How to use Lucene.Net in Windows Azure
How to use Lucene.Net in Windows Azure
What is Lucene
Apache Lucene is a free/open source information retrieval software library, originally created in Java by Doug Cutting. It is supported by the Apache Software Foundation and is released under the Apache Software License.
What is Lucene.Net
Lucene.Net is a source code, class-per-class, API-per-API and algorithmatic port of the Java Lucene search engine to the C# and .NET platform utilizing Microsoft .NET Framework.
How to use Lucene.Net
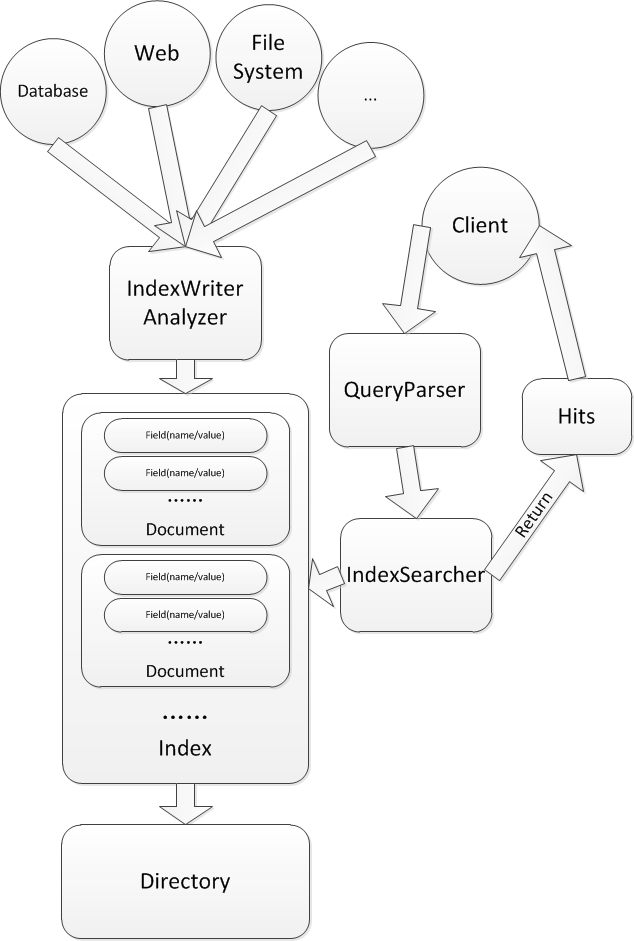
Key concepts in Lucene\Lucene.Net
1. IndexWriter: An IndexWriter creates and maintains an index.
2. Document: The logical representation of a Document for indexing and searching.
3. Field: A field is a section of a Document. Each field has two parts, a name and a value.
4. Analyzer: An Analyzer builds TokenStreams, which analyze text. It thus represents a policy for extracting index terms from text.
5. Directory: A Directory is a flat list of files.
6. IndexSearcher:Implements search over a single IndexReader.
7. QueryParser: a lexer which interprets a string into a Lucene Query.
8. Hits:A ranked list of documents, used to hold search results.
Code sample:
First of all, we need check out the latest version of Lucene.Net using SVN from here.
Next, add reference to Lucene.Net library in downloaded file for your projects.
And code below is straightforward.
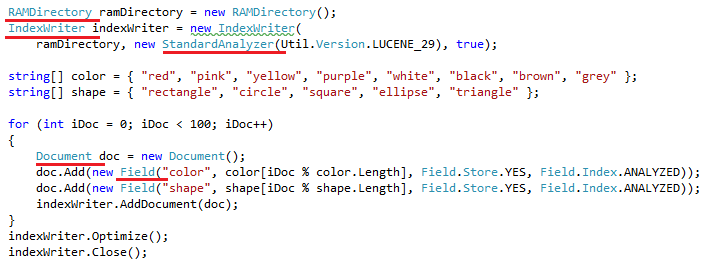
How to create index:
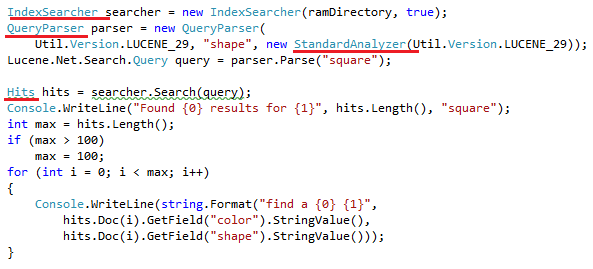
How to search:
What is Azure library for Lucene.Net
Azure library for Lucene.Netallows you to create Lucene Indexes via a Lucene Directory object which uses Windows Azure Blob Storage for persistent storage. In another word, it implements a class derived from Directory class.
How to use Azure library for Lucene.Net
Download it from here. There is a testing project in the solution, but we need to modify the project before we can build and run it.
Open the App.config file in the testing project, locate the appSetteings tag, and change the settings according your storage account.

Remove the code in Line67 and line 68 in Program.cs.
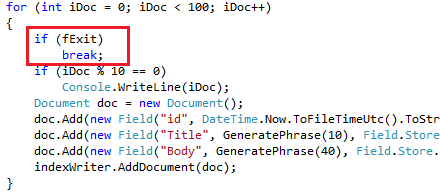
Remove the reference to Lucene.Net.dll both in AzureDirectory project and the testing project. Add the Lucene.Net project to Azure library for Lucene.Net solution; add the reference to Lucene.Net project for your AzureDirectory project and the testing project.
Finally, we can build and run it. The program adds 100 documents (each document contains 3 fields) to index, and performs some searching job later every time.
Concurrence issues
If we run multiple instances of the testing project, your indexes in Blob will lead to an inconsistent state. With running multi-instances for computing or storage, Windows Azure provides us extremely strong power to handle massive-demand situations.
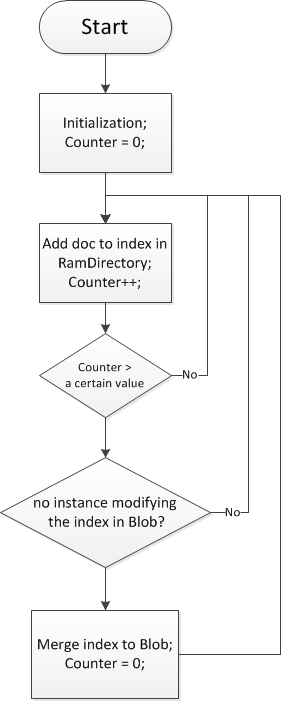
One solution: we hold index in memory temporarily and maintain a counter which indicates the number of documents in the index. If the counter becomes greater than a certain value, we will check whether no instance is modifying the index in Blob Storage at that time. If thus, we merge the index in memory to the one in Blob storage. Otherwise, we quit the checking process, continue adding documents, and then check again later.
Conclusions
Lucene (an information retrieval software library which has a quite high demand of computing and storage) and Windows Azure (a platform which provides nearly unlimited power of computing and storage with pay-as-you-go pricing model) are obviously a perfect match.
References:
https://en.wikipedia.org/wiki/Lucene