Revisitando a Persistência - LINQ, Entity Framework, Object-relational mapping, entre outros.
Olá pessoal, tudo certo?
Falar de LINQ e persistência de dados é mesmo desafiador? Estive navegando pela Web e existem diversos blogs, artigos, whitepapers, pdf's, ppt's, wikis e exemplos que realmente deixam o leitor confuso. E algumas perguntas ainda aparecem no meio da discussão, como: "usando LINQ, onde é melhor colocar minha lógica de negócio, em banco de dados ou em componentes extra banco?" ou ainda "para toda arquitetura devo utilizar um modelo de persistência e mapeamento relacional?" e outras como "Qual a diferença entre LINQ, XPO, SubSonic, Ibatis, Nhibernate ou algo doméstico?".
Bom, este post não pretende esgotar o assunto, mas colocar uma rápida visão sobre o tema, com um foco sobre o ADO.NET Entity Framework e seus componentes. Para começar, vamos rever algumas definições.
Revisitando a persistência
Quando falamos em persistência de dados pensamos no armazenamento "eterno" dos dados, ou seja, enquanto o dispositivo físico de armazenamento dure. Quando se grava um arquivo no disco, por exemplo, o dado está sendo "eternizado" ou "persistido", deixando de ser volátil na memória RAM e passando a ser escrito num dispositivo que armazena a informação de modo que ela não desapareça facilmente.
Assim, podemos dizer que a persistência de dados envolve um meio físico que permita recuperação de dados, como um banco de dados, um arquivo em disco, etc, o que garante a persistência das informações e sua posterior recuperação. Ao longo da execução de um sistema, a persistência de dados é fator crítico, pois determina o modelo de acesso aos dados persistidos, assim como o desempenho, a facilidade de acesso, a dificuldade de manutenção, a capacidade de rastreabilidade dos dados, o modelo de programação, etc.
De modo geral, o modelo de persistência mais comum no mercado é o baseado em banco de dados relacional, onde através de SQL (Structured Query Language), fazemos a navegação pelos dados persistidos. Nossas consultas são escritas em SQL e executadas sobre o banco, para a recuperação de informações específicas. Essa tecnologia é muito madura, difundida e padroniza, porém, apresenta muitos problema de acoplamento com a orientação a objetos. Vamos considerar que a orientação a objetos hoje é o modelo de programação de sistemas dominante. Assim, quando falamos sobre persistir nossos objetos de um modelo OO, falamos da persistência de objetos, o que exige um mapeamento. De fato, a persistência de objetos utilizando um modelo relacional envolve a discussão sobre o chamado Object-Relational Mappings, ou mapeamento Objeto-Relacional.
Revisitando o mapeamento objeto-relacional (ORM - Object-relational mapping)
Como vimos, o mapeamento objeto-relacional é uma técnica que visa diminuir a chamada impedância entre o modelo de objetos e o modelo relacional em banco de dados. Existe muita discussão em torno do assunto, já que alguns aspectos de ambos os modelos são conflitantes. Algumas vezes, você vai desejar um modelo de persistência que simplesmente faça a serialização de seus objetos para armazenamento. Em cenários de longo prazo, onde versionamento dos objetos persistidos é importante, você vai precisar ainda de algum mecanismo mais sofisticado, que faça um mapeamento objeto relacional considerando a versão dos objetos envolvidos.
Mas a necessidade de se tornar transparente a persistência de dados, instâncias de objetos e informações de sistemas OO é uma constante. Frequentemente somos confrotados com a decisão sobre utilizar uma camada de persistência de nossos dados ou simplesmente manter o acoplamento de classes com estruturas relacionais de forma explícita.
Por exemplo, quando pensamos num modelo objeto-relacional, pensamos numa tabela por classe, com artibutos primitivos representados por colunas. Da mesma forma, atributos complexos são representados por múltiplas colunas ou tabelas adicionais. E todo esse mapeamento é feito de forma transparente para o sistema, isolando o desenvolvedor desses detalhes durante a codificação da lógica de negócio. Agora, algumas otimizações ainda podem ser necessárias no modelo objeto-relacional, como reduções e transformações de schemas, para eliminação de colunas redundantes, validações, verbalizações para eliminação de ambiguidades, entre outras.
Visitando o ADO.NET Entity Framework
Depois dessa introdução, vamos falar um pouco sobre o ADO.NET Entity Framework. Ele está disponível através do link abaixo:
ADO.NET Entity Framework Beta 3
Ref.: https://www.microsoft.com/downloads/details.aspx?FamilyId=15DB9989-1621-444D-9B18-D1A04A21B519&displaylang=en
Você ainda vai precisar de um pacote de ferramentas para trabalhar com ele, obtido aqui:
ADO.Net Entity Framework Tools Dec 07 Community Technology Preview
Ref.: https://www.microsoft.com/downloads/details.aspx?FamilyId=D8AE4404-8E05-41FC-94C8-C73D9E238F82&displaylang=en
De fato, o ADO.NET Entity Framework é um pacote que integra as funcionalidades do ADO.NET 2.0 (com seus mecanismos de DataSet, DataAdapter, DbConnection, DbCommand , etc), adicionando 2 novos componentes: o Entity Data Model e o LINQ - Language Integrated Query.
Veja a figura a seguir que representa bem o pacote:
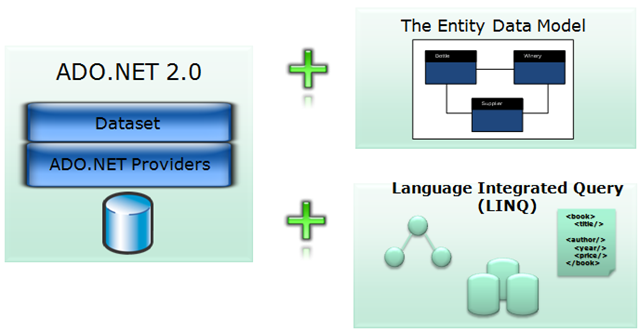
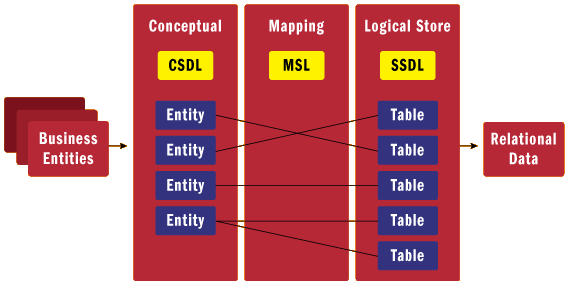
De forma resumida, o Entity Framework permite o mapeamento do modelo relacional para o modelo de negócio orientado a objetos na aplicação. Assim, parte importante da arquitetura do Entity Framework são suas camadas internas: camada conceitual, camada de mapeamento e camada lógica. Essas 3 camada garantem o mapeamento ORM (Object-relational mapping) conforme discutido anteriormente:
No ambiente do Visual Studio, esse mapeamento é disponibilizado através da ferramenta Entity Model Code Generator Tool, instalada com o pacote ADO.Net Entity Framework Tools, citado acima. Veja uma figura da ferramenta em ação:
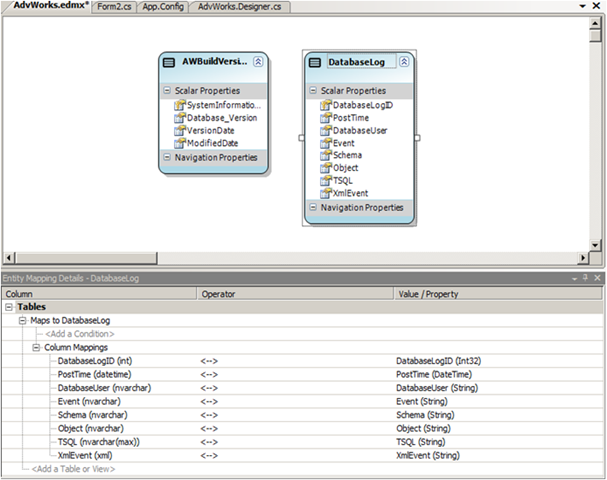
Observamos a parte inferior com o mapeamento entre colunas e propriedades das classes envolvidas no mapeamento objeto-relacional. Esse mapa é mantido pelo EDM - Entity Data Model presente na aquitetura.
Nesse contexto surge o LINQ. LINQ é um conjunto de recursos introduzidos no .NET Framework 3.5 que permite a realização de consultas diretamente em base de dados, documentos XML, estrutura de dados, coleção de objetos, etc. usando uma sintaxe parecida com a linguagem SQL. Como resultado, o desenvolvedor obtêm maior legibilidade no código final, assim como maior transparência sobre os detalhes de implementação de cada fonte de dados.
Assim, sobre o Entity Framework é possível aplicar consultas LINQ em uma de suas variações. Veja:
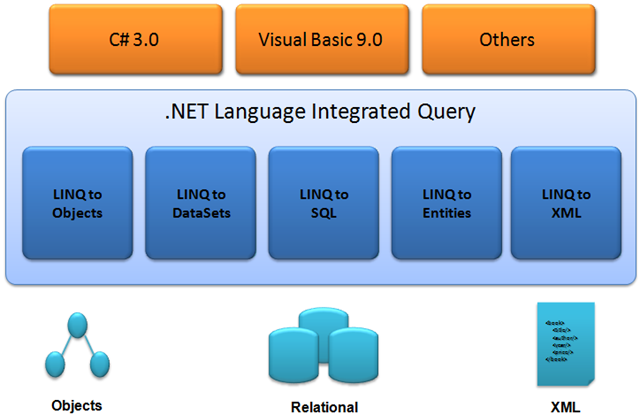
Alguns exemplos de variações LINQ são:
- LINQ to Objects
- LINQ to DataSets
- LINQ to SQL
- LINQ to Entities
- LINQ to XML
Cada variação ainda contempla as características da fonte de dados alvo.
Um exemplo de consulta LINQ to Entities segue abaixo:
string city = “London”;
var query = from c in northwindContext.Customers
where c.City == city
select c;
foreach (Customers c in query) Console.WriteLine(c.CompanyName);
Algumas considerações
Quando devemos utilizar um modelo objeto relacional para a persistência de dados? De fato, alguns desenvolvedores e arquitetos têm iniciado o uso de camadas de persistência ORM em todas as suas soluções. Isso é um erro. Um dos grandes problemas no uso dessa camada é o desempenho final obtido. Muitas vezes, devido a presença de mecanismos de cache durante a execução das consultas e retorno de objetos, uma camada ORM pode significar um desempenho deteriorado para a aplicação. Concordamos que muitos cenários não são aderentes ao modelo ORM por serem críticos quanto ao SLA definido. Nesses casos, o mais indicado é um middleware de banco de dados de alto desempenho. Precisamos entender que existem cenários onde a fronteira entre a lógica de programação e a camada de persistência de dados simplesmente não precisa ser escondida, ao contrário, é importante estar bem definida para os componentes da arquitetura. Um exemplo semelhante ocorreu na discussão do CORBA sobre os objetos distribuídos. As estruturas internas para tornar transparente a localização de um objeto ou esconder o fato de que tínhamos uma rede entre os componentes envolvidos trouxe grande complexidade para algumas soluções, assim como um desempenho ruim em muitos cenários.
Assim, devemos avaliar bem os benefícios de uma camada de persistência objeto relacional em nossa arquitetura, de acordo com as demandas reais de negócio que a solução irá atender. Entre os aspectos que podemos utilizar nessa decisão temos:
- Desempenho
- Manutenabilidade
- Legibilidade
- Rastreabilidade de dados
- Facilidade de Depuração
- Escalabilidade
- Presença de múltiplos bancos de dados na solução
- etc.
Em posts futuros vamos conversar mais sobre o assunto. Fique ligado!
Como referências adicionais, veja os links:
Object-relational mapping
Ref.: https://www.orm.net/ADO.NET Entity Framework & LINQ to Relational Data
Ref.: https://code.msdn.microsoft.com/adonetefx/ADO.NET Team blog
Ref.: https://blogs.msdn.com/adonet/Data Team blog
Ref.: https://blogs.msdn.com/data/
Por enquanto é só! Até o próximo post :)
Waldemir