Debugging and tracing FAST Search pipeline extensibility stages
The pipeline extensibility stage that comes with FAST Search for SharePoint is a powerful tool, but it can be a little awkward to work with. The official MSDN documentation, https://msdn.microsoft.com/en-us/library/ff795801.aspx#pipeline-ext-ifilter, gives you enough to get you started, but I though I would share some additional best practices. Specifically, I wanted to be able to see what came into the stage and what was the resulting output. Below, I will walk you through the required steps to get files generated as shown here:
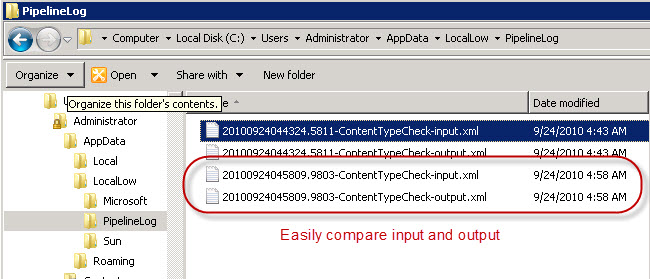
The files contains an exact copy of the input and output to the custom stage, and a useful tip is to always include the URL as input, even when it is not required for the business logic. This makes it much easier to see what sort of documents came with what properties
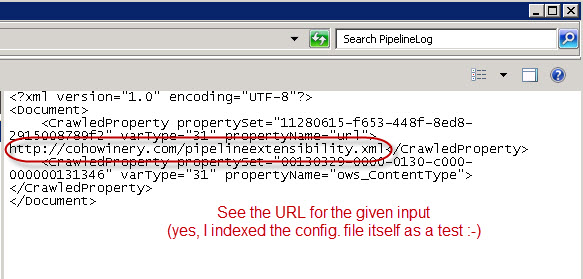 :
:
NOTE: I recommend that you familiarize yourself with the code sample in the MSDN documentation (see above link) before continuing. Otherwise, the code may be a little hard to follow.
So, extending on the sample code from the documentation, I wrapped the main logic in inside a parent method.
// Handle the basic logging and exception handling
static int Main(string[] args)
{
try
{
String inputXmlFile = args[0];
String outputXmlFile = args[1];
WriteLogFile(inputXmlFile, "-input");
DoProcessing(inputXmlFile, outputXmlFile);
WriteLogFile(outputXmlFile, "-output");
}
catch (Exception e)
{
// This will end up in the crawl log, since exit code != 0
Console.WriteLine("Failed: " + e + "/" + e.StackTrace);
return 1;
}
return 0;
}
What does this give us:
- We can log what came in to our process
- We log what our process produced based on that
- If processing fails - the actual error will be visible in the UI crawl log
NOTE: An additional tip here is to always include the URL of the as input parameter, even when it is not really needed for processing. Then it will be logged as part of the "input"-logging, and will give you a reference to the document processed.
But, as you may know, the pipeline extensibility stage is not allowed to write to the local file system, except for in one single location:
<user-home-directory>\appdata\LocalLow
Consequently, this is what our logging routine will look like:
// Write the input file to a location the application has access to write in.
static void WriteLogFile(string inputFile, string suffix)
{
String pipelineInputData = @"c:\users\" + Environment.UserName +
@"\appdata\LocalLow\PipelineLog";
// Enable/disable debugging in real-time by creating/renaming the log directory
if (Directory.Exists(pipelineInputData))
{
Directory.CreateDirectory(pipelineInputData);
string outFile = Path.Combine(pipelineInputData, timestamp + "-" +
MethodBase.GetCurrentMethod().DeclaringType.Name +
suffix + ".xml");
File.Copy(inputFile, outFile);
}
}
Some points worth noting:
- We check for the existence of the logging directory ("PipelineLog"), giving us the ability to turn debugging output on/off in real-time
- We use a timestamp constant, so that input and output can be easily matched
That's about it, now we just need to define the constants we have been referencing:
public static readonly Guid CrawledCategorySharepoint =
new Guid("00130329-0000-0130-c000-000000131346");
public static readonly Guid CrawledCategoryUserDefined =
new Guid("D5CDD505-2E9C-101B-9397-08002B2CF9AE");
public static readonly String timestamp =
DateTime.Now.ToString("yyyyMMddHHmmss.ffff");
And the main processing will be handled very much like suggested in the MSDN documentation:
// Actual processing
static void DoProcessing(string inputFile, string outputFile)
{
XDocument inputDoc = XDocument.Load(inputFile);
// Fetch the content type property from the input item
var res = from cp in inputDoc.Descendants("CrawledProperty")
where new Guid(cp.Attribute("propertySet").Value).
Equals(CrawledCategorySharepoint) &&
cp.Attribute("propertyName").Value == "ows_ContentType" &&
cp.Attribute("varType").Value == "31"
select cp.Value;
// Create the output item
XElement outputElement = new XElement("Document");
string mappedTo = "nocontenttype";
// Add a crawled property if a content type was present
if (res.Count() > 0 && res.First().Length > 0)
{
mappedTo = "hascontenttype";
}
outputElement.Add(
new XElement("CrawledProperty",
new XAttribute("propertySet", CrawledCategoryUserDefined),
new XAttribute("propertyName", "mycontentcheck"),
new XAttribute("varType", 31), mappedTo)
);
outputElement.Save(outputFile);
}
Attached is the complete code.
The corresponding contents of pipelineextensibility.xml is as follows:
<PipelineExtensibility>
<Run command="HasContentTypeCheck.exe %(input)s %(output)s">
<Input>
<CrawledProperty propertySet="00130329-0000-0130-c000-000000131346" varType="31" propertyName="ows_ContentType"/>
<!-- Included for debugging/traceability purposes -->
<CrawledProperty propertySet="11280615-f653-448f-8ed8-2915008789f2" varType="31" propertyName="url"/>
</Input>
<Output>
<CrawledProperty propertySet="d5cdd505-2e9c-101b-9397-08002b2cf9ae" varType="31" propertyName="mycontentcheck"/>
</Output>
</Run>
</PipelineExtensibility>
Credits go to my colleague Barry Waldbaum for coming up with the inital solution!
Disclaimer:
This
code is dedicated to the public domain as-is without warranty of any kind.