Wordbreakingisacinchwithdata
For the task of word-breaking, many different approaches exist. Today we're writing about a purely data-driven approach, and it's actually quite straightforward — all we do is a consider every character boundary as a potential for a word boundary, and compare the relative joint probabilities, with no insertion penalty applied. A data-driven approach is great because all you need is data, and you're covered: all languages, slang, neologisms and so forth.
The one tricky business with the algorithm as outlined above is that it can be computationally expensive, especially if the pre-word-broken string is long. But with reasonably aggressive pruning, a breadth-first-search is actually quite usable. The coding is nevertheless tedious, so we've prepared two modes by which you can experiment with word-breaking: an interactive Silverlight application, and a REST service. Official write-up is here.
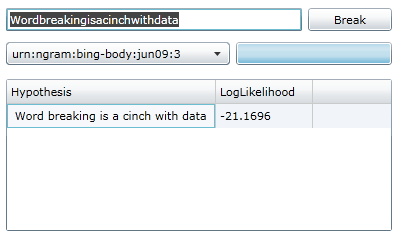
Shown here is a capture from the WordBreaker4Web app, breaking the title of this post:
So what are some applications for such a service? One obvious example is URL or filename breaking. In the case of a domain names, spaces are not permitted so unless you want to substitute hyphens, you're only choice is to string the words together. This leads to rather long domain names such as this [N.B. examples are random, not intended as an endorsement]: insearchoftheworldsmostbeautifulwoman . Or perhaps this Internet meme: penisland, meant to be parsed as pen island, not some other way. As for filename breaking, omission of space characters is still quite prevalent, as you're surely aware.
Other applications exist, too. Hash tags, seen throughout the Internet and quite prominently on Twitter (where we also are, by the way), are by nature words strung together with spaces removed. Here's an example, picking one of the trending terms at random:
C:\bin\curl>curl https://web-ngram.research.microsoft.com/ngramwordbreaker/break.svc/?p=imoneofthosepeople
i|m|one|of|those|people (-16.02505)
im|one|of|those|people (-16.56622)
i|m|oneof|those|people (-17.15775)
im|oneof|those|people (-17.69892)
imone|of|those|people (-17.93192)
For those with sharp eyes will note that the REST service shown above doesn't provide a means to specify a language model. This is because we built an artificial model based on ‘bing-title:apr10:2’ (that's right – bigram) with the n-grams drastically pruned for faster performance at the expense of accuracy. It nevertheless does a fairly decent job. Compare the speed between the REST service and the Silverlight demo app and the effect of the shrunk datset becomes quite obvious.
Does your Department of Licensing word break? Some of you may recall the news about a particular plate getting rejected in Colorado:
C:\bin\curl>curl https://web-ngram.research.microsoft.com/ngramwordbreaker/break.svc/?p=iluvtofu
iluv|tofu (-12.75313)
iluv|to|fu (-14.22803)
So we think it was about 30x more likely that they loved bean curds. But who knows.