WSL System Calls
This is the third in a series of blog posts on the Windows Subsystem for Linux (WSL). For background information you may want to read the architectural overview and introduction to pico processes.
Posted on behalf of Stephen Hufnagel.
System calls
WSL executes unmodified Linux ELF64 binaries by emulating a Linux kernel interface on top of the Windows NT kernel. One of the kernel interfaces that it exposes are system calls (syscalls). This post will dive into how syscalls are handled in WSL.
Overview
A syscall is a service provided by the kernel that can be called from user mode which typically handle device access requests or other privileged operations. As an example, a nodejs webserver would use syscalls to access files on disk, handle network requests, create processes\threads, and other operations.
How a syscall is made depends on the operating system and the processor architecture, but it comes down to having an explicit contract between user mode and kernel mode called an Application Binary Interface (ABI). For most cases, making a syscall breaks down into 3 steps:
- Marshall parameters – user mode puts the syscall parameters and number at locations defined by the ABI.
- Special instruction – user mode uses a special processor instruction to transition to kernel mode for the syscall.
- Handle the return – after the syscall is serviced, the kernel uses a special processor instruction to return to user mode and user mode checks the return value.
While the Linux kernel and Windows NT kernel follow the steps above, they differ in ABI so they are not compatible. Even if the Linux kernel and Windows NT kernel had the same ABI, they expose different syscalls that do not always map one to one. For example, the Linux kernel includes things like fork, open, and kill while the Windows NT kernel has the comparable NtCreateProcess, NtOpenFile, and NtTerminateProcess. The following sections will go into the specifics of making syscalls in the different environments.
Syscall mechanics on Linux x86_64
The calling convention for syscalls on Linux x86_64 follow the System V x86_64 ABI defined here. As an example, one way to call the getdents64 syscall directly from a C program would be to use the syscall wrapper:
Result = syscall(__NR_getdents64, Fd, Buffer, sizeof(Buffer));
To discuss the syscall calling convention it’s easiest to translate the line of code into pseudo assembly to show the 3 steps above:
- mov rax, __NR_getdents64
- mov rdi, Fd
- mov rsi, Buffer
- mov rdx, sizeof(Buffer)
- syscall
- cmp rax, 0xFFFFFFFFFFFFF001
First, let’s look at how the parameters are marshaled. Steps 1-4 move the syscall parameters into the registers specified by the calling convention. Then on step 5 the special syscall instruction is made to transition to kernel mode. Finally, on step 6, the return value is checked by user mode.
Between steps 5 and 6 is where the Linux kernel handles the getdents syscall. When the syscall instruction is invoked, the processor performs a ring transition to kernel mode and starts executing at a specific function in kernel mode typically called the syscall dispatcher. As part of kernel initialization when the machine is booted, the kernel configures the processor to execute the syscall dispatcher with a specific environment when the syscall instruction is invoked. The first thing the Linux kernel will do in the syscall dispatcher is save off the user mode thread’s register state according to the ABI so that when the syscall returns the user mode program can continue executing with the expected register context. Then it will inspect the rax register to determine which syscall to perform and pass the registers off to the getdents syscall as parameters. Once the getdents syscall completes, the kernel restores the user mode register state, updates rax to contain the return value of the syscall, and uses another special instruction (usually sysret or iretq) that informs the processor to perform the ring transition back to user mode.
Syscall mechanics on NT amd64
The calling convention for syscalls on NT x64 follows the x64 calling convention described here. As an example, when the NtQueryDirectoryFile call is made we’ll have this simplified version of the call so it’s easier to compare against the getdents call above:
Status = NtQueryDirectoryFile(Foo, Bar, Baz);
The real NtQueryDirectoryFile API takes 11 parameters which would be strenuous for this example since it requires pushing arguments to the stack. Now let’s look at the disassembly side by side with the getdents case to see how the three steps are handled on NT compared to Linux:
| Step | Getdents | NtQueryDirectoryFile |
| 1 | mov rax, __NR_getdents64 | mov rax, #NtQueryDirectoryFile |
| 2 | mov rdi, Fd | mov rcx, Foo |
| 3 | mov rsi, Buffer | mov rdx, Bar |
| 4 | mov rdx, sizeof(Buffer) | mov r8, Baz |
| 5 | syscall | syscall |
| 6 | cmp rax, 0xFFFFFFFFFFFFF001 | test eax, eax |
For the marshalling parameters step, we see that NT also uses rax to hold the syscall number but differs in the registers used to pass the syscall parameters because it has a different ABI. For the special instruction step, we see syscall is also used since it is the preferred method on x64 for making syscalls. For the final step of checking the return, the code is slightly different because NTSTATUS failures are negative values whereas Linux failure codes fall into a specific range.
Just like with the Linux kernel, between steps 5 and 6 is where the NT kernel handles the NtQueryDirectoryFile syscall. This part is pretty much identical to Linux with some small exceptions around the ABI related to which user mode registers are saved and which registers are passed to NtQueryDirectoryFile. Since NT syscalls follow the x64 calling convention, the kernel does not need to save off volatile registers since that was handled by the compiler emitting instructions before the syscall to save off any volatile registers that needed to be preserved.
Syscall mechanics on WSL
After looking at how syscalls are made on NT compared to Linux, we can see that there are only a few minor differences around the calling convention. Next we’ll take a look at how syscalls are made on WSL.
The calling convention for syscalls on WSL follows the Linux description above since unmodified Linux ELF64 binaries are being executed. WSL includes kernel mode pico drivers (lxss.sys and lxcore.sys) that are responsible for handling Linux syscall requests in coordination with the NT kernel. The drivers do not contain code from the Linux kernel but are instead a clean room implementation of Linux-compatible kernel interfaces. Following the original getdents example, when the syscall instruction is made the NT kernel detects that the request came from a pico process by checking state in the process structure. Since the NT kernel does not know how to handle syscalls from pico processes it saves off the register state and forwards the request to the pico driver. The pico driver determines which Linux syscall is being invoked by inspecting the rax register and passes the parameters using the registers defined by the Linux syscall calling convention. After the pico driver has handled the syscall, it returns to NT which restores the register state, places the return value in rax, and invokes the sysret\iretq instruction to return to user mode.
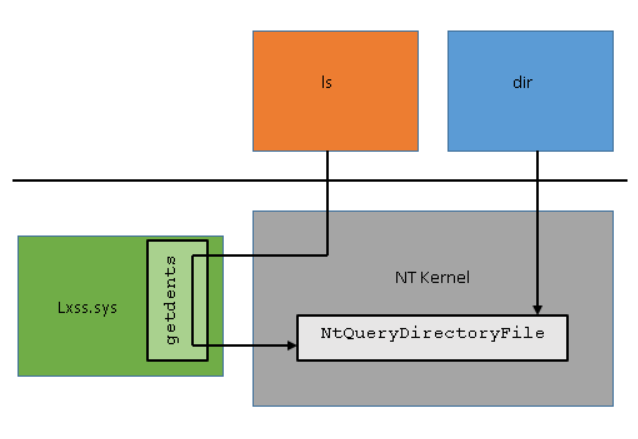
WSL syscall examples
Where possible, lxss.sys translates the Linux syscall to the equivalent Windows NT call which in turn does the heavy lifting. Where there is no reasonable mapping lxss.sys must service the request directly. This section will discuss a few syscalls implemented by WSL and the interaction with NT.
The Linux sched_yield syscall is an example that maps one to one with a NT syscall. When a Linux program makes the sched_yield syscall on WSL, the NT kernel hands the request off to lxss.sys which forwards the request directly to ZwYieldExecution which has similar semantics to the sched_yield syscall.
While sched_yield is an example of a syscall that maps nicely to an existing NT syscall, not all syscalls have the same properties even when there is similar functionality on NT. Linux pipes are a good example of this case since NT also has support for pipes. However, the semantics of Linux pipes are different enough from NT pipes, that WSL could not use NT pipes to get a fully featured Linux pipe implementation. Instead, WSL implements Linux pipes directly but still uses NT functionality for primitives like synchronization and data structures.
As a final example, the Linux fork syscall has no documented equivalent for Windows. When a fork syscall is made on WSL, lxss.sys does some of the initial work to prepare for copying the process. It then calls internal NT APIs to create the process with the correct semantics and create a thread in the process with an identical register context. Finally, it does some additional work to complete copying the process and resumes the new process so it can begin executing.
Conclusion
WSL handles Linux syscalls by coordinating between the NT kernel and a pico driver which contains a clean room implementation of the Linux syscall interface. As of this article, lxss.sys has ~235 of the Linux syscalls implemented with varying level of support. This support will continue to improve over time especially with the great feedback we get from the community.
Stephen Hufnagel and Seth Juarez explore how WSL redirects system calls.