Columnstore Index Performance: Column Elimination
Data in Columnstore index https://msdn.microsoft.com/en-us/library/gg492088.aspx is organized as columns. This organization allows each column to be stored and accessed independently of other columns unlike rowstore where all columns in a row are stored together. Using columnstore, SQL Server can execute the query retrieving only the columns referenced in the query. For example, if a FACT table has 50 columns and the query only accesses 5 columns, only those columns would need to be fetched. Assuming have equal length, clearly a radical assumption, accessing data through columnstore index will reduce IO by 90% in addition to the significant data compression achieved with columnstore index. Since data is read compressed in SQL Server memory, you get the similar savings for SQL Server memory.
Let us consider a simple example to illustrate these points. I have created the following two tables, one (CCITEST) with clustered columnstore index and other (CITEST) with a regular clustered index as shown in the picture below 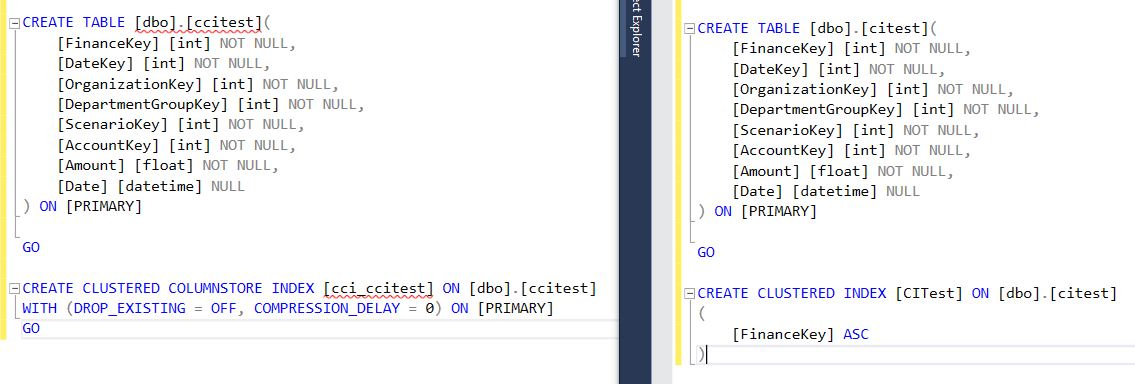
Now, I inserted identical 11 million rows each into these tables. Now, I will run the same set of queries, one that aggregates all the columns and one that aggregates only one column. These queries are run on both of these tables.
The picture below shows the logical IOs done on rowstore table and as expected, the number of logical IOs done are same irrespective of number of columns referenced in the query.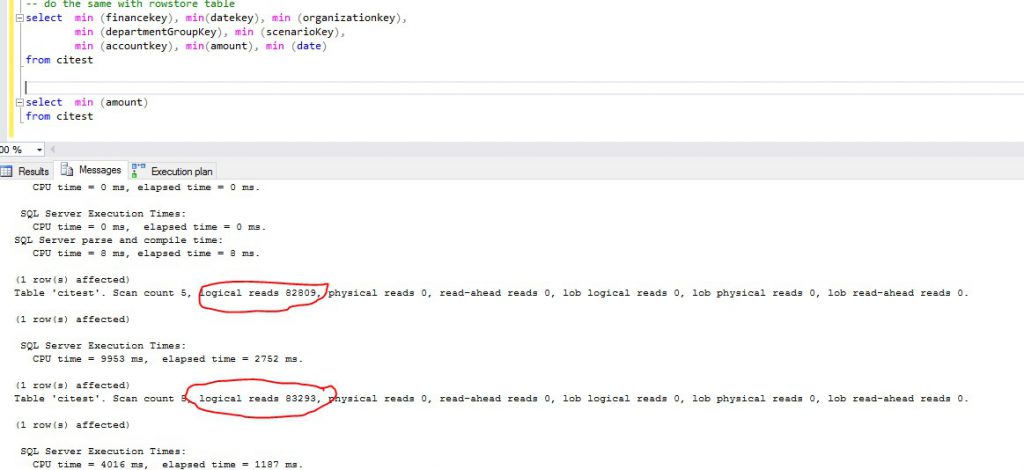
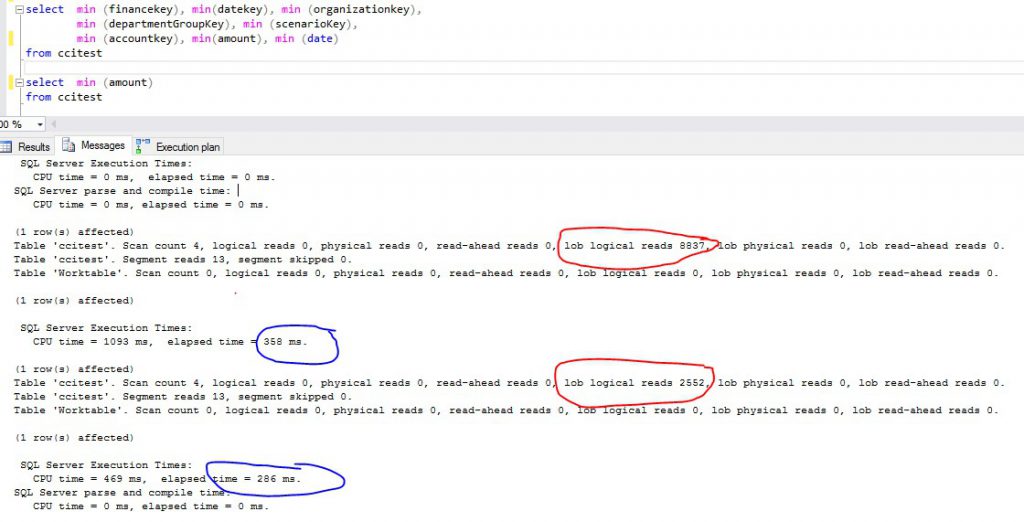
Now, let us run the same two queries on the table with clustered columnstore index as shown in the picture below. Note, that the logical IOs for the LOB data is reduced by 3/4th for the second query as only one column needs to be fetched. You may wonder why LOB? Well, with columnstore index, the data in each column is compressed and then is stored as LOB. Another point to note is that the query with columnstore index runs much faster, 25x for the first query and 4x for the second query when compared with the same queries running on rowstore.
Column elimination speeds up analytics by reducing IO and memory consumption for common schema patterns. For example, in Star Schema pattern, the FACT table is typically very wide containing large number of columns. With columnstore index, only the referenced columns would need to be fetched.
Thanks
Sunil