EE4SP1: Expression Encoder 4 Pro SP1 での GPU エンコーディング
EE4開発チームが作成したGPU (CUDA) エンコーディングに関するドキュメントを当部門で翻訳しましたので掲載いたします。
EE4SP1に限らずCUDAによるGPUでのエンコーディングについて参考になれば幸いです。
------
Expression Encoder 4 Pro SP1 での GPU エンコーディング
著者 : Eric Juteau
著者について : Eric Juteau は、Test on the Microsoft Expression Encoder チームに所属の Principal Software Design Engineer です。”ビデオ” のスーパー エキスパートです。
はじめに
このホワイト ペーパーでは、GPU エンコーディングの重要性の解説をはじめ、Expression Encoder Pro で Nvidia CUDA 高速 GPU を使ったエンコーディングのためのステップバイステップ手順、制限とベストプラクティス、推奨の PC 構成、トラブルシューティングを紹介します。
GPU エンコーディングとは?
従来のビデオ トランスコーディングの処理は水道管を通る水に似ています。まず、非圧縮ビデオ フレームがデコーダー コンポーネントから取り込まれ、リサイズやデインターレースなどの処理が行われた後、最終的にパイプラインの一部であるエンコーダーコンポーネントに送信されます。こうした処理のどこか一箇所で時間がかかってしまうと、システムが “詰まって” しまい、パイプライン全体のビデオフレームの流れが滞ってしまいます。

現在市販されている PC の場合、このトランスコーディング プロセスのボトルネックは最後のエンコーダー コンポーネントであることが一般的です。これは、複数プロセッサを搭載した PC であっても同じです。エンコーダー コンポーネントは、CPU が大きくかかわる場所です。GPU (グラフィック プロセッシング ユニット) とは、通常、グラフィック カードに搭載され、画面へのピクセル描画に使われるハードウェアリソースです。たくさんの処理を並列で処理する場合に高い効率性を実現し、特にビデオ エンコーディングでその威力を発揮します。
Expression Encoder は、デコーディングの編集フェーズやプレビュー ウインドウの前処理やレンダリング処理に GPU パワーをうまく活用していますが、初期のバージョンのエンコーディングではあまり活用されていませんでした。GPU パワーをエンコードにも利用しない手はありません。そこで、今回は、Expression Encoder 4 Pro SP1 を紹介したいと思います。Expression Encoder 4 Pro SP1では、新しいMain Concept社のH.264 CUDA エンコーダーをマイクロソフトのエンコーディング パイプラインに統合しています。その結果、オフラインの場合で、エンコーディングのパフォーマンスが CPU 1 個につき 2 ~ 3 倍改善され、さらにハイエンドのラップトップにおける 3 または 4 HD ストリームのリアルタイム エンコーディングのようなソフトウェアベースのエンコーディングでは実現することのできないライブスムース ストリーミングが可能になっています。
現在、GPU はビデオ エンコーディング処理にのみ使われ、デコーディングと前処理はもっぱら CPU 側で行っています。そのため私たちは、なるべく CPU と GPU の性能を一致させるよう推奨しています。なお、現在私たちのチームでは、GPU を将来的により有効に使用するための方法を調査しています。
エンコーディング時の GPU の用法
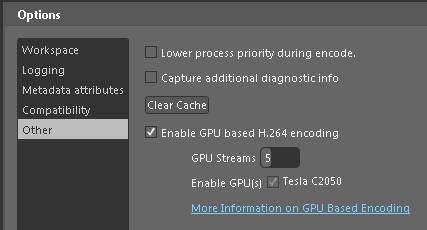
Expression Encoder アプリケーションの場合、GPU エンコーディングはデフォルトで有効になっていますが、Encoder SDK ではデフォルトで無効になっています。このような設定になっているのは、Encoder SDK で API の互換性を維持しながら、機能の存在感をアピールするためです。Encoder アプリケーションの GPU 設定は、[Tools] – [Options] ダイアログの [Other] タブ (下図参照) で確認できます。また、この設定は今後のエンコードすべてに適用されることになっています。

Expression Encoder では CUDA 対応の GPU に対し、マルチ GPU をサポートしています。GPU はすべて一覧表示され、それぞれ独立して有効または無効に設定することができます。複数の GPU が利用可能な場合、ビデオ ストリームの配信は各 GPU に対して均等に、高精度のストリームの方から順に、スネークパターン (1-2-2-1, 1-2-3-3-2-1) で、“GPU Streams” 設定でセットされた数を上限に行われます。たとえば、8ストリームのスムース ストリーミング エンコードを 2 個の CUDA GPU を搭載した PC 上で開始した場合、1 つ目の GPU が取得するストリームは 1、4、5 となり、2 つ目の GPU が取得するストリームは 2 と 3 になります。そして、小さい方から 3 つまでのストリームは CPU により処理されます。パフォーマンス上ベストな GPU/CPU の配分であるため、“GPU Streams” の設定はデフォルトのまま使用することが望ましいとされていますが、お使いのハードウェア構成に合わせて設定を調整して、色々試してみてもいいでしょう。
[Transcoding progress] ダイアログ、それから Live モードの [Statistics] タブを参照すると、実際にエンコード処理中のストリーム数を確認することができます。表示されるストリーム数は、GPU の現在の状態、“GPU Stream” の設定、それから後述するその他の制限事項等が考慮されています。
[Transcoding progress] ダイアログ:

[Live Statistics] タブ:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
SDK については、次の一行を記述することで GPU エンコーディングが有効になります:
H264EncodeDevices.EnableGpuEncoding = true;
同様に、H264EncodeDevices でスタティック API を用いることで、CUDA デバイスを有効または無効にしたり、“GPU Stream” 数を制御することができます:
H264EncodeDevices.Devices[0].Enabled = true;
H264EncodeDevices.MaxNumberGPUStream = 5;
これらの API はアプリケーションの現在のインスタンスに作用します。また、対応するGUIの設定項目とは異なり、存続しません。
最後に、各ストリームが GPU または CPU のどちらでエンコードされたかについては、Job.EncodeProgress イベント経由でアクセスすることができます。
制限事項
1. 現在、GPU エンコーディングがサポートされているのは、CUDA v1.1 以上が搭載されている、Nvidia GeForce、Quadro および Tesla-クラスのボードのみとなっています。Nvidia CUDA テクノロジーの詳細についてはこちらを参照してください。また、CUDA サービスへのダイレクト アクセスが必要です。CUDA サービスへのダイレクト アクセスにより、Teslaクラスのボード (詳細については後述) を使用した、リモート デスクトップ環境またはサービス単体としての動作が可能になります。
2. 今のところ、サポートされているエンコードは H.264 エンコードのみとなっています。たとえば、MP4 および H.264 ベースの IIS スムース ストリーミング (Live および Transcoding モードの両方) などがあります。
3. 複数個の GPU が有効なのは複数のストリームのエンコード処理を行う場合のみです。つまり、単一のストリームエンコードの場合は 1 つだけの方が効率的です。
4. GPU エンコーディングでは間接的なパフォーマンスの低下が見られますが、200 程度のスキャン ライン(縦方向ピクセル数)のエンコードであればほとんど影響はありません。そのため、この程度のスキャン ラインであれば CPU で十分対応できます。このため、スキャン ラインが 204 未満のビデオ ストリームのエンコードは自動的に CPU によって行われます。
5. Adaptive B-Frames と Reference B-Frames については、今のところ、GPUベースの H.264 エンコーダーではサポートしていないため、これらの設定は無視されます。
6. GPU が関わったエンコーディングと純粋に CPU のみのエンコーディングでは出力のクォリティに差が出ますが、これはそれぞれの実装の違いが要因となっているため、想定された動作と考えてください。たとえば、GPU出力の場合、輪郭はあまりぼやけません。そのため、エンコードがしにくくなり、結果として、ビットレートが不十分な場合、圧縮による画像の乱れが生じやすくなります。
7. メモリの制約上、HD IIS スムース ストリーミングは 4GB を超える RAM を搭載した 64 ビット環境でしかエンコードを実行しないなどのような、メモリバインドシナリオの実行を推奨します。また、SDK を使ったアプリケーションの場合は、LARGEADDRESSAWARE 設定の使用を強く推奨します。この設定を使用することで、メモリをできるだけたくさん使用できるようになります。詳細については、こちらの投稿を参照してください。
GPU エンコーディングを最大限に活用する方法
トランスコーディング パイプラインにおけるエンコーディングのボトルネックは、たいていの場合、GPU の使用により解消できますが、残念ながら、GPU を使ってエンコードを実施することで、メインとなっているボトルネックが別の場所に移動してしまうことがあります。もちろん、私たちは、ビデオパイプラインからプロセッシング ボトルネックを解消する方法を日々追及しています。
以下は、GPU エンコーディングでベスト パフォーマンスを得るためのガイドラインです:
· 用途にあった適切な GPU を使用する: ハイパフォーマンスサーバー/データ センターには Tesla、プロフェッショナル ワークステーションには Quadro、コンシューマーおよびマニア用 PC には GeForce。
· Nvidia Webサイトから直接、ビデオ カードの最新ドライバーを入手する。
· GPU エンコーディングでは GPU と CPU の最大処理能力が要求されます。そのため、PC 周りの空気の流れを遮ることのないよう配慮し、また十分な電力を確保する必要があります。
· その PC に合った GPU を使用する: ハイエンド PC にはハイエンド GPU、ローエンド PC にはローエンド GPU。たとえば、ローエンド のデュアル コアに $500 の GPU を追加しても、パフォーマンスの向上は $100の GPU を追加した場合とあまり変わりません。GPU が変わっても、ボトルネックになっているのは CPU だからです。その一方で、ローエンド の GPU を搭載したトップエンドのデュアル Quad Xeon で GPU エンコーディングを有効にした場合は、逆にエンコーディングの処理速度が低下する場合があります。
· 十分な GPUメモリを確保 (多ければよいというわけではない)、特に HD へのエンコードの場合。1GB 以上のメモリを搭載したビデオカードを推奨。
· 前処理設定を調整する: Expression Encoder のデフォルトでは、最高品質の前処理アルゴリズム (別名: “Auto adaptive” デインターレーシング、“Super Sampling” リサイジング等) に設定されています。新しいエンコーディング パイプラインのボトルネックはこの前処理の可能性が高いと考えられるため、リサイジング アルゴリズムを bi-cubic に切り替えることで、エンコーディング プロセスの処理速度の大幅な改善が期待できます。
· Encoder 4 SP1 には新しいデインターレーサー、“Selective Blend” が実装されています。Pixel Adaptive ではパフォーマンスを上げるためにこのデインターレーサーの使用を強く推奨します。
· 私たちが行ったパフォーマンス テストでは、GPU が複数個ある場合、SLI コネクタで互いに接続しない方が高いパフォーマンスを得ることができるという結果が出ています。そのため、SLI コネクタを取り外した方がよいでしょう。詳細については、ビデオ カード メーカーの指示を参照してください。
· GPU と CPU の負荷分散が適切に行われるよう、[Options] ダイアログの [Lower process priority during encode] チェックボックスのチェックを外すようにしてください。
RDP と “ Running As a Service ” の問題
CUDA を使用するアプリケーションは (Expression Encoder およびその SDK を使用するアプリケーションなど) は CUDA デバイスにダイレクト アクセスする必要があります。そのため、後述のいくつかの例外を除き、ほとんどの種類のビデオ ドライバー仮想化で GPU エンコーディング機能を無効にしています。たとえば、VPC、HyperV、リモート デスクトップ (RDP) およびサービスとしての実行等のシナリオが該当します。なお、CUDA デバイスは、一旦、プロセスによりインスタンスが生成されると、その後もずっとそのプロセスから利用できます。つまりどういうことかというと、たとえば、あなたがエンコード処理をローカルワークステーション上で開始し、処理をロックした後、RDP を実行したとします。このとき、あなたは RDP セッション内の CUDA デバイスにはアクセスできませんが、エンコーディング プロセスからはアクセスすることができます。
ただし、エンコーディング プロセスをリモートまたはヘッドレス実行 で開始する必要がある場合、いくつか選択肢が用意されています (ただし、ハードウェアとソフトウェアの組み合わせが適切である場合に限ります)。
リモート アクセス /RDP:
· 最適化や便利さという点では RDP に比べてやや劣りますが、VNC や Live Mesh のような GPU へのアクセスを可能にするリモートアクセス システムの使用が可能です。
· [Tesla only] Tesla Computer Cluster (TCC) ドライバーを使用すると、RDP 経由による CUDA デバイスへのアクセスが可能になります。TCC ドライバーの詳細については、こちらを参照してください。
サービスとしての実行 :
· [Tesla only] Tesla Computer Cluster (TCC) ドライバーを使用すると、サービスとして実行される CUDA デバイスへのアクセスが可能になります。TCC ドライバーの詳細については、こちらを参照してください。
Tesla Computer Cluster (TCC) ドライバーを有効にする方法
1. Tesla ドライバーが最新のドライバーであることを確認します (263.06 以降)。これより古いドライバーだと、次の手順で失敗するため、バージョンの確認は必ず行ってください。
2. 管理者として実行するコマンド プロンプトから、%ProgramFiles%\NVIDIA Corporation\NVSMI に移動し、以下の処理を実行します。
Nvidia-smi –g 0 –dm 1 (0 は Tesla カードのデバイス ID です)
3. TCC モードが有効になったら、システムを再起動します。
4. デバイスの順序を変更する可能性のある修正がハードウェアに対して行われた場合は、その都度、すべての処理を繰り返します。
TCC ドライバーの詳細については、こちらを参照してください。
以上は、テスト段階において話題になっている情報ですが、これら制限事項については、今後も、さらに多くの選択肢が提案されていくことは間違いありません。
推奨の PC 構成
ソースのデコード、前処理オペレーションの実行にはやはり CPU が集中的に使われるため、マルチ コアCPU を搭載することで GPU エンコーディング プロセスをかなり効率化することができます。もちろん、パフォーマンスは、ソースや設定内容によって大きく変わるため、以下の推奨事項はあくまでもおおまかなガイドラインとして参考にしてください。
メモリとストレージ
Expression Encoderは 32 ビット メモリ アドレッシングに限定されるため、複数のエンコーディングプロセスを並行して実行しない限り、6 から 8 GB の RAM で十分です。
ただし、ビットレート (25 Mbps 以上) の大きいソースの場合などに、ハード ドライブのスループットがボトルネックになることがあります。その場合は、ストライプモードの SSD および/または Raid 配列を使用すると状況を改善できます。いずれにしろ、ベスト パフォーマンスを得るには、ソースおよびターゲット ファイルの両方にローカル ストレージを使用することを推奨します。
CPU と GPU
はじめに、用途にあった適切な GPU を使用するようにします。たとえば、ハイパフォーマンス サーバー / データ センターの場合は Tesla、プロフェッショナル ワークステーションの場合は Quadro、コンシューマーおよびマニア用 PC の場合は GeForce 等です。基本的に、GPU エンコーディングのパフォーマンスは CUDA コア数によって決まることがほとんどです。たとえば、GeForce GT220 が持つ 48 個のコアは、Tesla C2050 の 448 個のコアに比べると少なく思えますが、パフォーマンスはかなり高くなります。
シナリオ #1: ホーム PC/ラップトップ上におけるワンストリーム MP4 エンコーディング
GPU を適切に併用すると、ほぼすべての PC で CPU 単体でのエンコーディングに比べて 1.5 から 3 倍のパフォーマンス改善を実現できます。1GB のメモリを搭載した GeForce クラスのボードと最低 128 個、あるいはそれ以上の CUDA コアを推奨します。もちろん、CUDA コア数は多ければ多いほど、高いパフォーマンスを得ることができます。
シナリオ #2: ライブ エンコーディング/スムース ストリーミング ワークステーション
1 枚または 2 枚のミッドエンド/ハイエンドの Quadro ボードまたは Quadro と Telsa の組み合わせによりハイエンド Core i7 ベースのワークステーション相当のパフォーマンスを得られます。通常、2 ~ 3 倍のエンコーディング速度を実現できます。
シナリオ #3: エンタープライズレベルのライブ/オフライン エンコーディング
どの程度のパフォーマンスを必要とするかによりますが、ハイエンドのデュアル Xeon サーバー ブレードを高速化し、HD エンコーディング速度を 3 倍にするには、1 から 2 枚のハイエンド Tesla ボードが妥当です。この場合、エンコードのサービスとしての実行や RDP 経由によるリモート エンコーディングの制御も可能になります。
上記のようなシナリオにおいて、ハードウェアとパフォーマンスの関連性をより深く理解してもらえるよう、私たちは数台のマシンをテストして、GPU を併用したエンコーディングと CPU 単独のエンコーディングの比較を行いました。詳細については、こちらのパフォーマンス レポートを参照してください。また、Live Performance Tool も更新され、GPU エンコーディングに対応できるようになっています。
トラブルシューティング
以下は GPU エンコーディング時に発生するよくある問題に対するソリューションです。
問題 : エンコーディング中、GPU のストリーム数が常に 0 である。
解決策 :
1. Expression Encoder 4 Pro がインストールされていることを確認し、さらにプロジェクトが H.264 をエンコードする設定になっていることを確認します。
2. Nvidia Web サイトから入手した最新版のビデオ ドライバーをインストールしていることを確認します。
3. [Tools] – [Options] – [Other] を実行して Nvidia GPU が CUDA v1.1 に対応していることを確認し、[GPU Encoding] チェックボックスにチェックを付けます。お使いの GPU の詳細については、GPU-Z や CUDA-Z 等のツールを使用することで確認できます。
4. 200 を超えるスキャン ラインを持つストリームが少なくとも 1 つ以上あることを確認します。
問題 : GPU エンコーディングが “Not enough memory” エラーで失敗する。
解決策 :
1. Expression Encoder Pro を除くすべてのアプリケーションを終了した後で、再度、エンコーディングを実行します。
2. Nvidia Web サイトから入手した最新版のビデオ ドライバーをインストールしていることを確認します。
3. 複数のストリームをエンコーディングしている場合は、ビデオ プロファイルでストリームを数個削除するおよび/または [Tools] – [Options] – [Other] ダイアログの “GPU Stream” 設定を小さくします。
4. 上記の手順を実行しても問題が解決しない場合は、GPU エンコーディングをオフにしてから再度エンコードを実行します。
問題 : PC が応答を停止し、ビデオ ドライバーがクラッシュ、さらに OS はブルースクリーンを表示または再起動する。
解決策 :
1. Nvidia Web サイトから入手した最新版のビデオ ドライバーをインストールしていることを確認します。
2. PC の周辺を確認し、空気の流れを遮るようなものがないことを確認します。また、電源の供給が十分であることも確認します。PC Wizard や GPU-Z のような外部のツールを使用すると、各コンポーネントの温度を監視することができるため、空気の流れの問題かどうかの切り分けに役立ちます。
問題 : GPU エンコーディングが思ったより時間がかかる。
解決策 :
1. Expression Encoder Pro を除くすべてのアプリケーションを終了した後で、再度、エンコーディングを実行します。
2. Nvidia Web サイトから入手した最新版のビデオ ドライバーをインストールしていることを確認します。
3. タスク マネージャーや GPU-Z のようなツールを使って CPU および GPU の稼働状況を監視します。
a. GPU の負荷が非常に高く、CPU の使用率が低い場合: [Tools] – [Options] – [Other] ダイアログの “GPU Stream” 設定で、GPU がエンコードするストリーム数を少なくして、マルチストリーム エンコードにおける GPU ボトルネックを小さくします。また、パフォーマンスを最大限引き出すには GPU のアップグレードも有効です。
b. エンコーディング中、GPU が最大クロックで動作していない場合: OS のパフォーマンスの設定が「高」に設定されていることを確認します。場合によっては、使用電力を制限する目的で、システムが GPU の “スロットル” ダウンを行っていることがあり、これがパフォーマンスの低下の原因になっていることがあります。その場合は、お使いの PC メーカーに問い合わせの上、解決方法を確認してください。
c. CPU の負荷が非常に高く、GPU の使用率が低い場合: CPU の負荷を軽減するため、前処理オプション (デインターレーシング、リサイジング等) の変更を検討してください。また、GPU がエンコードするストリーム数を増やすと、パフォーマンスをアップさせることが可能です。
d. CPU と GPU の両方の負荷が低い場合: この場合、エンコーダー コンポーネントの外に (おそらく、ソース アクセスかでコーディング) ボトルネックがあることを意味します。できれば、ローカル ソースまたはターゲットを使用してください。また、処理効率はデコーダーによって違います。そのため、[Tools] – [Options] – [Other] ダイアログから、使用するコーデックを変えてみてもいいかもしれません。