Agile and the Theory of Constraints – Part 3: The Development Team (3)
Finally, we make our way to the heart of the development team and the design & code phase. 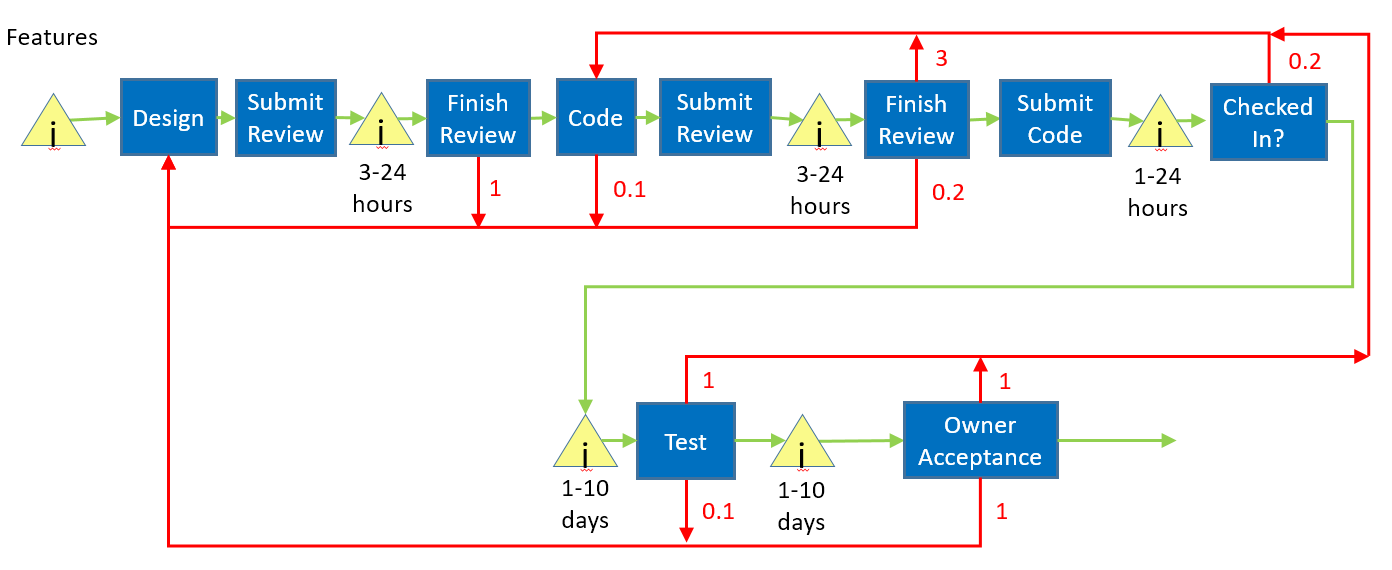
That is the top part of this diagram.
The design/review/finish and code/review/finish chunks are very similar. The developer does some work, submits it for review, perhaps does rework based on the review, and then finally finishes and moves onto the next step.
As is common with an overall map, we're some important details: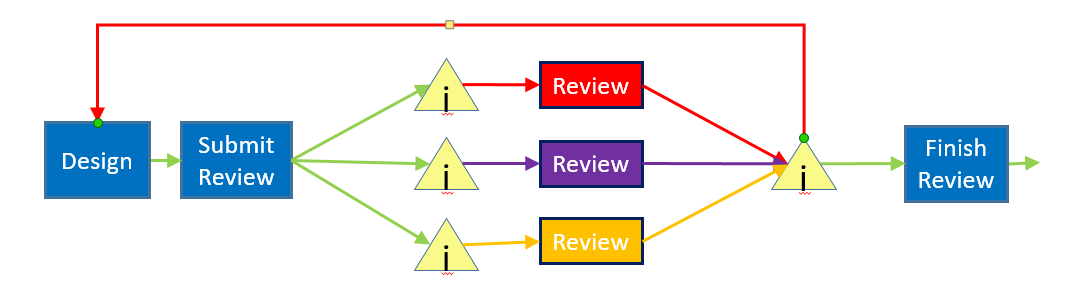
In this detailed view, we see that the "Submit Review" step leads to a queue in front of three other developers, which then leads back to a queue for the original developer.
Let's explore a different perspective, switching from a value stream view to a sequence diagram. This diagram shows what each person is doing during a typical code review cycle: 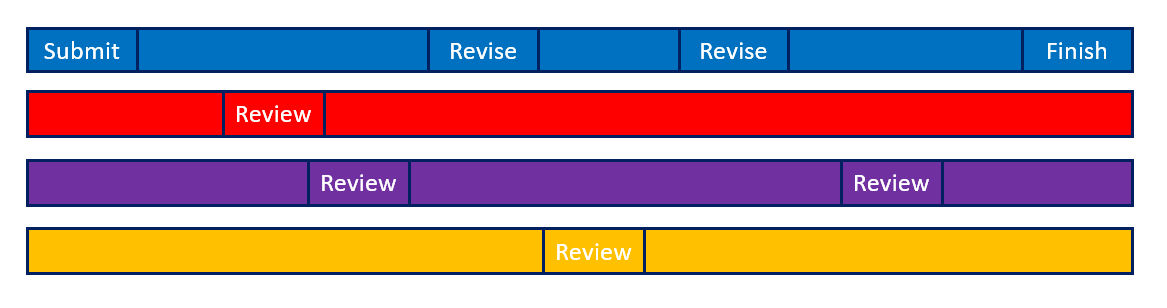
I tried to pick what feels like a reasonable example; of course there are some reviews that are simpler and some that are much more complicated.
What we see here looks very nice from a utilization perspective; everyone is busy all the time, and the time from submission to finish for Miss Blue looks pretty good.
This diagram is missing a bit of detail, so let's add that in: 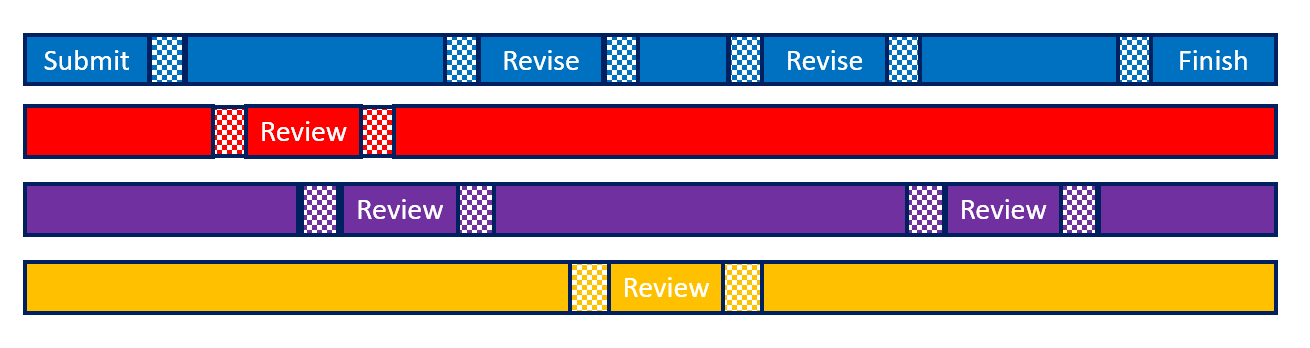
What we were missing is what the manufacturing world calls "setup time", which is the time it takes to switch a machine from doing one task to doing another. Obviously, this time is time that the machine is not doing useful work, and therefore reducing the time spent on setup is a major factor in optimizing throughput (article).
In our world, we call this period a context switch. This isn't a strict downtime, but there is a time of reduced efficiency, where developers are both less productive and more likely to make mistakes. How long it is depends upon the complexity of the mental model required; it might be only a couple of of minutes for a simple task, or it might be thirty minutes for a complex debugging scenario. Every time we switch from working on one thing to another, there is a loss of productivity and quality.
Note that this is the diagram for one review; the actual sequence diagram for a developer can be much worse; there may be multiple reviews going on at the same time, and there are other interruptions as well; meetings, breaks, and the all important lunch.
Looking at the diagram, the queues show up as lag time between when Miss Blue submits her code/design for review, and when the other developers start to review it. If we we can reduce that lag time – reduce the time spent in the queue – then we will improve the throughput of the system. So we set up a policy that doing code reviews is our highest priority.

If you've made the choice in the picture, you know what happens; the process that you set to high priority runs faster, and you slow down the rest of the system. If you are lucky, you might even hang the system.
The same thing happens in our process; when a code review shows up, it gets handled quickly, which would seem to be what we want. But it also shifts the required context switch from "when I have some free time" to "right now", and that change makes the interrupt more costly. The teams I've been on that tried this absolutely hated it.
Is there another solution? Well, we know from our earlier examples that getting rid of a queue is far better than just reducing its time – especially if there is a handoff, as we have here – so how can we get rid of a queue?
Well, perhaps we can limit the number of developers who are required for a given code review, so that there is only one review queue per task. It would look something like this:

That is better from an interruption perspective, but we probably lose some quality, Mr. Red has more time and feels more responsible to do a good code review, but he doesn't have any more context than he did before, and he's still going to feel that the time he spends on code review is taken away from his "real work".
How can we improve that? What if he worked with Mrs. Blue during the design and coding, so that he understands *deeply* what is being done and can give immediate context. That would change the review process to be something like this:

And yes, we have invented pairing. One of the benefit of pairing is obvious if you look at the sequence diagram and the long periods of work devoted to a single task; that is clearly going to have less waste than the previous diagram.
The groups that I have been on that paired heavily ended up with a slightly different workflow; when the code is done, a code review is always sent out – so that others can see what is going on if they wish – and the pair has the option to ask for review from somebody else if they think they need it.
This has worked very well in the groups that I've worked in.
<aside – the hidden cost of context switches>
If you are currently in a world like the one I described – one with lots of context switches – you might be saying to yourself, "self, I can see how it would be nice to have fewer interruptions, but I'm pretty good at context switching and still being productive."
Such a feeling is nearly universal, and almost always, it is wrong. When we are in a world that requires context switching – especially one where those context switches are higher priority – it's hard not to be in a reactive, firefighting mode. What I sometimes call tactical mode.
If you are in tactical mode, it's very hard to engage your thoughts around bigger strategic questions, such as whether the approach that you are taking is an efficient one. Instead of "being productive" meaning "making good choices about how things are done so as to maximize output", it becomes "responding quickly to interrupts and doing a decent job of juggling all the things on my plate".
Or, to put it another way, in a results-driven, context-switching environment, the chance that you are spending any time at all thinking about your efficiency is pretty low.
To go back to my processor/operating system analogy, everybody knows what happens to background tasks when your CPU is at 100%, and strategic level thinking is a background task.
I honestly think that if you can get rid of code review interruptions, that alone saves enough time to make pairing equal to single-developer work, without going to any of the other advantages.
</aside>
Checkin Queue
Finally, we get to the checkin queue, where you submit code into a system that builds it runs all the tests, and then checks the code in if it was successful. This is often known as "gated checkin".
Let's add in some of the missing detail. 
When we submit our code, we jump into a queue where a separate machine will get the changes, make sure that everything builds, run the tests, and then either check the code in if it works or send an email to us telling us what the problems are.
Let's analyze the situation here…
First, I see that there is a queue for the developer to wait for this process to happen. That will require them to figure out something else to do during this time period. The wait is going to depend on how big the queue before "build" is, and how long the build and test run is going to take.
What effects does this approach have on the organization?
- Developers have to figure out something else to do while they wait, which involves a context switch and/or "looking busy".
- Because of the time lag, there is possibility that somebody on your team will have their checkin finish before yours, and if their changes are incompatible with yours, you will have to wait.
- Because the wait feels like wasted time to the developers (it is…), they will try to optimize by making their submissions bigger, which makes their code reviews bigger and harder to understand. None of this is good.
- If the infrastructure breaks, we are dead in the water until it is fixed.
- The "run tests" step is a magnet for more tests; if bugs get through the box, it's very tempting to add tests. That is *great* if they are unit tests, and horrible if they are integration tests, as the time to run the tests will get much slower.
- The attitude is "the system is supposed to find the errors", which makes it easy to be sloppy and just submit things.
- Failures are generally private, and not considered to be that important.
- If there is a big failure that makes it though even though it shouldn't have, you need to stop the whole system and block everybody until you get it fixed.
The incentives typically push these systems into becoming bottlenecks, and they also lock the behavior of the team around the system; the team cannot experiment in this area because the system prevents it. My experience is that this can work okay with small codebases, but it rarely turns out good in larger codebases.
Is there an alternative that gets rid of the bottleneck? Consider the following: 
When the developer is finished, they check in their changes. There is a separate build/test machine that notices the changes, does the build, and runs the tests. If things are okay, it doesn't do anything. If there is a failure, it emails the team (and in some teams, turns on a flashing red light in the team room).
What are the differences?
- We have gotten rid of the queue, which saves time
- Developers can work in smaller chunks. There is great synergy with pairing and working in small increments.
- Failures are obvious, which puts social pressure on developers to be more careful.
- The system rewards the behavior you want to incentivize; it encourages developers to be a little more careful, it encourages them to run tests on their computers (and therefore encourages them to keep those tests simple and fast).
- It treats developers like adults who can make rational choices around what needs to be done before a checkin is made.
The one downside of this system is that the build is sometimes broken. The teams I've worked on have adopted a "5 minute rule"; if you can fix the breakage in 5 minutes – say you just forgot to include a new file when you checked in – then you are allowed to do it. If it's going to take longer than that, you revert your checkin so that nobody else is blocked.
Which finally brings us to the end of the developer team section. Up next… the individual developer… Next: Part 4 - The Inner Loop