The Tao of Authentication (Part II)
(continues from Part I)
You can consider this post and the fine grained analysis we made in Part I as a down payment for grasping the implications we'll see in Part III, which I plan to post in few hours (almost done). I was planning to have just 2 parts, but it came out far too long and I need 3 :). Here we'll see a very general architecture that can support the traditional authentication practice we described so far.
Let me refresh your memory with those few key points we established last time:
- When we feel the need of authenticating users before giving access to our application, usually that's because we need the answer to some questions in order to execute correctly the service we are offering
- The question "are you a returning user" can be verified directly by using some mechanism, such as asking to the user to submit credentials. For almost all other questions we need to get an answer that satisfies us without a chance of verifying it directly in-band (messy, but if you read part I you'll understand)
- When we authenticate a user in "traditional" way, we essentially do three distinct things at the same time:
- We answer the question "are you a returning user?" by verifying the credentials
- We link the credentials to a profile in our archive
- We "dehydrate" that profile, and we use its content for answering our other questions
We'll now review what are the architectural components that we customarily use for traditional authentication, that is to say what do we need for performing 1-2-3 above. In part I we've seen, however, that there are many situations in which 1-2-3 is suboptimal to say the least: if I just care about if you are older than 21 I don't care to check if you are a returning user, and yet the traditional auth style leaves me no choice. For answering the question about the age I need to verify it myself somehow, cache the result somewhere and find a way of bringing it in scope once the user shows up: so I am forced to do 1 and 2 when in fact I'd be perfectly happy just with the results of 3. Strong of our detailed description of the architecture used for 1-2-3, in Part III we'll see how we can introduce authentication services and identity providers for achieving exactly what we want to achieve, instead of having to settle with a wholesale solution.
"Traditional" 1-2-3 authentication architecture
Let's start with the side of the web site (I simplified the picture, but all this still holds for web sites & web services, computers or mobile phones, browsers or rich clients, etc).
The first question we want to answer is if the user is a returning user. The most obvious way is remembering all the users that signed up, along with the credentials we negotiated with them at signup time: that's the bare minimum for pulling out the verification trick. Hence in the picture below we have a nice green DB barrel, containing a record for our faceless friend and his credentials (the key).

Fig 1: credentials store
Back on the user side. If the credentials are a simple username/password couple (as shown below), perhaps the most basic (and less secure) form of credentials, the only requirement is that the user remembers them. Very agile and very low requirements, which is great in some scenarios but much less in others. If you live few Km (miles) from school or workplace the bicycle is certainly a handy, cost effective & fun way to get there; on the other hand, if twice a month you need to transport the salaries of you company in cash for the same few miles you better get yourself a bulletproof vehicle.

Fig 2: Passwords
The authentication counterparts of bulletproof vehicles are certificates (soft, smartcard, hard tokens), cryptography in general, biometric... the choice is ample. From the functional perspective, however, don't expect an ontological jump from username and password: using something you have (cryptographic keys) or something you are (the part of your anatomy used for the biometric check, please stop laughing) may be much more secure than relying on something you know, but when used as a credential this is still just a trick for recognizing returning users. As shown below, they are still a key: a much more secure key, but still a key.

Fig 3: various types of credentials
Generally the better security does not come for free, at least in term of architecture: whereas passwords just need a text field for being used, a smartcard needs a reader to be plugged into and some software for working as expected (the dialog box that prompts you for typing the PIN code in is a visible manifestation of that additional software). Now, this may end up to be free for the end user anyway (the PC I get from your company may be equipped with card readers by default, or have an embedded fingerprint sensor) but from the architectural perspective we need to take that into account; hence the picture below shows it as a component on the user side.
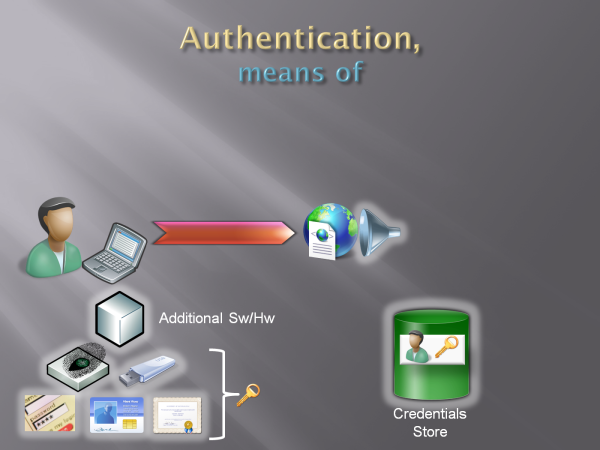
Fig 4: drivers, hardware and software needed for working with advanced credential types
Back on the web site side: no matter which kind of key technology we choose to use, we need to do whatever is necessary to collect the corresponding credentials (in the sense defined in I), verify them and obtain some handler.
That typically entails showing some credential gathering user experience (think username&password fields, or the little information card icon + the selector experience), and whatever is necessary for verifying the credential mechanism of choice. The cube behind the funnel in Fig 5 below represents all the software artifacts you need to use for performing those functions.
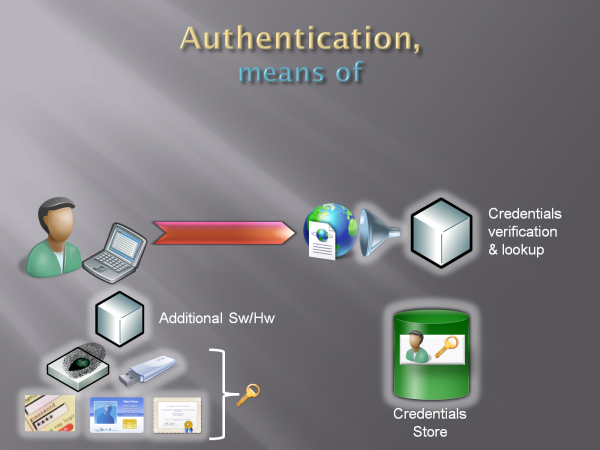
Fig 5: credential gathering & verification components
The "whatever is necessary for verifying the credential mechanism of choice" deserves a little digression. If we are verifying a shared secret, like username and password, the "mechanism" we use is a simple DB lookup; if we find a match, we verified that whoever called sent the right credentials AND we get a handle to a database row, which comes in handy for retrieving the profile (next step). In other words, verifying the credentials and verifying the presence of the user in the DB are achieved in the same operation.That lead a lot of people to think that those two things are one and the same, but that's not really true. Other kinds of credentials may be less straightforward, the definition of verification less clear. Example: an X509 security token. The verification "trick" would be more complex: we'd check if the issuing CA is trusted, if the cert is not expired nor revoked, if the signature computes and nobody modified the message in transit; THEN we'd take something unique feature of the certificate (thumbprint, or some serial combination) and use it for verifying that the incoming token not only is sound, but it also corresponds to an existing user in our DB.
Would you consider this last lookup as part of the verification stage? In this context it's a yes, because we defined credentials as one mean for verifying that a user is a returning user; but as we'll see a bit later, that's a rather restrictive definition that won't serve us too well in more interesting scenarios.
In any case. The architecture described so far is all you need if "are you a returning user?" was your only question. Anyway, chances are it wasn't: in Fig 6 below you can see a new barrel, this time for the attributes store.
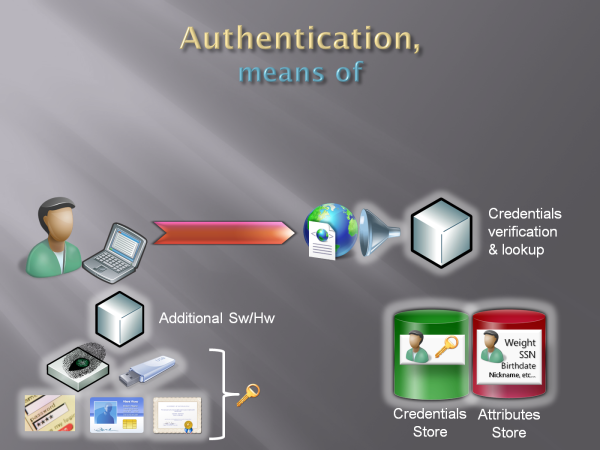
Fig 6: attributes store
Now, the attribute store is again something that is not always super clear. In Part I we've seen some examples of things we need to know about our user for conducting our business: user's age for the wine seller or the questionable content provider, marital status for the matchmaker, credit score for the mortgage company, email for pretty much everybody, etcetera. Those are obvious candidates for the attribute store: information about the user I acquired out of band, and that comes in scope as soon as the user successfully logs in. Let's say that I run an eCommerce website, and I keep track of what the user does in his sessions: does the title of the last DVD the user bought belong to the attribute store? I'd say yes, it's information about the user that transcend a specific execution path (i.e. it comes in handy in different parts & phases of my app). Does it matter that I didn't verify that information directly? Hmm, sort of. You may have noticed that across this post I am accurately avoiding the word identity. I am trying to show the RP angle here, so I stick with what the RP find advantageous: if you follow this blog you are certainly familiar with the idea of user centered identity management, and you surely realized by now that some of those attributes I am mentioning are naturally claims (if you read the book you may even think of hostage identities here, and you would be right); but I don't want to introduce the concept just yet. So be patient, for the time being the attributes in the attributes store are just attributes and I don't care much about if or how I verified or generated them, I only care that they answer questions I need to resolve for conducting my business.
Before I leave this topic, let me address a question I sometimes get at this point. Let's say that I run a web mail website, does the user inbox belong to his attribute store? In that case I'd say no, it's true that it is information that comes in scope when the user signs in but it seems associated to the app execution rather than the user description.
Allrighty, so many words for saying what? For authenticating users I need them to have credentials, I need a credentials store for recognizing their credentials as belonging to the users of my site, and I need an attribute store for keeping the facts I need to know about my user, that I can bring back in scope & lookup at sign in time. Doh, you say? Well, not so "doh" after all. Read Part III once it will be out, and hopefully I'll finally show you that by changing 1-2-3 here and there we can unleash non-trivial implications.