Columnstore Index: Differences between Columnstore Index vs BTree index
In earlier blog why columnstore index, we had discussed what is a columnstore index and why do we need it. The columnstore storage model in SQL Server 2016 comes in two flavors; Clustered Columnstore Index (CCI) and Nonclustered Columnstore Index (NCCI) but these indexes are actually quite different than the traditional btree indexes. Here are the key differences
- No key column(s): This may come as a surprise. Yes, though there are no key column(s) and yet these are considered as indexes. The reason for no key column(s) is that it would be very expensive to maintain row-order based on key column(s). Rowstore is organized as rows in pages with an auxiliary structure, row-offset table, to allow for an easy ordering of rows. On the other hand, the columnstore index organizes data as columns and compresses each column in one or more segments which would require to uncompress, insert the row, and then re-compress each segment. One of the alternative could be to maintain the row(s) outside of compressed segments but again it adds lot of complexity. Since there are no key-column(s), searching for qualifying rows, in the absence on nonclustered indexes, requires scanning of full columnstore index which can get expensive unless one or more rowgroups can be eliminated based on filter conditions. A common case for DW is that the data is inserted in date/time order and if filtering is done on data/time column, you can get significant rowgroup elimination which can speed up the query performance. For example, if you have 10 years of data in the FACT table and you want to run analytics query on say last quarter, SQL Server will only need to look at 1/40 (i.e. 2.5%) of the data.
- Heap vs Clustered Columnstore index: One way to look at clustered columnstore index is like a ‘heap’ that is organized as columns. Like rowstore ‘heap’, there is no ordering of the rows. A nonclustered index leaf node will refer to a row in columnstore index as <rowgroup-id, row-number> which is similar to how a row is reference is RID<page-id, row-id> for rowstore heaps. When searching for a row through nonclustered index in (NCI/CCI) case, the leaf row of nonclustered index will point to a <rowgroup-id, row-number> which can then be retrieved by accessing the referenced rowgroup.
- Only One Columnstore Index: Unlike rowstore btree indices, you can only create one columnstore index, either CCI or NCCI, on a table.
- Index Fragmentation: For rowstore based indexes, it is considered fragmented if (a) the physical order of pages in out of sync with the index-key order. (b) the data pages (clustered index) or index pages (for nonclustered index) are partially filled. A fragmented index will lead to significantly higher physical IOs and can potentially put more pressure on memory which can ultimately slowdown queries. Most organizations run a periodic index maintenance job to defragment indexes. For details, please refer to https://msdn.microsoft.com/en-us/library/ms189858.aspx#Fragmentation best practices on how to maintain btree indexes. For columnstore index, an index fragmentation is considered fragmented if (a) there are 10% or more rows marked as deleted in a compressed rowgroup (b) one or more smaller compressed rowgroups can be combined to create a larger compressed rowgroup such that the resultant compressed rowgroup has less than or equal to 1 million rows. Note, if a compressed rowgroup has less than 1 million rows due to dictionary size, it is not considered fragmented because there is nothing that can be done to increase its size. Also recall that a columnstore index consists of zero or more delta rowgroups as shown the in the picture below.
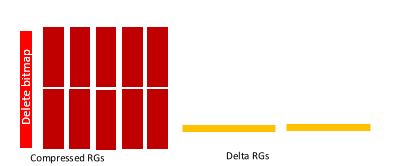
The rows within delta rowgroup are organized as regular btree rowstore and they can get fragmented just like any other btree index but we don’t consider this as fragmentation because delta rowgroups are transitory and they eventually get compressed into compressed rowgroups. Please refer to https://blogs.msdn.microsoft.com/sqlserverstorageengine/2016/03/07/columnstore-index-defragmentation-using-reorganize-command/ on details how to defragment columnstore index, both NCCI and CCI.
Thanks
Sunil Agarwal