Crawler Performance, Hosts, and Impact [Hit] Rules
As part of the crawl processing flow, the Crawl Component starts "robot" threads that orchestrate items from gathering to feeding and finally committing their final state (see this previous post on Crawl Orchestration for more details and an illustration of that flow). In this post, we focus more on the "robot" threads, Crawler impact rules, and the performance implications.
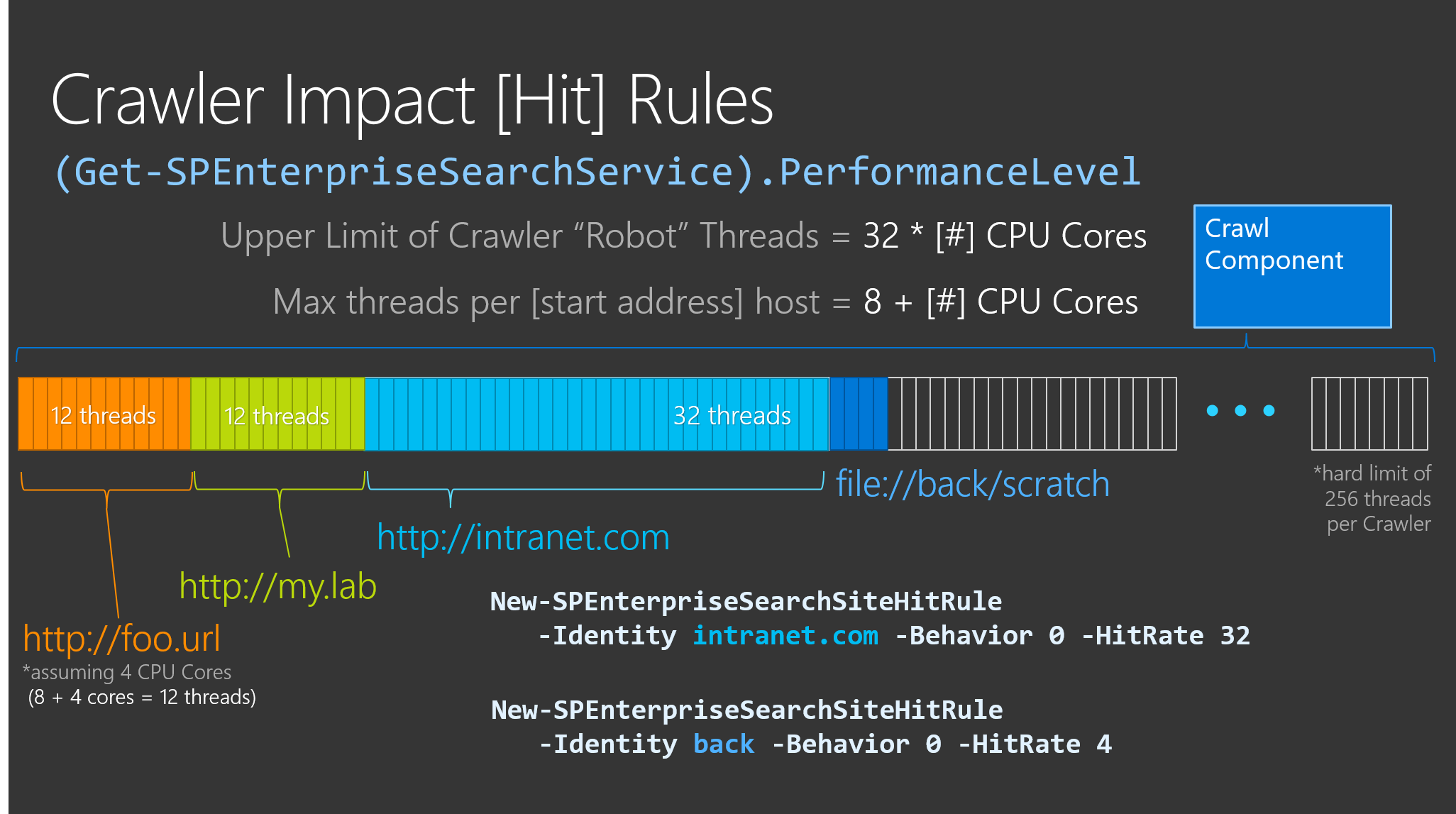
SharePoint provides some farm-wide Search settings including one named PerformanceLevel that (from TechNet for the cmdlet Set-SPEnterpriseSearchService) "[s]pecifies the relative number of [robot] threads for the crawl component performance. The type must be one of the following values: Reduced, PartlyReduced, or Maximum (The default value is Maximum) ", where:
- Reduced: Total number of threads = number of processors, Max Threads/host = number of processors.
- Partly Reduced: Total number of threads = 16 times the number of processors , Max Threads/host = 8 plus the number of processors. Threads are assigned Below Normal priority.
- Maximum: Total number of threads = 32 times the number of processors, Max Threads/host = 8 plus the number of processors. Threads are assigned Normal priority.
*Side note: Although no longer documented, a single Crawl Component can only start a maximum of 256 threads regardless of how many CPU cores the server possesses.
Or more simply, the number of CPU cores and the PerformanceLevel determines the total number of threads that a single Crawler can create (e.g. the upper bound of threads for a given Crawler). This also defines the default Crawler Impact rule for each host being crawled (e.g. "Max Threads/host"). For example, assuming a Crawl server with 4 CPU cores, the Crawler can create up to 12 threads for a given host being crawled. In this same environment, you can also create specific Crawler Impact rules to increase or decrease the number of threads allowed for a given host.
When talking crawl health and performance, the number of hosts being crawled at any given time plays a huge roll in the load generated by the Crawler because this will directly influence the number of threads created at any given time. In other words, the more hosts (e.g. start addresses) you crawl concurrently, the more resources the Crawl Component(s) will consume...
- First, for a bit of clarity: "host" in this blog post refers to the domain portion of a URL and should not be confused with the underlying servers hosting a web site.
- For example, assume I have one web application (e.g. https://foo.url.com) that is load balanced across ten SharePoint servers.
- From the Crawler perspective, I only have one host ("foo.url.com") being crawled in this example.
Next, as an exaggerated example, assume an environment with one crawl component and we want to crawl…
- 1 web application with 10 million items
- Versus 100 web applications each with 100,000 items
Even though both cases are 10 million items to be crawled, the Crawl Component will consume SIGNIFICANTLY more resources for the second scenario than the first because the first scenario is effectively capped by the “max threads per host” limit defined by the PerformanceLevel (or by individual crawler impact rules). In other words, the Crawler would only allocate 12 threads (*assuming a 4 core server) for the first web application but saturate all available threads in the second example (e.g. 100 hosts * 12 threads)
- Keep in mind that this exaggerated scenario is quite feasible with Host Named Site Collections where each site collection is a unique host.
The point above may become a problem when you have the Admin Component running on the Crawl Component, the PerformanceLevel is Maximum *(in which case, the crawler’s robot threads are started with a normal thread priority …which is higher than the threads for the Admin Component), and you are crawling many, many hosts concurrently
- In this case, the Crawl Component dominates the resources on the server
- And this may prevent [the Generation Controller in] the Admin Component from committing generations across the Index replicas in a timely fashion (which would show in the "Content Processing Activity" chart as Indexing time
- Which in turn, slows down crawls and commonly results in Index replicas getting out of sync.
And same goes for the Indexer... because the Crawl Component can be so heavy handed when crawling as described above, I would also generally recommend NOT putting them on the same server as an Indexer (and this advice is echoed in almost any of the TechNet documentation talking about Search performance and/or scaling)
-----
Workaround to minimize the impact of the Crawler:
When the Crawl Component is running with other components (especially when crawling a lot of hosts concurrently), you should consider setting (Get-SPEnterpriseSearchService).PerformanceLevel to “PartlyReduced” to help prevent the Crawler from dominating all resources on this server...
- With the default “Maximum” setting, the threads started by the Crawl component run with Normal priority (i.e. CPU thread scheduling priority : THREAD_PRIORITY_NORMAL)
- Have you ever had a Crawl server that was too busy to remote into during a crawl? If the Crawler was running with "Maximum" (meaning, threads with Normal priority), the remote desktop session was most likely not able to preempt the crawl threads and thus not getting sufficient CPU cycles for your remote session
- With “PartlyReduced” and “Reduced”, the threads are started with Below Normal CPU thread prioritization
And, if crawling a lot of start address hosts, then you should also consider setting crawler impact rules, too. I typically recommend a prioritization of each start address (e.g. the “hosts” being crawled) where:
- High priority content is allowed to use the default number of threads (*which is the number of physical CPU cores + 8)
- The normal priority content is something less…
- And any know-to-be-slow content sources (think: file share in another geography), set a crawler impact rule of just 1 or 2
-----
Other things to consider for Crawl performance (but not directly related to Crawler Impact rules)
- Gigantic Index schema can also have a really big [negative] impact to Search performance (particularly to crawl performance)
- AV can wreck your performance:
- Insufficient disk space for the Indexers can lead to silent failures of the replicas…
- This definitely impacts performance …and the longer this [silently] continues to fail, the worse the problem gets
- Eventually, the only way out is to add more disk space or reset the index
- See my post here: https://blogs.msdn.microsoft.com/sharepoint_strategery/2015/07/08/sp2013-using-get-spindexreports-to-troubleshoot-failed-master-merge/
- For what it’s worth, I have an updated version of the script I reference in that post in our since created “Search Health Reports (SRx)” project which has a LOT of search troubleshooting tests
- I need to get a recent version uploaded to the TechNet gallery, but I can get you a more recent copy if you are interested
- When assessing the Crawl performance and looking for bottlenecks, I tend to start with the “Crawl Load” report
- At Ignite 2015, I talked about this chart, too (around the 47m 30s mark)
- And recently blogged about this point here.
I hope this helps...