Comments on the post - Manage Hadoop clusters in HDInsight using Azure PowerShell
Overall, the post on managing a Hadoop cluster in HDInsight with Azure PowerShell was great. I altered the parts below for various reasons. My related posts can be found here.
Copying a file to/from blob store
In the post linked above you'll create a new storage container. Rather than rush ahead I wanted another way to verify from the command line that the container existed and that it could accept a file.
From the PowerShell ISE command prompt I ran the following (note that I previously ran "Set-AzureSubscription" since I have more than 1 subscription):
PS C:\WINDOWS\system32> get-azurestoragecontainer <your container name here>
You'll get results that look similar to the following. In this example, my container name is shown below.
Blob End Point: https:// <storage account name >.blob.core.windows.net/
Name PublicAccess LastModified
---- ------------ ------------
container1 Off 1/11/2015 12:10:23 AM +00:00
Next, I created a local test file and copied it to my container1. You should alter the 2 params underlined below to match your local machine.
- My test file was in this location “c:\temp\1.txt”.
- From the PowerShell prompt I ran the following to upload the file to blob store:
Set-AzureStorageBlobContent -Blob “TestTempFile” -Container container1 -File “c:\temp\1.txt” -Force
- You can use Azure Storage Explorer to see the blob named "TestTempFile" or run the following from PowerShell prompt to get that file and place it in a different location on your local machine - I used c:\hdp. Also, the -Blob param is case sensitive (must be "TestTempFile"):
Get-AzureStorageBlobContent -Blob TestTempFile -Container container1 -Destination c:\hdp -Verbose
Also, I ran the following cmdlet to get info about that file (blob) I just uploaded:
Get-AzureStorageBlob -Container container1 -Blob TestTempFile -Verbose
I received:
Container Uri: https://< storage account name>.blob.core.windows.net/container1
Name BlobType Length ContentType LastModified SnapshotTime
---- -------- ------ ----------- ---------- -----------
TestTempFile BlockBlob 65 application/octet-stream 1/11/2015 11:08:35 PM +...
How to handle the error "New-AzureHDInsightCluster : Unable to complete the cluster create operation. Operation failed with code '400'…"
In the tutorial I encountered some issues provisioning an HDInsight cluster from PowerShell. When the "New-AzureHDInsightCluster" cmdlet
was called the dialog box appeared below:
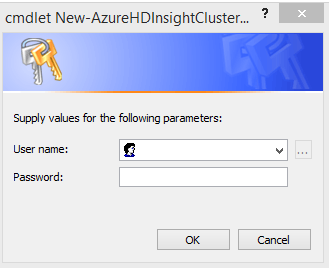
The user name field above has a drop down that had my previously used accounts. Ok, so I chose my Microsoft Account and a different account and in both cases I received the error:
Error: New-AzureHDInsightCluster : Unable to complete the cluster create operation. Operation failed with code '400'. Cluster left behind state: 'Error'. Message: 'ClusterUserNameInvalid'.
Each time I received this error it left the cluster in a bad state so I ran the following from the PowerShell command prompt to remove it each time:
Remove-AzureHDInsightCluster -name <add bad cluster name here>
I did some research then ran the script from the tutorial a 3rd time. This time when that dialog box prompted me I entered a new username and password for the HDInsight cluster I was creating. After it was finished the PowerShell cmdlet "Get-AzureHDInsightCluster" successfully returned my newly created HDInsight cluster.
The file "example/jars/hadoop-examples.jar" not found.
In the tutorial under "Submit MapReduce Jobs" the script may not find the file "example/jars/hadoop-examples.jar" in your cluster. On my cluster the real file name below is different from the files "example/jars/hadoop-examples.jar" and "hadoop-mapreduce.jar" mentioned in the tutorial. If the script can't find "hadoop-examples.jar" you'll need find .jar file used by your HDInsight cluster.
The simplest way to find this file is to use Azure Storage Explorer, find the name of the .jar file and update the script.
Alternatively:
- You can sign into your cluster using remote desktop
- open the Hadoop command prompt
- run the following:
C:\apps>hadoop fs -ls /example/jars
My results are shown below:
Found 1 items
-rw-r--r-- 1 hdpinternaluser supergroup 270298 2015-01-18 05:56 /example/jars/hadoop-mapreduce-examples.jar
I only made 1 alteration in bold to the .jar filename in the script below.
-----
$clusterName = "<your HDInsight cluster name here>"
# Define the MapReduce job
$wordCountJobDefinition = New-AzureHDInsightMapReduceJobDefinition -JarFile "wasb:///example/jars/hadoop-mapreduce-examples.jar" -ClassName "wordcount" -Arguments "wasb:///example/data/gutenberg/davinci.txt", "wasb:///example/data/WordCountOutput"
# Run the job and show the standard error
$wordCountJobDefinition | Start-AzureHDInsightJob -Cluster $clusterName | Wait-AzureHDInsightJob -WaitTimeoutInSeconds 3600 | %{ Get-AzureHDInsightJobOutput -Cluster $clusterName -JobId $_.JobId -StandardError}
-----
How to handle error "Get-AzureStorageBlobContent : Access to the path 'C:\WINDOWS\System32\example\data\WordCountOutput' is denied."
In the post under section "To download the MapReduce job output" the PowerShell script gave me the following error.
"Get-AzureStorageBlobContent : Access to the path 'C:\WINDOWS\System32\example\data\WordCountOutput' is denied.
The script assumed I wanted the WordCount output file to be put in C:\WINDOWS\System32\... (we all know about assumptions, right? :)
I saw 2 options to get this working for me:
Option A:
From the PowerShell command line I manually ran the 2 commands below. I added the "-Destination" switch to specify the root where I wanted the file named
"part-r-00000" to be placed. In this case this cmdlet creates subdirs under this root and places the file there. For example, I specified "c:\hdp" as my root so it'll put the file in "c:\hdp\examples\data\WordCountOutput". You should change the underlined root below to a location on your machine.
- Get-AzureStorageBlobContent -Blob example/data/WordCountOutput/part-r-00000 -Container container1 -Destination c:\hdp -Force -Verbose
- cat C:\hdp\example\data\WordCountOutput\part-r-00000 | findstr "there"
Option B:
I made 3 small changes to the script provided in the tutorial. I marked my changes in the comments below as
##
-----
$storageAccountName = "<your storage account name > "
$containerName = "<your container name>"
## I added the 2 variables below. Add your root destination subdir below.
$Rootdestination = "<your root subdir here>"
$FileIsHere = "$Rootdestination\example\data\WordCountOutput\part-r-00000"
# Create the storage account context object
$storageAccountKey = Get-AzureStorageKey $storageAccountName | %{ $_.Primary }
$storageContext = New-AzureStorageContext -StorageAccountName $storageAccountName -StorageAccountKey $storageAccountKey
# Download the output to local computer.
## I added the -Destination switch below to specify where I want the file. I also like -Verbose too :-)
Get-AzureStorageBlobContent -Container $ContainerName -Blob example/data/WordCountOutput/part-r-00000 -Context $storageContext -Destination $Rootdestination -Force -Verbose
## Display the output. I included the full path where the file is located.
cat $FileIsHere | findstr "there"
-----
I hope this extra info was helpful for you.
Good luck!