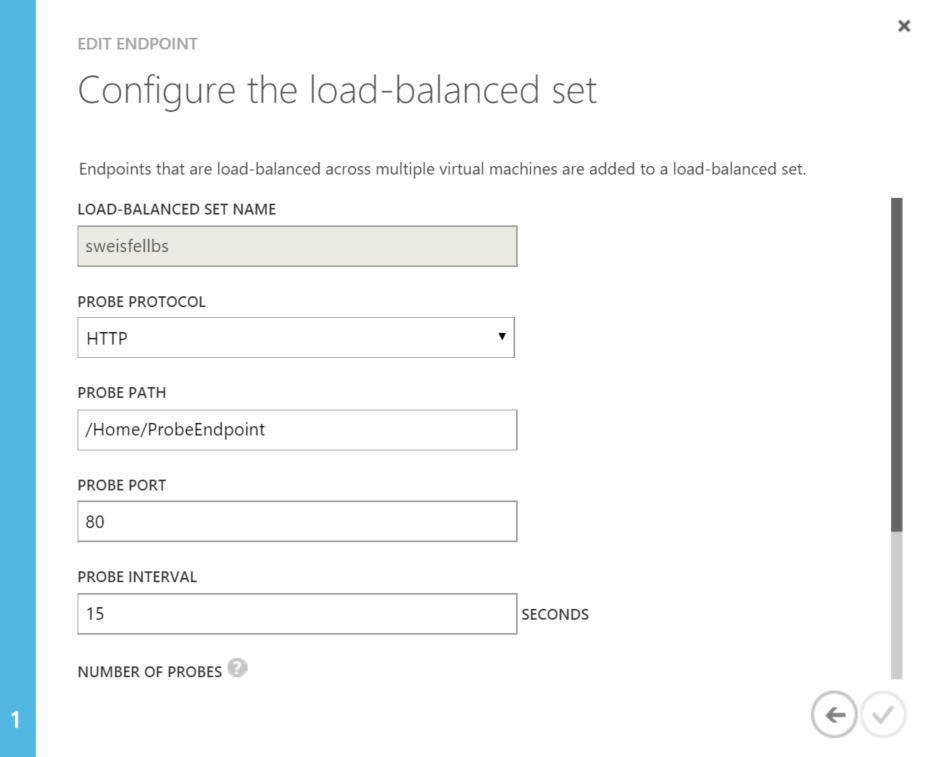
That is, it. When you run this you should see that all responses are served by only one of the machines in your load balanced set. Here is a screen shot from my little test app. Here you can see that all requests were returned by machine 02.
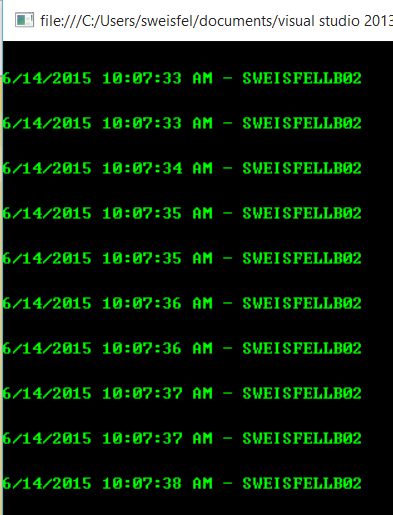
I can simulate a failure by turning off IIS on that machine, lets see what happens. In this case after a brief outage server 03 was elected as the new leader and started responding to requests.

Why did it take just over 1 minute to failover? Well if you look at the code you copied from P&P on line 74 they are acquiring the lease for 60 seconds. Compound that with the fact that our load balancer only probes once every 15 seconds. During the failover we need to wait for the lease to expire before another node can grab it.
While this technique ensures that the load balancer will only route traffic to one of your nodes at a given time, when a failover does occur, your users will lose session and there will be a brief outage. However now you have control of how that failover happens.
 Light
Light Dark
Dark
0 comments