Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
SQL Server Support Blog
URL
Copy
Options
Author
invalid author
Searching
# of articles
Labels
Clear
Clear selected
ADO
ADOMDCLIENT
ag
Agents
AKS
Alias
aliases
always encrypted
Analysis Services(SSAS)
Architecture & guidance
Automated backup
availability groups
Azure
Azure SQL Extension SSL error
Azure SQL VM
Backup
bdc
Best Practice
Big Data Clusters
CDC
ce
Change language
Change locale
Change sql installation language
cname
Command L
Connectivity
Custom Visuals
dacfx
DACPAC
Database Mail
DNS
Domain
Errors
Events and Conferences
Full-Text Search
generic ODBC
gpo
HA
High Availability
InMemory OLTP
Integration Services(SSIS)
jdbc
JET
Kubernetes
lifecycle
Linked Server
linux
Machine Learning
managed backup
memory
MSDTC
ODBC
OLEDB
patching
PBIRS
pbix
Peformance
Performance
PolyBase
Power BI
PowerBI Desktop for RS
Replication
Reporting Services(SSRS)
SCM
Security
Service Broker
Setup
SNAC
SOS
Special Datatypes
sql
SQL 2005
SQL 2008
sql 2012
SQL 2014
sql 2016
sql 2017
SQL 2019
SQL Agent
SQL CE
SQL CLR
SQLNCLI
SQL OS
SQL Server
SQL Server 2019
SQL Server Agent
SQL Server enabled by Azure Arc. DPS Connectivity
SSDT
SSMA
ssms
SSRS
SSRS 2017
Storage Engine
Stretch
Sybase
SybaseToSQL
Sync Framework
tcp
Tips & Tricks
Transactional
Transactions
Troubleshooting
TSQL
Utilities
XML
- Home
- SQL Server
- SQL Server Support Blog
Options
- Mark all as New
- Mark all as Read
- Pin this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed

1,832
2,310
1,834

2,654
8,326
12.5K

19.2K

6,199
10.4K
17.9K
13.7K
4,116

5,110

16.9K
6,556

5,596
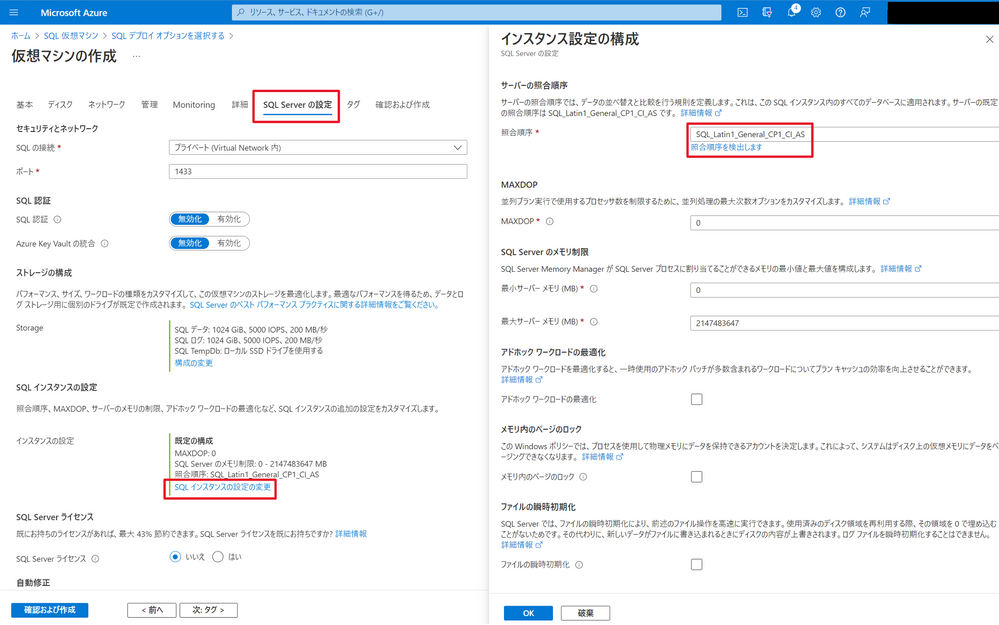
4,238

6,258

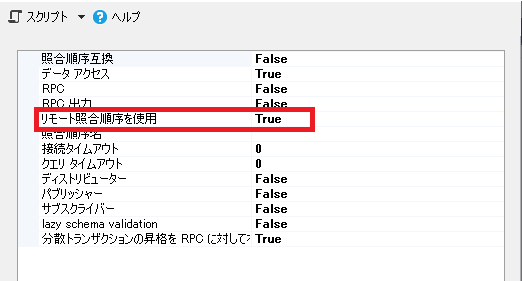
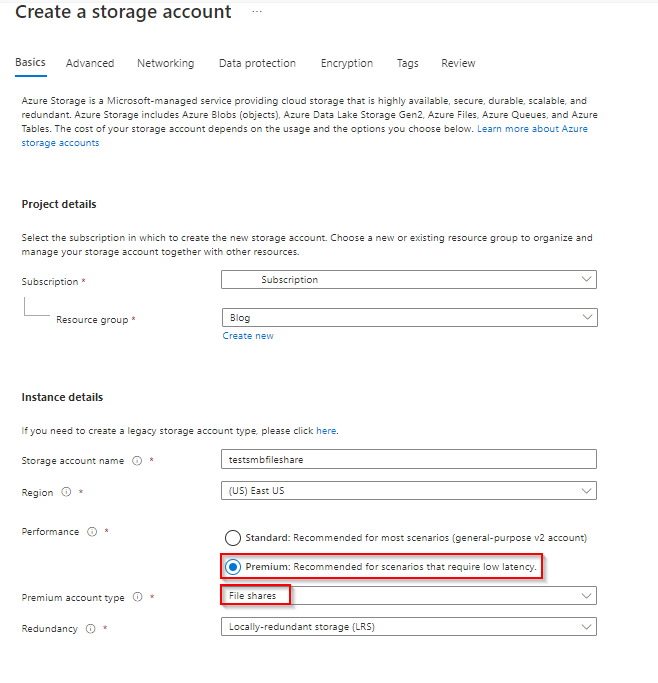
4,745
Latest Comments