Agile and the Theory of Constraints: Part 4–The Inner Loop
In this post, I'm going to talk about what I'm calling the inner loop, what some people call "Ring Zero"; it is basically the simple act of writing code and validating it, over and over. It is focused on a single developer.
Code/Test/Code/Test/Code/Test/Code/Test
Before I dig into things, I have a bit of pre-work for you. I would like you to spend 5 minutes listing all the things that you (or your team) do/does as part of the inner loop, and then create a value stream map from that information. Put numbers on all of the steps, but don't worry if they aren't particularly accurate. You can also use a range like 5-10 minutes.
Do you have a diagram that describes your current process? Great.
Here's the first diagram I came up with:
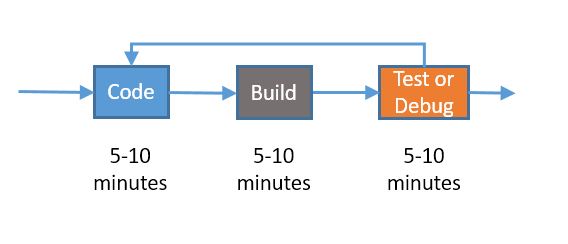
The times are going to vary considerably for a given team and a given developer. Let's expand a little bit on the diagram to add our first handoff. This time, because we're only talking about a single developer, it's a different kind of handoff.

When we start a build, we are handing off the code to another process –the compiler – and we will need to wait until that process is done. And no, that 5-60 minutes is not a misprint; I've worked on a number of teams where a full build was at least an hour.
If you are thinking, "self, that looks like a queue/handoff and a context switch, and that is bad". If so, give yourself a gold star and a hearty "Well done!". Let's flesh this out a bit more….

Before we can test or debug our code, we need to deploy it to a place where we can test or debug it. If we are running unit tests, we don't have a deploy step, which is why it sometimes takes 0 minutes.
Finally, sometimes we are successful, and sometimes we are not. That needs to be represented in the diagram as well…

If our build failed or our test/debug failed, we need to go back and tweak the code. If it worked, then we need to figure out the next thing to do.
Time to search for bottlenecks. Where do we look?
The usual places; we look for handoffs and we look for queues. Waiting for the build and waiting for the deployment are excellent candidates. Before we dig in there, I want to go on a bit of a tangent…
In earlier posts, I talked in depth about developers switching to do something else and the costs of that. I'd like to quantify that using Eric's Theory of Developer Wait Times.
It sounds more grandiose than it really is…
Wait time |
Impact |
None |
No impact |
<15 seconds |
Slight impact on flow |
60 seconds |
Some context lost. Annoying. |
2 minutes |
Most context lost; hard to keep focus |
> 2 minutes |
I'm doing something else |
This is basically just a repurposing/reexpression of the research around how users react to delays in programs.
Once we get above 2 minutes, it's time to read email, take a nature break, get some water, read the Facebooks, etc. Because it's a hard interruption, it's really easy for 3 minutes to turn into 15 minutes.
Since developers spend a lot of time waiting for builds, the majority of the teams out there put a high priority on having fast builds; they give developers capable machines on which to do builds, they architect their projects so that components are small and builds can therefore be fast, and the focus on fast-executing unit tests rather than slower integration tests.
Ha Ha. I make joke.
Remember the discussion about how local optimization can de-optimize other parts of the system from the last post? Here's another example.
The amount of time I waste waiting for a build is determined by how long the build takes and how many times I need to wait for it. If my build takes 10 minutes, I will look to batch my work so that I minimize how much time I spend waiting for builds. That means bigger checkins, with all the downsides that come from them; mistakes are more common, design feedback is less likely to acted upon, etc.
Is this obvious, or even noticeable? If you ask most dev leads about the impact of build speed on their team's productivity, they will say something like, "Our build is slower than we would like, but it's not a large drain on our productivity". They say this whether their average build takes 30 seconds or their average build takes 15 minutes. That is based on an estimate of the "time spent waiting for builds" / "total time" metric. Developers will rearrange how they do things (ie "optimize") so that the metric doesn't get too far out of whack in most cases.
What they are missing is the opportunity cost of having slow builds.
- Slow builds means no TDD. I am fairly stubborn and I've tried to modify TDD to make it work when I have slow builds, but it isn't really effective, and there is no way I can convince anybody else to try it.
- Slow builds mean I (probably) can't leverage any of the continuous testing tools such as NCrunch or dotCover in the C# world or Infinitest in the Java world. Ncrunch is why there is a "none" entry in the wait time table; you just write your product code and your test code and everything happens in the background, with no wait for compile or deploy.
- Slow builds mean my team will write fewer tests.
- Slow builds mean my team will do fewer refactorings.
In lean terms, slow builds are a constraint, and the developer optimization is an attempt to subordinate the constraint. Which is fine as long as you exploit and elevate the constraint to try to remove it as a constraint.
If you can only do one thing, work on getting your developer builds faster.
Having a short deployment cycle is also important, but if your builds are quick and you write unit tests, you will be spending a lot more time in that cycle and less time in the deployment cycle. For deployment I think that simple and automated is more important than pure speed, because mistakes you make in deployment kill your overall cycle time; just forgetting to deploy one changed binary can cost you anywhere from 15 minutes to a couple of hours. On the other hand, if you can make deployment very fast as well, nobody will be tempted to build a faster version of it, which has a lot of other benefits.
Figure out what code to write
We will now move the fill in the left side of the diagram, the part where we figure out what code to write.

There are three ways we figure out what code to write:
- Sometimes we just think about it, or we already know pretty much what we want to do.
- Sometimes we have to do some research to figure out what we need to do and/or how to do it.
- Sometimes we ask somebody.
Where are the bottlenecks here?
One of them is obvious – it's the time that we spend finding somebody to ask and/or the time we spend waiting for an email response to the a question. Unless it's a person-to-person interaction, that part generally takes long enough that we "go do something else".
So, we should just try to limit that path, right?
Well, nobody likes to interrupt other people to find out something you could have found out yourself, and in many (most?) teams there are social pressures that keep you from choosing that branch first, so they choose the upper research branch first.
The flow in that branch typically looks something like:
- Need to do <x>
- Do a web search on <x>
- Read a few articles
- Go write some code
- Can't figure out on of the samples.
- Go back and read some more
- Modify the code.
- Build/deploy/test the code
- Mostly works, but not sure
- Go back and read some more
- Try something else
- Code works, go do something else.
Is that the most efficient way to do things? Or, to put it another way, if we wanted to make this faster, what would we do?
Well, the obvious observation is that our build/test/deploy time has a big effect on the cycle time here; that was one of the reasons I talked about that first. If you can experiment quickly, you can be a bit less sure of what you are doing, spending less time researching and more time doing.
But there's a larger thing at play here.
Our goal is obviously to get to the exit arrow as quickly as possible (assuming good testing, good quality code, etc. ). To do that, we have to write the code that is correct.
So, to state it another way, our bottleneck is figuring out what the right code is. If we can do that quickly, then the coding and testing part is generally pretty straightforward.
How do we become more efficient at that? How do we get rid of the waste?
The answer is simple. The biggest waste is when we go down the wrong path; we don't understand the code correctly, we don't understand what we are trying to do, or we use a more cumbersome way of solving a problem. How do we solve that? Well, we need to apply more minds to the problem.
Some groups have an "ask for help" rule, which says if you have been stuck on a problem for more than 15/30/60 minutes, you are required to ask for help. Which is a good idea, but you've already wasted a lot of time, nobody likes to ask for help, and you have to interrupt somebody else to ask, slowing them down.
What we really need is a way to dedicate extra brainpower to a task from the start. By doing so, we will reduce false starts, research flailing, waiting too long to ask, etc. – and we will write the right code faster.
And, once again, we've invented pairing.
Pairing is more efficient because it directly targets the waste in the system:
- Time spent researching how the system works
- Time spent researching options
- Time spent modifying code when it doesn't work
- Time spent doing more research when we could have just asked somebody.
Why don't teams try to become more efficient at writing good code?
Well, that ties back to one of the weird parts of the profession.
Writing software is a very complex task, especially if you are doing it in a codebase that has a lot of technical debt. Because of that, it is very hard to estimate how long a given task should take, which – transitively – means that it is often hard to determine whether a task is taking longer than it should. We don't want to ask developers why a task is taking so long because that encourages the wrong behavior and we know that sometimes things just take a long time to do.
Pairing gives us a way to hop inside that complex task and get rid of the waste without having to ask the wrong question or mess up the group dynamic. That is one of the reasons it is so powerful.
That is all for this post, and that takes me to the end of where I envisioned the series. I do think there might be a short summary post to wrap things up.