SP2013 Crawling *Explained: Orchestration (Part 1)
With VerboseEx logging enabled, the crawl of a single item (or interchangeably, a "document") can generate more than 6000 ULS events, at times making troubleshooting a particular document analogous to finding the needle in the haystack. In this series of posts, I hope to help your troubleshooting efforts by first describing the high level orchestration for crawling a document and then use subsequent posts to deep dive into each step using key events from ULS. The goal is to facilitate troubleshooting by showing an expected path in detail (e.g. as a point of comparison).
Orchestrating the Crawl of an Item
During the crawl of a Content Source, the Crawl Component manages the flow of items – from gathering from the content repository, content submission (aka: "feeding") to the Content Processing Components, and callbacks handling for the overall status of a given item. The Crawl Component also maintains the Search Crawl Store DB as the central repository for all crawled documents and tracks the lifecycle for each Document (e.g. the access URL for each item that has been crawled, the last crawl time and crawl status of each item [success, error, warning], and deletion status) in the MSSCrawlUrl table, with each item identified by its DocID.
The Crawl Component is implemented by two processes:
- Search Gatherer Manager (mssearch.exe), the parent process that manages crawl orchestration, interfaces with the Search DBs and feeds the Content Processing Component via the Content Plugin
- Filtering Daemon (mssdmn.exe), sacrificial child process(s) that hosts Protocol Handlers (e.g. specialized connectors to content repositories) and interfaces with a content repository
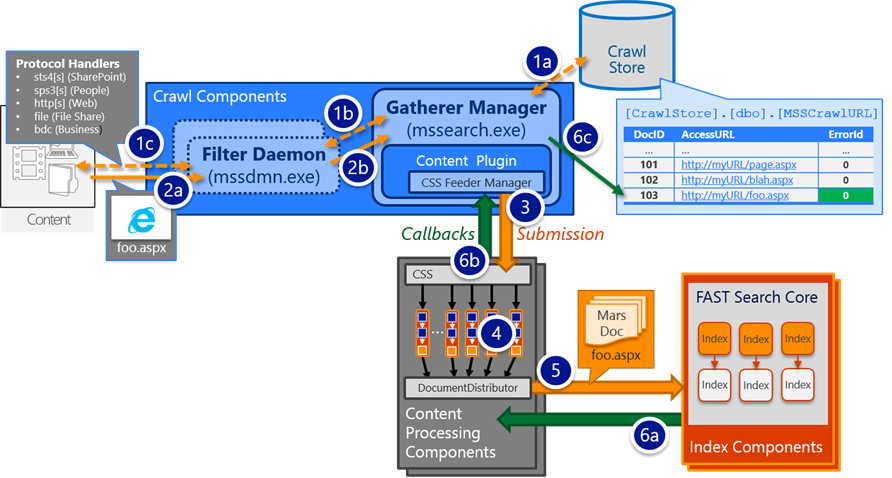
At a high level, crawling a document in SharePoint 2013 involves the following:
- Enumeration/Discovery: The process where the Crawl Component:
- Asks for the links to items from the content repository (e.g. "what items do you have within this start address?")
- And then stores these emitted/discovered links in the "crawl queue" (the MSSCrawlQueue table in the Crawl Store Database)
- Gathering: The process of the Crawl Component retrieving [think: downloading] the enumerated items (e.g. using links from the crawl queue)
- Each Crawl Component independently earmarks a small sub-set of items from the MSSCrawlQueue to be gathered/processed; once earmarked, the item is considered part of a "search transaction"
- Feeding: The process of the Crawl Component submitting the gathered items to the Content Processing Component(s)
- Processing: The process of the Content Processing Component converting the documents into a serialized object of Managed Properties (aka: "Mars Document")
- The CPC will produce one Mars Document for each item gathered/fed for processing. In other words, the Mars Document is the end product from processing
- Index Submission: The process of submitting the processed document (e.g. the Mars Document) to Index Components where it will be inserted into the index
- Just before submission, a collection of Mars Documents get batched into a "Content Group", which gets submitted to the Index as an atomic operation
- Callback Handling: Following Index Submission:
- A callback message gets returned back to Content Processing Component regarding the status of the Index Submission
- Then, another callback gets returned from the Content Processing Component back to the Crawl Component regarding the status of processing (which implicitly includes the status from Index Submission as well – In other words, processing cannot report success if Index Submission failed)
- Finally, the transaction for the item completes when its status is persisted to the MSSCrawlUrl table and the item gets cleared from the MSSCrawlQueue table
In coming posts: Peeling back the onion…
So far in this series, we have covered:
- A high-level view to orchestrating the crawl /* this post */
- A deep dive look at starting the crawl
- Enumeration/Discovery
- Concepts
- Illustrating through ULS /* next in the series */
- Simulating with PowerShell
And in coming posts, we will then deep dive into each of the six areas summarized above (and I'll update this post with the links here as each section gets posted)
…to be continued J