Creating a semantic “PowerShell” web
A couple of weeks ago we announced that we had just released our first beta of Microsoft Script Explorer. The goal for Script Explorer was two-fold. The first was to help people looking for scripts / cmdlets / modules find them – regardless of where they resided. The second was to help large organizations formalize practices around something I am calling script lifecycle management (more about this in a later post) – through establishment of centralized repositories of scripts managed within an organization.
In my last blog post I promised to provide an overview of the design of Microsoft Script Explorer. Before I do that it is worth spending a little more time talking about our vision for a semantic web focused in and around PowerShell. In very simplistic terms, a semantic web takes the information that is typically hidden inside product documentation, blog posts, support forums and so forth – and enables that information to be defined in a predictable manner – which of course enables discovery of that information. A great example of this is of course a PowerShell Script. Scripts are typically just text hidden inside web pages – and search engines such as Bing / Google and Yahoo can’t discriminate whether a page containing the words “PowerShell Script” is what you are looking for vs pages that actually contain valid PowerShell scripts.
But the semantic web is much more than that. In addition to being able to define types of information, we also want to specify types of relationships between such information. Having found a web page with a PowerShell script on it – there are often any number of other links on the page – some are navigational within the site, some are links to related content and some are advertisements. A lack of clarity around what the links on a page are prevents us from creating great information experiences where we can lead a user from one page to the next in a predictable fashion – either inside a
browser or inside a tool such as the ISE. Ideally we want to be able to take a web page that contains a script supporting a cmdlet such as “get-wmiobject” and inform the user that if they want an “Overview” of WMI click this link, or if they want “Getting Started” guidance click on another link, and if they want more “Examples” of how this cmdlet can be used for managing user accounts then
they should click a third link. It is these explanations of what purpose the serve that will enable richer guidance experiences across information sets.
The Semantic Web has of course been discussed for a long-time now – both as an architectural vision and a variety of implementation techniques showing how to realize this vision. Based on our initial set of requirements we have settled on a set of implementation techniques based on the following combination of standards: oData, HTML 5 Micro-Data and schema.org schemas.
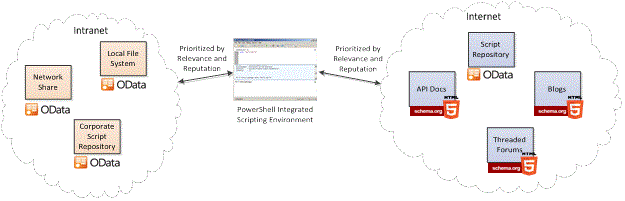
The illustration below attempts to illustrate that PowerShell Scripts can be stored in a number of different places – inside local file systems, network shares, web sites, online forums and script repositories. When the scripts exist inside a web page such as in a blog or a threaded discussion we believe HTML 5’s Micro-Data will enable us to include additional meta-data that will describe the specific parts of the page that contain scripts and information related to the scripts name and purpose that will better enable search. For repositories such as TechNet and POSH we believe oData
provides a great programmatic means of accessing these repositories.
Makes sense at a high-level – correct? But any astute PowerShell repository / blog / forum owner will immediately recognize that very few of these sites have standardized on these technologies – and worse still adoption would require editing and reposting of much of this information. So what can be done in the mean time? The answer is of course Microsoft Script Explorer for Windows PowerShell – and I will use my next blog post to drill into more detail.