The Relative Performance Index
I’m so good sometimes I amaze even myself.
I like to play around with metrics and measurements. For the longest time, this was difficult to do because I was unsure of how to determine our non-spam. Well, a couple of months ago I devised a system of estimating it. I was quite proud of myself at the time for creating a model of how much mail we deliver is non-spam.
I didn’t realize until today how useful that model is. I now have a mechanism for estimating the following:
- How much mail we deliver is non-spam
- How much mail we deliver is spam
- We already know much mail we filter as spam
- We already know how many false positives we have
Given these values, it would be nice have an uber-metric that tells us how well each of our filter in pipeline is doing. As mail flows through our network, it has to go through more and more filters in order to get to the end-user. This means that each filter sees less and less mail, but roughly speaking they all see the same amount of non-spam; however, the spam flowing into them is getting less and less. So, we can calculate each filter’s relative spam performance by dividing the total amount of mail it filters as spam by the total amount of mail flowing into it. I call this relative effectiveness.
Relative effectiveness = mail filtered as spam / total mail flowing into filter
Next, I said to myself “Self, I would like to combine a filter’s relative effectiveness to each other, but I need a more apples-to-apples comparison. How do I do this?” I do it by using the filter’s FP rate. I call this the Relative Performance Index, or RPI. Actually, I call it Terry Zink’s Spam Filter Effectiveness Relative Performance Index, but TZSFERPI doesn’t really roll off your tongue.
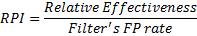
We know what the filter’s false positive rate is because users escalate them to us and we can match up false positives to what filter caused them. Using my baseline model, I know how much good mail goes through each filter (basically all of it, whatever FPs we have are too small to effect my calculation). This index combines how much mail a filter flags as spam with its false positive rate.
Suppose filter 1 filters 25% of the mail it sees as spam and has an FP rate of 2%. Filter 2 filters 63% of the mail it sees and has an FP rate of 5.2%. Which is better?
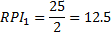
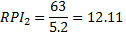
From our model, Filter 1 has a higher RPI and is therefore the winner of this comparison even though it flags less of its mail as spam than filter 2.
In my next post, I will describe some of the conditions of using the Relative Performance Index.