Azure + Bing Maps: Designing a scalable cloud database
This is the third article in our "Bring the clouds together: Azure + Bing Maps" series. You can find a preview of live demonstration on https://sqlazurebingmap.cloudapp.net/. For a list of articles in the series, please refer to https://blogs.msdn.com/b/windows-azure-support/archive/2010/08/11/bring-the-clouds-together-azure-bing-maps.aspx.
Introduction
The Plan My Travel sample is designed to be used by 1,000 users during non-holiday seasons, and used by 1,000,000 users during holiday seasons, as described in the previous post. That's the most important reason why we choose a cloud solution. A cloud solution environment like Windows Azure provides out-of box support for dynamical scalability. However, an application still needs to be carefully designed in order to leverage the scalability feature. In this post, we'll focus on storage.
Scalability in table storage
When it comes to entity data storage, Windows Azure platform provides both table storage and SQL Azure. As described in the last post, table storage provides out of box support for horizontal partitioning. Even though we've chosen SQL Azure as our data storage, it doesn't harm to review how table storage achieves horizontal scaling.
Every entity in table storage has a partition key and a row key. The row key can be viewed as ID in traditional database storage systems, which uniquely identifies the entity within the partition. It is the partition key that makes table storage different.
Within a single storage account, all entities with the same partition key are stored on the same server. But entities with different partition keys are stored on different servers. The current architecture allows you to perform up to 500 transactions per second on a single server (partition), where a transaction means a successful CRUD operation. That means if all data are stored in the same partition, and you must perform 501 concurrent requests, the 501th request must wait until one of the previous requests completes.
But does it mean if the entities are stored in 10 partitions, you can perform up to 5,000 concurrent requests per second? Well, this depends... Within the 5,000 requests, if it happens there're 500 requests querying partition1, 500 requests querying partition2, and so on until partition10, the above assertion is true, because the requests will be load balanced evenly to all 10 servers. But this is rarely the case. In the worst case, if all 5,000 requests are querying a single partition, still only 500 requests can be performed in 1 second.
On the other hand, what if I put each entity in its own partition? Do I get max performance? Well, not exactly. Very often, we need to query a range of data. Ideally, we only want to issue a single query. But keep in mind that different partitions are stored on different servers. So if our 100 entities are stored on 100 different servers, we have to issue 100 queries to obtain all of them! In addition, cross partition transaction is not supported today.
So the key to design a scalable storage system with table storage is to choose a good partition key. It should not be too big, to allow efficient load balancing to multiple servers. But it should not be too small as well, so that we can use a single query to obtain the data we need.
For more information about the scalability of table storage, please refer to this storage team's blog post.
Scalability in SQL Azure
As described in the last post, SQL Azure doesn't provider out of box support for horizontal partitioning. All data in the same database is stored in the same server, and actually multiple databases may share a single physical server, depending on their sizes. So how do we design a scalable database for SQL Azure?
The answer is, why not learn from table storage?
We can create multiple databases, one serves as a partition. The database name is the partition key, and within each database, we just use our normal ID as the row key. This approach of course introduces some challenges in data accessing, because unlike table storage, in SQL Azure, you must manually write logics to query the correct database. But it worth the effort if this approach allows us to scale out our solution. Without it, SQL Azure may soon become the bottle neck of out cloud solution...
However, there's another problem. In table storage, you pay for what you actually store. But in SQL Azure, you pay for how many databases you own. Our previous approach forces us to create a lot of databases at the very beginning, where there're not too many data. The initial cost is too high. This is something we want to avoid. Ideally, we want to use a single database at first. As we have more and more data, we will move to create more databases, and possibly migrate certain data to the new database.
So our final approach is to create each table with a complex primary index. The primary index contains both partition key and row key. At first, we store all data in the same database to save money. As we have more and more data, or if a single database is not capable of serving all the concurrent requests, we will create a new database with exactly the same tables and same schemas, and move one or more partitions to the new database. The data migration takes time, but it is a one-time operation, so it is acceptable.
Hopefully in the future, SQL Azure will also support horizontal partitioning out of box, so we don't need to do so many manual work.
Design the database for Plan My Travel
Now let's show you the database design of the Plan My Travel application.
Since our application's data storage is relatively simple, we only need to create a single table named Travel. This table contains the following columns:
- PartitionKey: A string represents the created user
- RowKey: A GUID uniquely identifies the row
- Place: A string represents the name of the travel stop
- GeoLocation: A spatial data represents the location of the travel stop. See our next post for more information
- Time: A datetime represents when the user plans to travel to this stop
We choose the created user as the partition key. It works for our current design. We usually queries data on per user basis. So one query can be done within a single round trip. As more and more data are gathered, we will move the data for certain users to new databases. So if the data for 2 different users happen to be located in 2 different databases, the queries will be load balanced.
In the current live demonstration, we have not implemented the user authentication feature. All users share the same travel plan. So the PartitionKey's value is just a place holder. As future posts are made in this series, we will implement the authentication feature.
Create the table
There're several ways to create tables in SQL Azure. The most common approach is to use the Houston design tool currently available in SQL Azure Labs. Houston is a Silverlight powered visual design tool that provides extensive support to design and manage your SQL Azure databases. Since it is a web application, you can use it almost everywhere, as long as you have internet connection. You don't need to install any software on the client machine as well (except for the Silverlight plug-in, which is already installed on a lot of machines). And the power of Silverlight ensures you have a very nice user experience. For example, you can use the 3D cube to navigate between common database information. You can take advantage of the ribbon to focus on the task at hand.
Since this post is about how to design a scalable cloud database, it assumes you've already used Houston. If not, it is highly recommended to read this post of the SQL Azure team blog. It provides extensive resources for you to get started with Houston.
Using Houston, we can design our Travel table as follows:
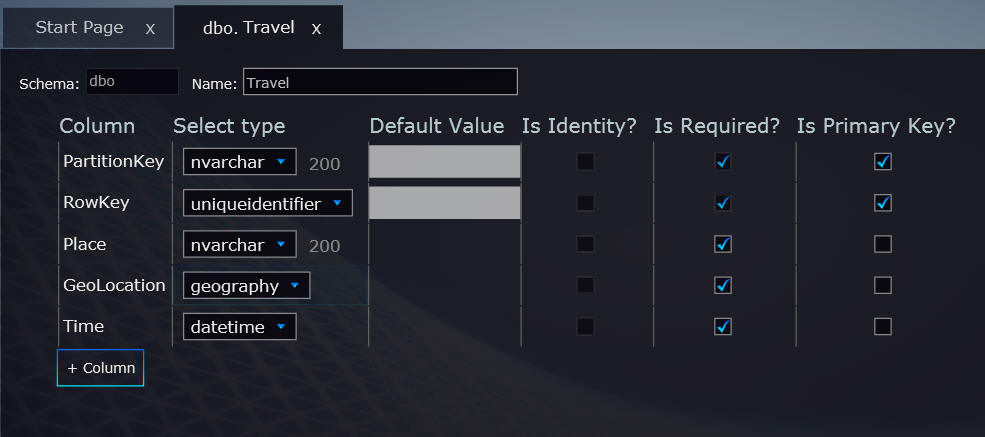
Figure 1 Use Houston to design the table
Alternatively, if you prefer a more tradition approach, you can write the T-SQL script to create the table manually. You can either do that in Houston, or in the traditional SQL Server Management Studio.
CREATE TABLE [dbo].[Travel](
[PartitionKey] [nvarchar](200) NOT NULL,
[RowKey] [uniqueidentifier] NOT NULL,
[Place] [nvarchar](200) NOT NULL,
[GeoLocation] [geography] NOT NULL,
[Time] [datetime] NOT NULL,
CONSTRAINT [PK_Travel] PRIMARY KEY CLUSTERED
(
[PartitionKey] ASC, [RowKey] ASC
),
CONSTRAINT [IX_Travel] UNIQUE NONCLUSTERED
(
[Place] ASC,
[Time] ASC
)
)
Conclusion:
This post describes the considerations of building a scalable database for a cloud solution. It provides a sample on how to horizontal partition the data. The next post will describe spatial data, and how to work with it in SQL Azure.