Columnstore Index Performance: Rowgroup Elimination
As described in Column Elimination , when querying columnstore index, only the referenced columns are fetched. This can potentially reduce IO/memory footprint of analytics queries significantly and speed up the query performance. While this is good, the other challenge with columnstore index is how to limit the number of rows to be read to process the query. As described in the blog why no key columns , the columnstore index has no key columns as it would have been prohibitively expensive to maintain the key order. Without ordered rows, the analytics query performance will have significant performance impact if the full scan of a columnstore index containing billions of rows was needed to apply range predicates. For example, if a FACT table stores sales data for the last 10 years and you are interested in the sales analytics for the current quarter, it will be more efficient if SQL Server scans the data only for the last quarter instead of scanning the full table, a reduction of 97.5% (1 our 40 quarters) both in IO and query processing. This is easy with rowstore where you can just create a clustered btree index on the SalesDate and leverage it to scan only the rows for the current quarter. You may wonder how we can do it with columnstore index?
Well, one way to get around this is to partition the table by quarter or week or day which can then reduce the number of rows to be scanned significantly by limiting the scan the partition(s). While this works but what would happen if you need to filter the data by region within a large partition? Scanning the full partition can also be slow. With rowstore, you could partition the table by quarter and keep the data sorted within the partition by creating a clustered index on region. This is just one example but you get the idea that unordered data within columnstore index may cause scanning larger number of rows than necessary. In SQL Server 2016, you can potentially address this using NCI but only if the number of qualifying rows is small.
Columnstore index solves this issue using rowgroup elimination. You may wonder what exactly is a rowgroup? The picture below shows how data is physically organized both for clustered and nonclustered columnstore indexes. A rowgroup represents a set of rows, typically 1 million, that are compressed as a unit. Each column within a rowgroup is compressed interpedently and is referred to as a segment. SQL Server stores the min/max value for each segment as part of the metadata and uses this to eliminate any rowgroups that don’t meet the filter criteria.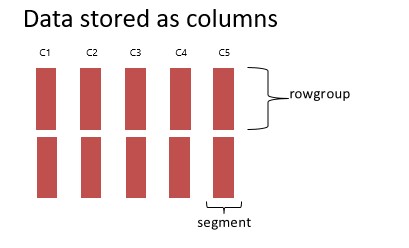
In the context of rowgroup elimination, let us revisit the previous example with sales data
- You may not even need partitioning to filter the rows for the current quarter as rows are inserted in the SalesDate order allowing SQL Server to pick the rowgroups that contain the rows for the requested date range using the Min/Max date ranges in the relevant column for each rowgroup. Since this information is stored as metadata, rowgroups are eliminated without the need to bring them into memory.
- If you need to filter the data for a specific region within a quarter, you can partition the columnstore index at quarterly boundary and then load the data into each partition after sorting on the region. If the incoming data is not sorted on region, you can follow the steps (a) switch out the partition into a staging table T1 (b) drop the clustered columnstore index (CCI) on the T1 and create clustered btree index on T1 on column ‘region’ to order the data (c) now create the CCI while dropping the existing clustered index. A general recommendation is to create CCI with DOP=1 to keep the prefect ordering.
SQL Server provides information on the number of rowgroups eliminated as part of query execution. Let us illustrate this using an example with two tables ‘CCITEST’ and CCITEST_ORDERED’ where the second table is sorted on one of the columns using the following command
create clustered columnstore index ccitest_ordered_cci on ccitest_ordered WITH (DROP_EXISTING = ON, MAXDOP = 1)
The following picture shows how the data is ordered on column 3. You can see that data for column_id=3 is perfectly ordered in 'ccitest_ordered'.
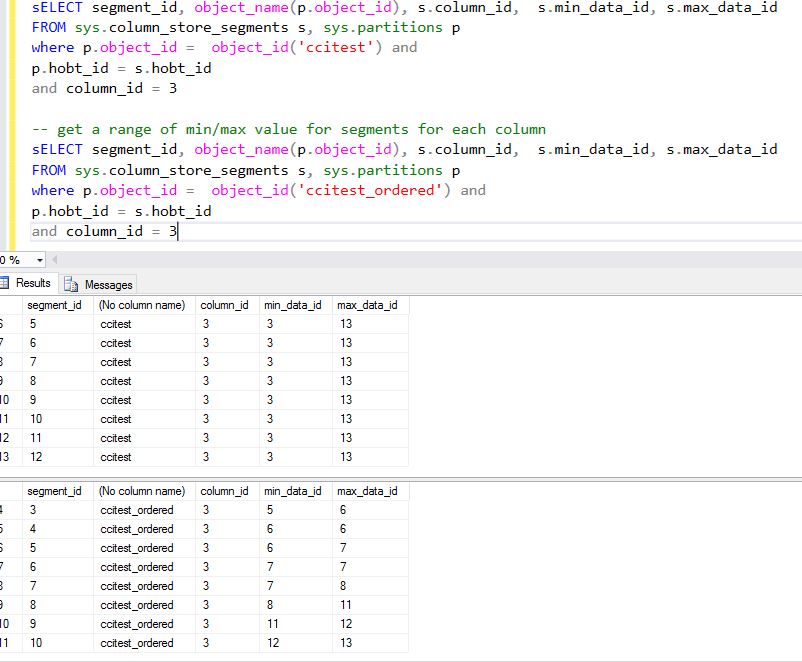
Now, we run a query that uses column with column_id=3 as a range predicate as shown below. For CCITEST table, the data was not sorted on the column OrganizationKey, no rowgroup was skipped but for the table CCITEST_ORDERED, 10 rowgroups were skipped as SQL Server used the Min/Max range to identify rowgroups that qualify.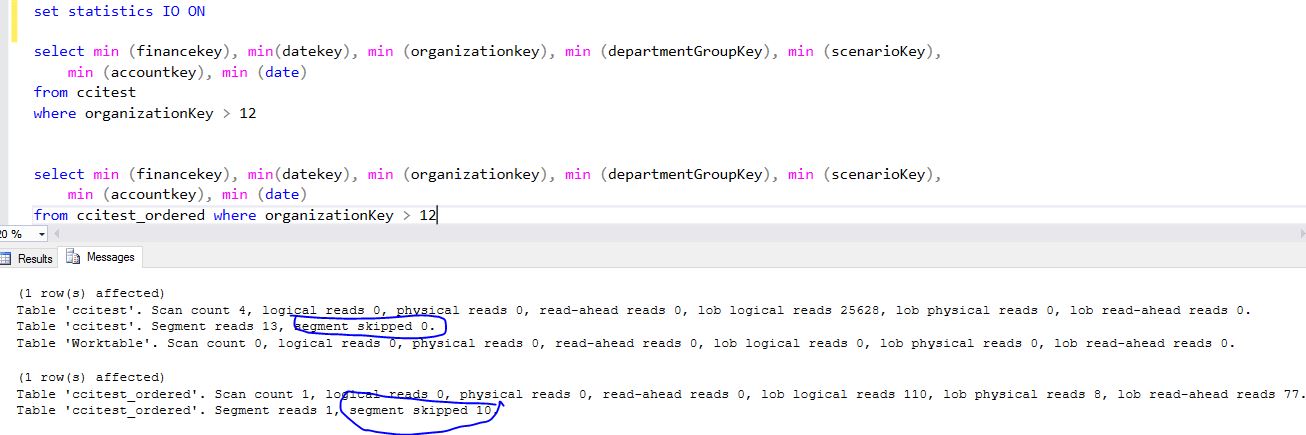
You may wonder why it says ‘segment’ skipped and not ‘rowgroups’ skipped? Unfortunately, this is a carryover from SQL Server 2012 with some mix-up of terms. When running analytics queries on large tables, if you find no or only a small percentage of rowgroups were skipped, you should look into why and explore opportunities to address if possible.
One thing to note is that for a partitioned table, if a partition is eliminated by the query execution engine, then any rowgroups skipped because of that are not included in the count above.
Thanks
Sunil