Modernizing “Did my dad influence me?” – Part 2
In Part 1 we saw how we can capture the LastFM data from the API. This of course just gives me some raw data on an Azure Storage Account. Having data stored on a storage account gives us a wide range of options to process the data, we can use tools like Polybase to read it into Azure SQL Data Warehouse, connect directly from Power BI or when the dataset needs pre-processing or it becomes too large to handle with traditional systems we can use solutions like Azure Databricks to process the data.
In Part 2 we will focus on processing the data, so we can build beautiful dashboards in Power BI. Note that we are going to focus on Azure Databricks even though I do realize that the dataset is not huge, but we are learning remember?
Prerequisites:
Azure Databricks is an easy to use Spark platform with a strong focus on collaboration. Microsoft and Databricks collaborated on this offering and it truly makes using Spark a walk in the park. Azure Databricks went GA recently so we are working in fully supported environment.
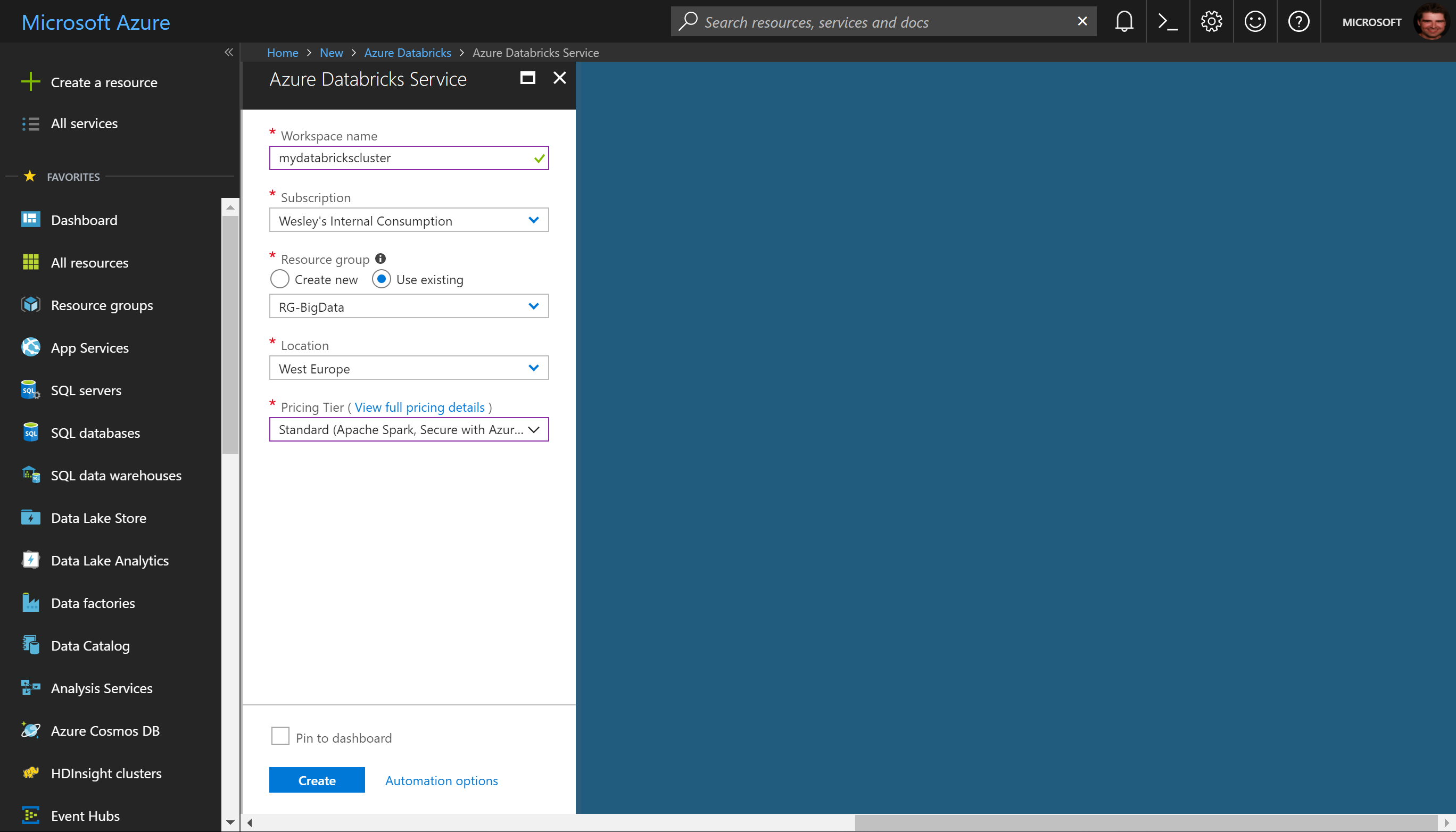
First, we'll create an Azure Databricks Workspace which is simple, all you need is a name, location and the Pricing tier. Azure Databricks is secured with Azure Active Directory which is of course important to align your efforts around identity in the organization. After about a minute you will be able to launch the Workspace. Just push the big "Launch Workspace" button to get started!
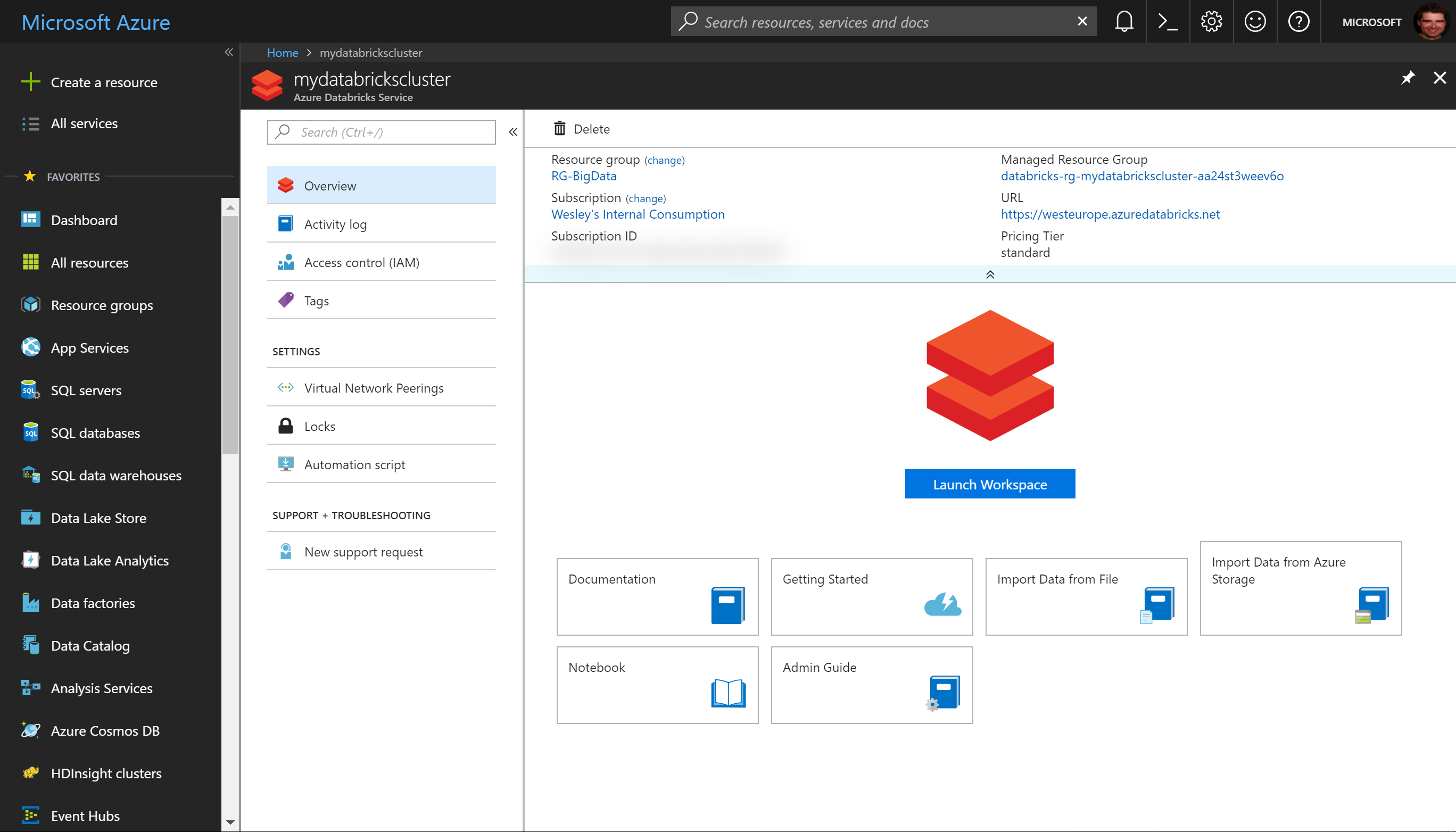
Once you launch the Workspace you will see the Azure Databricks welcome page. There are links immediately on the page to help you get started, and the navigation is on the left side.

The first thing we need to do is create a cluster as we need a place to process the code we are going to write. So let's go ahead and click Clusters - + Create Cluster. For the "Cluster Type" you will have two choices, Serverless or Standard. A serverless pool is self-managed pool of cloud resources that is auto-configured, it has some benefits like optimizing the configuration to get the best performance for your workload, better concurrency, creating isolated environments for each notebook, .... You can read more details about serverless pools here. We are however going to choose for Standard just because Serverless Pools are currently in Beta. Creating a cluster takes a couple of arguments like the name and the version of the Databricks runtime and Python. Now comes the interesting part which is choosing the size of the nodes to support your cluster, this comes with a couple of interesting options like auto scale where you can define the minimum and maximum workers. From a cost perspective it is very useful to enable Auto Termination if you know you will not be needing the cluster 24/7, just tell Databricks after how many minutes of inactivity it can drop the cluster. You can also assign some Tags for tracking on the Azure part, override the Spark configuration and enable logging. 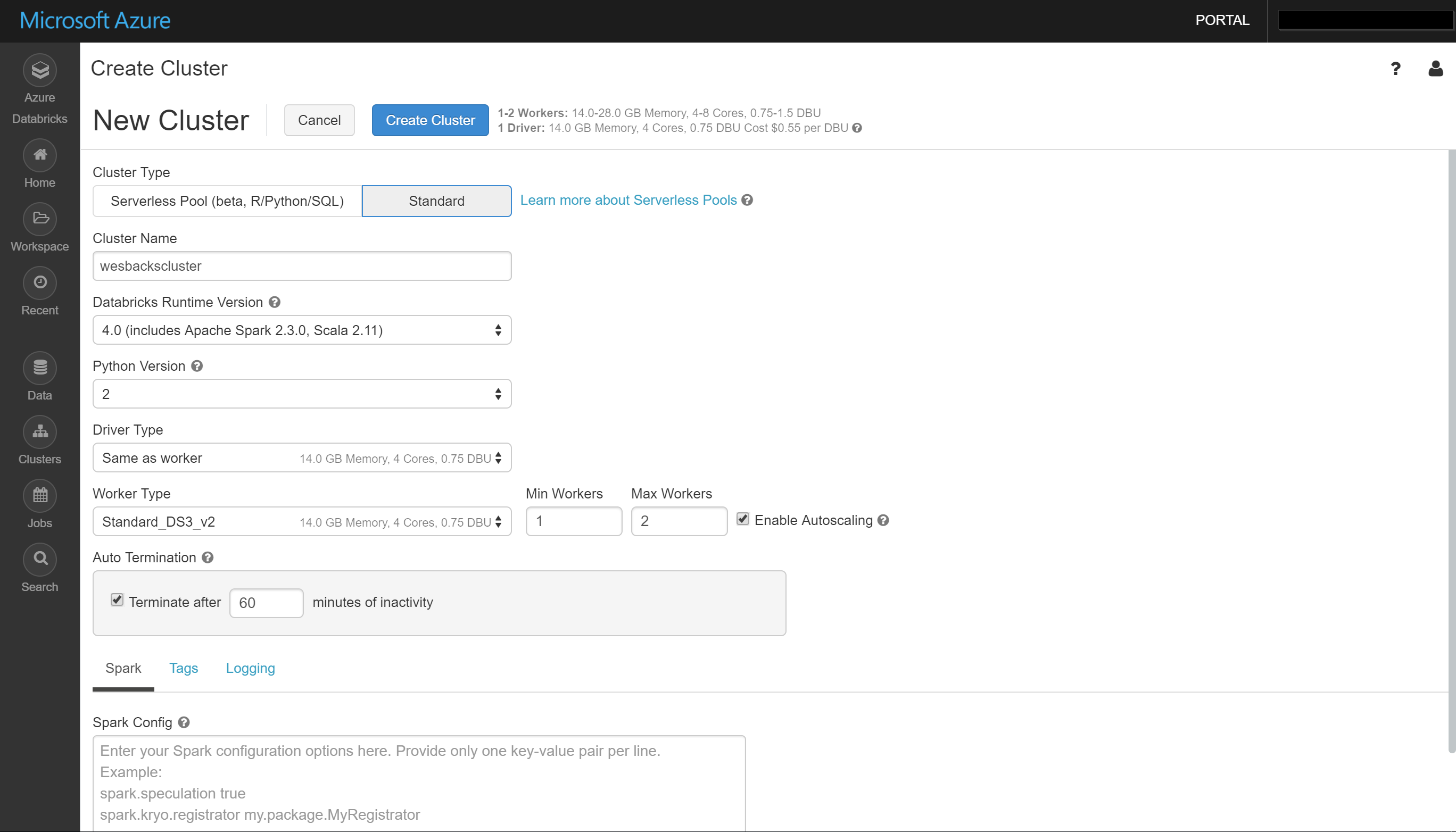
While the cluster is provisioning let's go ahead a start writing code. We'll go back to the Welcome Page and click Notebook under New. I'm going to give my notebook a name and choose the default language, here I'm going for Scala because @nathan_gs was my Spark mentor and he's a Scala fan.
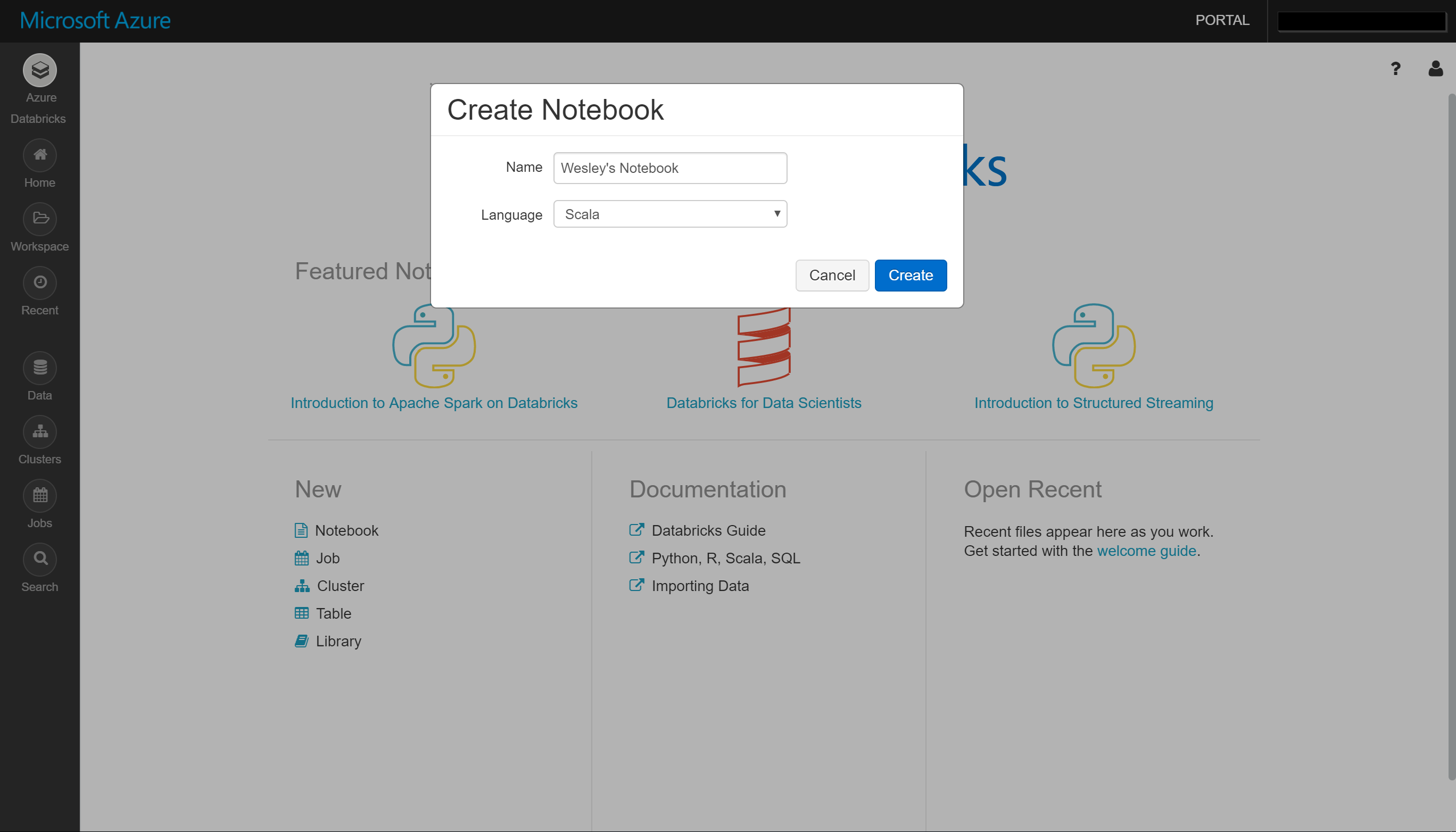
Now we can start to crunch the data using Scala, I'll add the code to the GitHub repo so you can replicate this easily.
Azure Databricks allows you to mount storage which makes it easy to access the data.
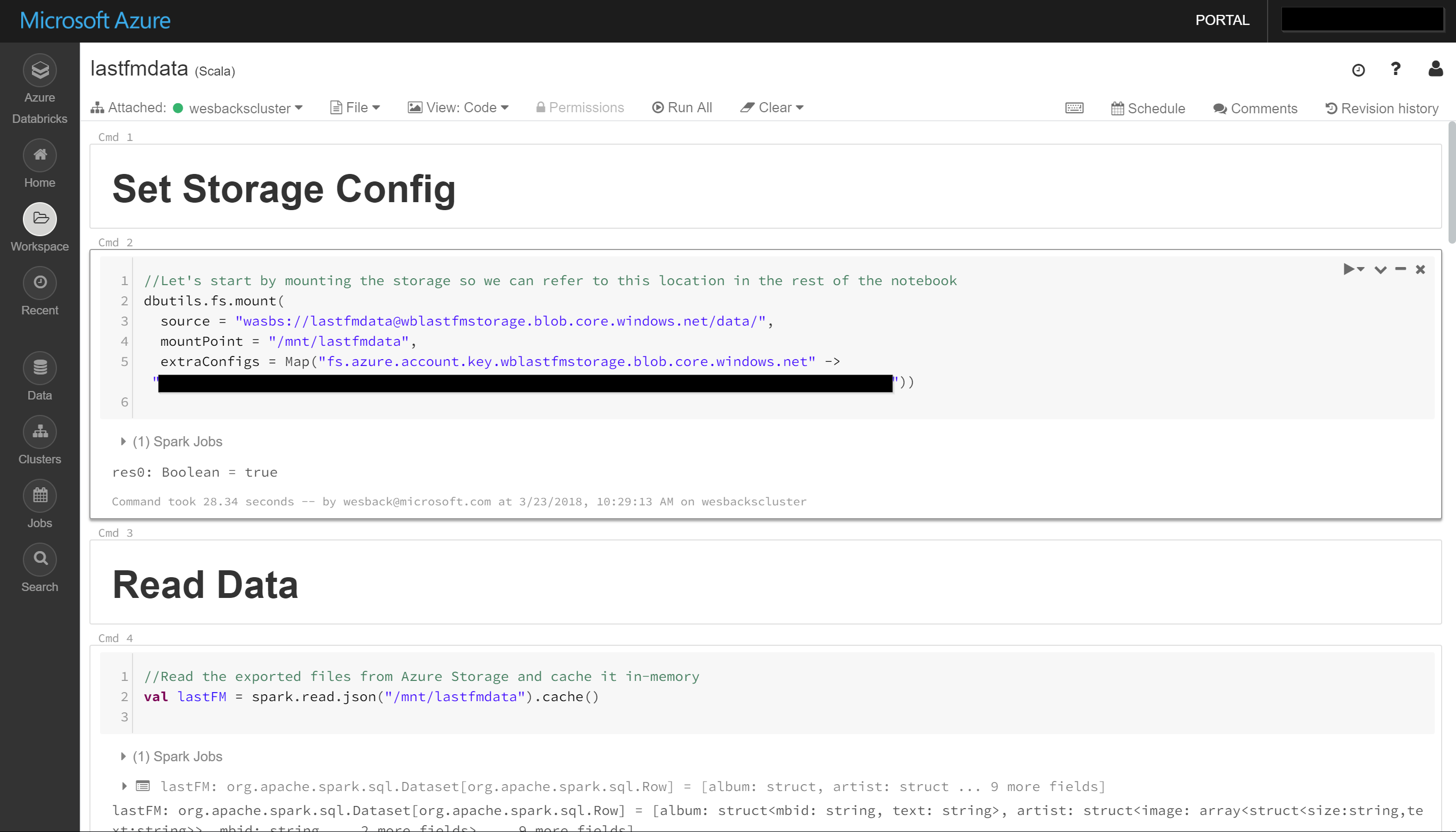
We can also do visualization right inside the notebook which is a great addition while you are doing data exploration.
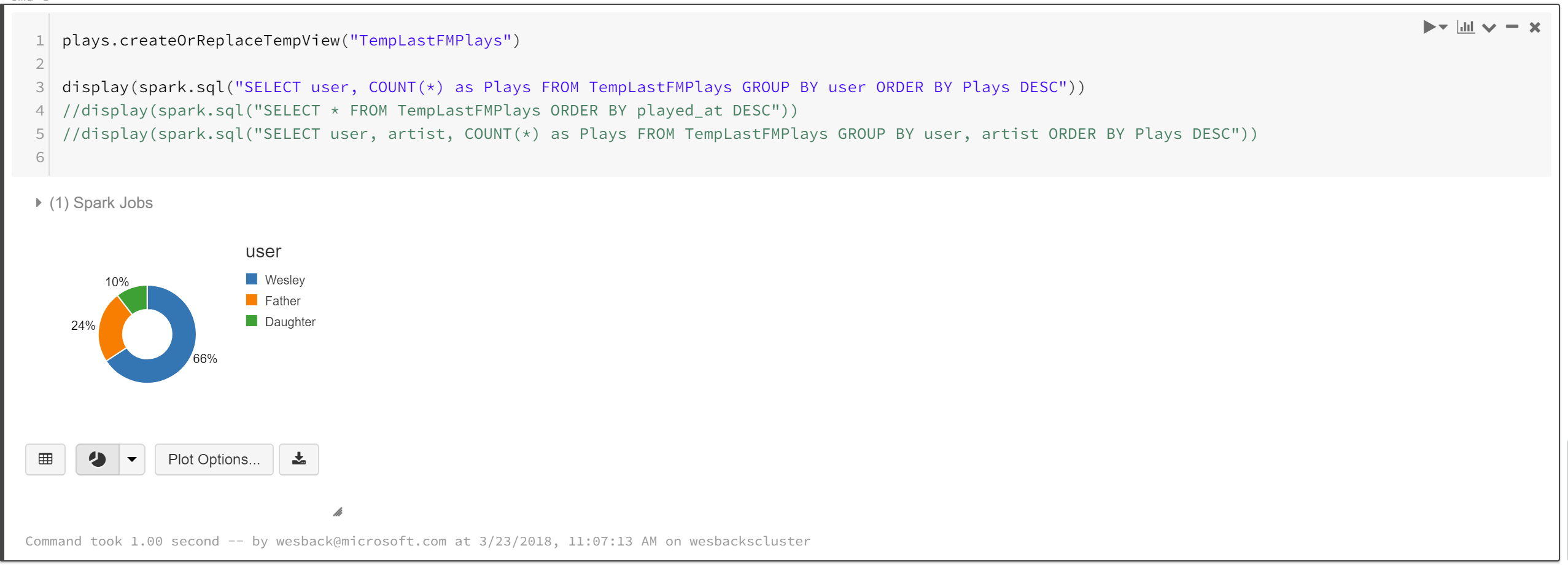
Now we have done some of the data wrangling we can start visualizing the data to get some of the insights and answer the question if my father has influenced me, and whether I am influencing my daughter. Connecting Power BI to Azure Databricks is documented here.
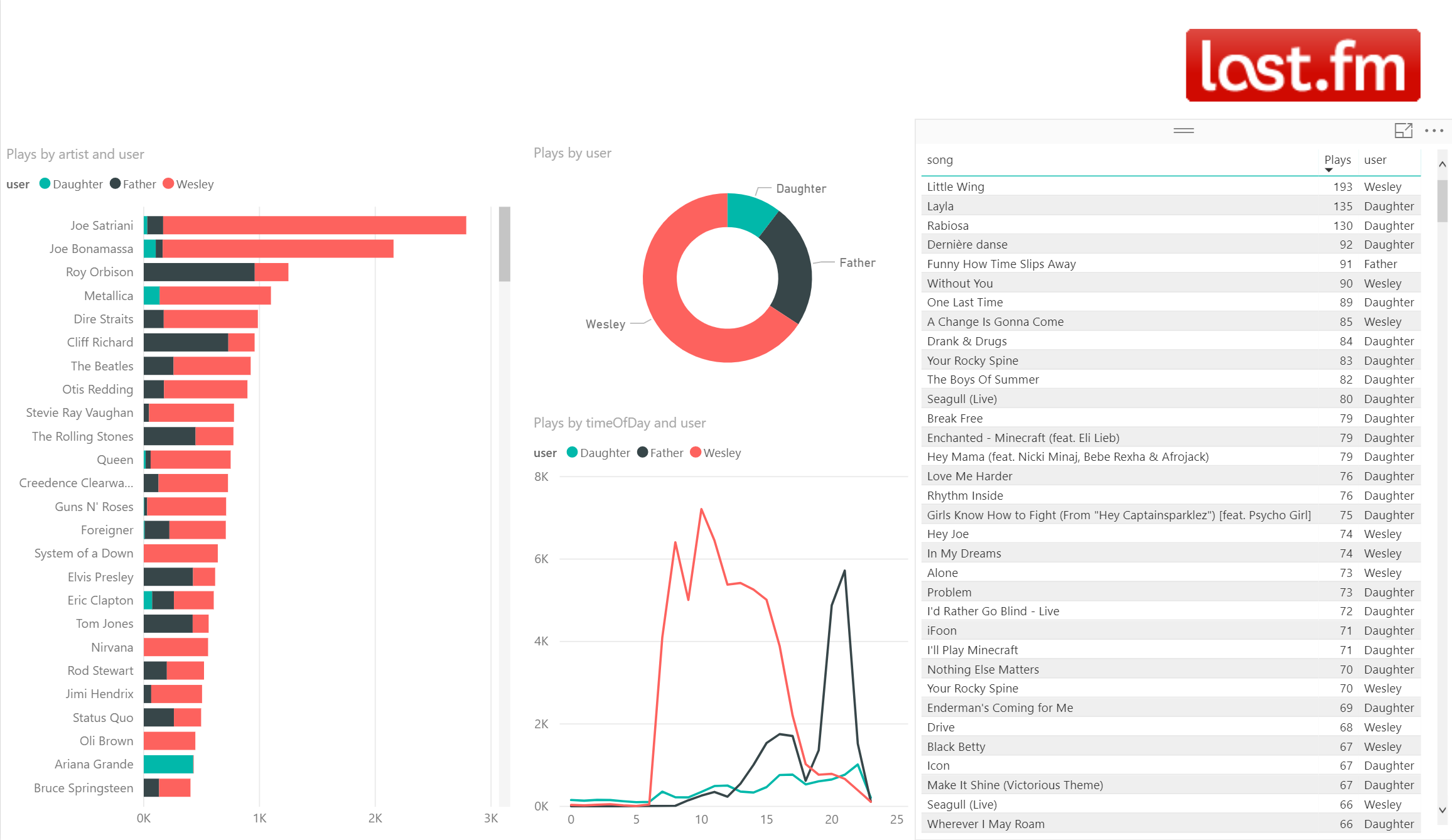 We can see a couple of interesting things now that we have visualized the data. It looks like there is quite some overlap between what I'm listening and what my father is listening. On my side I have not been successful in convincing my father of System Of A Down though. I am very happy to see that at least I am having some impact on my daughter too, although she hasn't been able to convince me of Ariana Grande. I am quite proud if you look at some of the top songs my daughter has in her list.
We can see a couple of interesting things now that we have visualized the data. It looks like there is quite some overlap between what I'm listening and what my father is listening. On my side I have not been successful in convincing my father of System Of A Down though. I am very happy to see that at least I am having some impact on my daughter too, although she hasn't been able to convince me of Ariana Grande. I am quite proud if you look at some of the top songs my daughter has in her list. 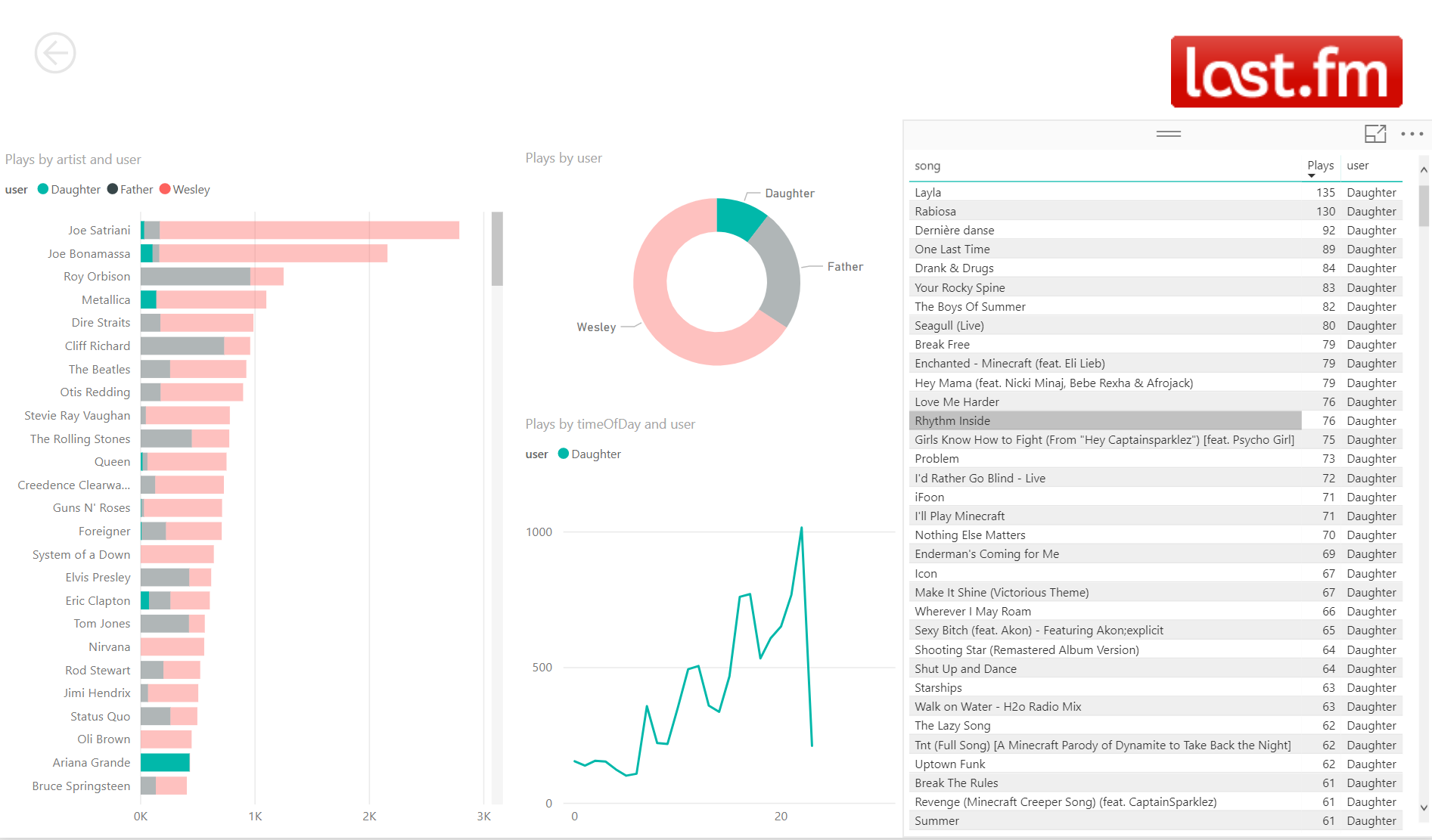
Power BI also allows you to import the data into its own in-memory model which obviously makes sense from a performance point-of-view (given your dataset is not in the terabytes ranges of course). A neat thing you can do if the data is in memory is use Q&A to get insights. This way you can just ask questions to your data instead of building your visualizations with drag & drop.
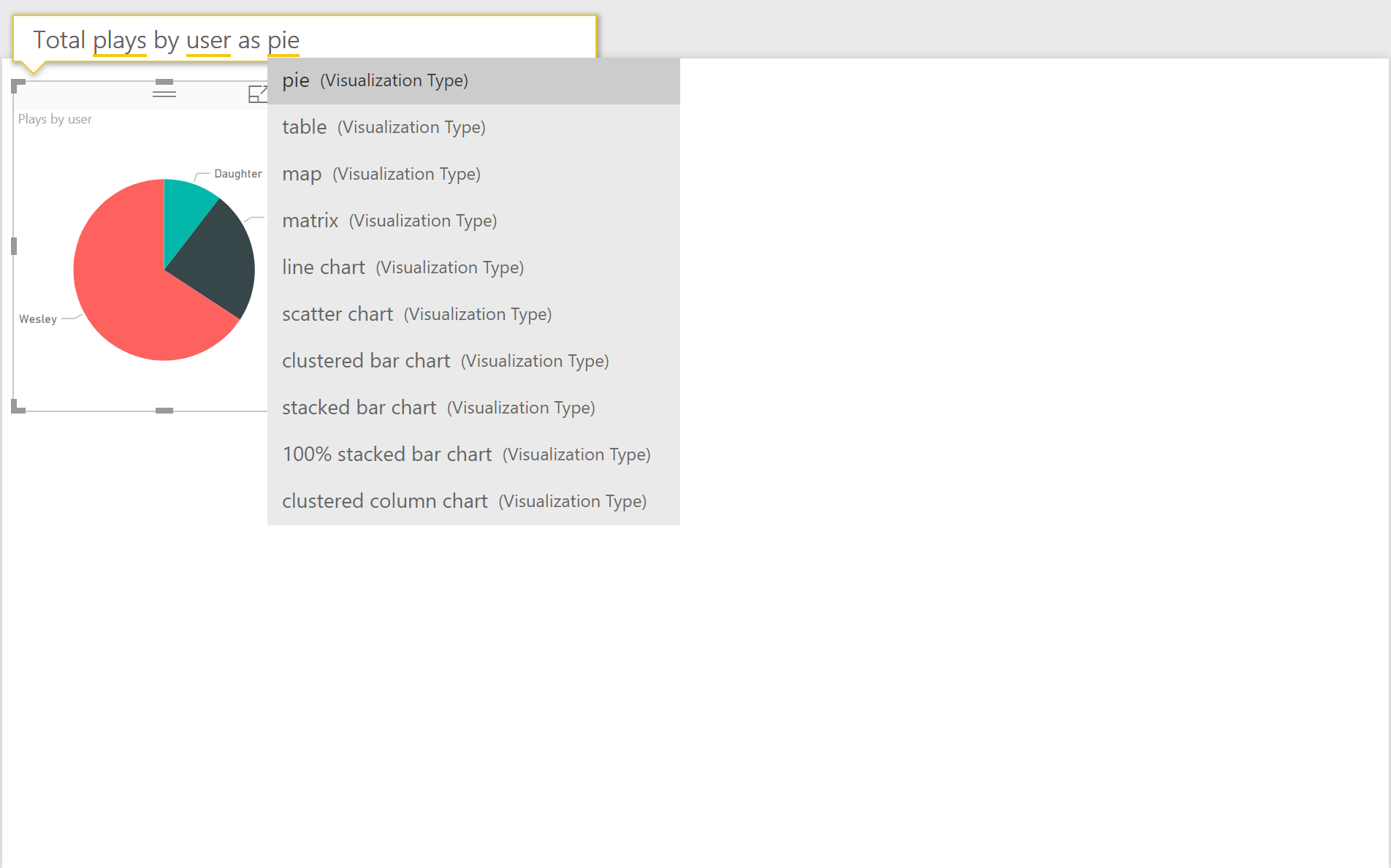
Both Azure Databrick and Power BI have a lot more interesting capabilities obviously, but my post would be endless if I had to dive into all of this.
In Part 3 we will look at how we can use Serverless solutions to automate the deployment of the Docker containers to Azure Containers Instances.