Exploration de la gestion de l'UTF16 avec SQL Server
Bonjour à tous,
J'ai récemment eu à me pencher sur le détail de l'implémentation de la gestion de l'encodage Unicode UTF16 dans SQL Server.
La documentation existante (Microsoft ou tierce partie, avec un bon point de départ ici : https://www.unicode.org/standard/principles.html) est plus que complète, le but est ici d'avoir un exemple simple, facile à déployer, et qui permet de se confronter aux mécanismes en jeu sur notre SGBD préféré.
NB : L'utilisation de caractères Unicode avancés met par contre à mal la (rustique) chaine de publication de ce blog, j'utiliserai donc des captures d'écrans des requêtes et résultats, et j'attacherai le script au blog.
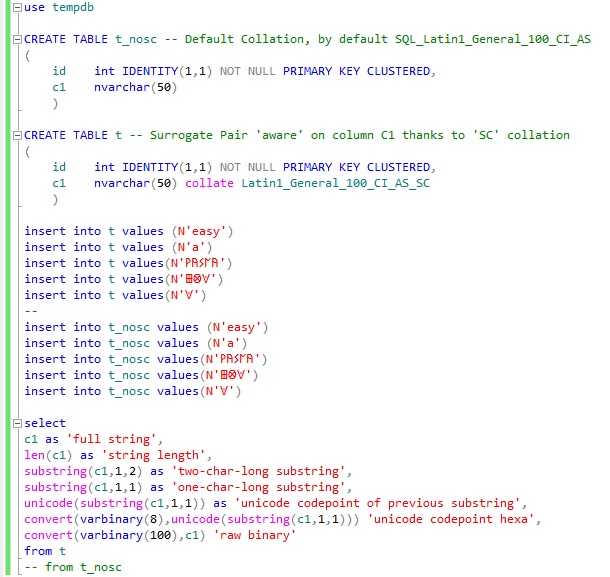
Création du kit de test :
(Ce site a été pratique pour recueillir du texte 'exotique' : https://www.i18nguy.com/unicode/plane1-utf-16.html )
Notre script insert donc des données unicode ‘avancées’ dans deux tables SQL distinctes :
· La table ‘t_nosc’ qui utilise une collation 'classique'
· La table ‘t’ utilisant les nouvelles collations 'surrogate chars' apportées par SQL Server 2012 (comme décrit ici https://msdn.microsoft.com/en-us/library/ms143726(v=sql.110).aspx )
On remarquera au passage que Management Studio (l’application cliente utilisée pour les tests) et plus généralement l’environnement Windows a dans mon cas très bien géré le copier/coller depuis le site précité ouvert dans Internet Explorer vers une fenêtre de requête SSMS : les valeurs unicodes ont bien été récupérées et SSMS a affiché les caractères spéciaux sans action particulière. Dans ce contexte il faut vraiment garder à l’esprit que l’affichage du caractère (et donc l’existence d’une représentation graphique pertinente) et son stockage sont distinct. Si votre client ne sait pas afficher un caractère donné, vous aurez droit aux points d’interrogation ou aux carrés blancs typiques, mais cela n’implique pas obligatoirement que les données unicodes sont invalides. Le script SQL est attaché à cet article, je vous invite à utiliser SSMS pour l'ouvrir.
Le SELECT vient ensuite requêter les données fraichement insérées, en y ajoutant quelques appels à des fonctions de chaines usuelles (LEN, SUBSTRING), et récupère différents niveaux d’encodage de la chaine : le ‘codepoint’ unicode, et le flux binaire ‘brut’.
Voici les résultats sur les deux tables :
Table sans collation SC :

Table avec collation SC :

Voyons ce que cela nous permet de conclure :
· La 1ère colonne nous montre que nous récupérons bien les chaines d’origine dans les deux cas ! Pas de caractère invalide ou mal interprété. Or nous savons que les caractères choisis ont un encodage UTF16, SQL Server est donc capable de stocker et de restituer des chaines UTF16 nativement, sans besoin d’utiliser des collations particulières ! Il faut bien sûr utiliser des types de colonnes unicode …
· La 2ème colonne permet par contre de constater que les fonctions de manipulations de chaine sont impactées par nos caractères ‘exotiques’ UTF16 : par exemple la ligne 3 nous indique 10 caractères de long dans le premier cas, car SQL Server voit 5 fois 2 caractères UCS2 (2 octets) alors que la collation SC gère correctement les 4 octets par caractères et affiche comme longueur 5. Cet aspect est attendu et documenté (cf fin de https://msdn.microsoft.com/en-us/library/ms143726.aspx)
· De la même manière, la 3ème colonne / ligne 3 ne donne qu’un seul caractère alors que la demande est un SUBSTRING de deux caractères de long. Cette opération illustre bien comment SQL Server peut par défaut permettre à ses clients full UTF16 de fonctionner parfaitement sans être capable de ‘comprendre’ l’UTF16 lui-même : SQL Server croit émettre 2 caractères distincts, et le client détecte que ce sont 2 paires relatives au même caractère UTF16 à 4 octets, et les ‘réunit’ pour ne former qu’un seul caractère à l’affichage.
· La 4ème colonne illustre le cas où un caractère à 4 octets (une surrogate pair) va être coupé en deux : la première table non-SC nous donne des caractères invalides, car une moitié (2octets) isolée de caractère à 4 octets n’a aucune signification. Et c’est en fait une bonne chose, car on pourrait imaginer que les 2 moitiés à 2 octets d’un caractère à 4 octet aient une autre signification possible quand elles sont isolées que quand elles sont groupées. Cela induirait un remplacement silencieux d’un caractère par deux autres (valides, mais non attendus) si d’aventure une ‘surrogate pair’ UTF16 était scindée et gérée comme deux caractères à 2 octets. Bien dangereux et insidieux non ? Comme nous le verrons plus bas, l’encodage UTF16 n’autorise pas cela, et nous avons donc quand une moitié de surrogate pair est traitée de manière isolée un caractère invalide permettant de détecter le problème. Dans le cas de la table avec SC, ce sont bien les 2 moitiés de la surrogate pair qui sont consommées pour nous fournir le caractère stocké.
· Les 5ème et 6ème colonnes nous indiquent le ‘codepoint’ unicode de la colonne précédente. On note des valeurs ‘basses’ pour nos caractères latins habituels, associée au ‘Basic Multilingual Plane’ ou BMP, par contre les caractères exotiques sont associés à des valeurs élevées. Sur la table non SC, on voit la valeur 0xD800 (55296) répétée pour des caractères différents. Cela est lié au fait que SQL Server regarde une moitié seulement de la Surrogate Pair des caractères exotiques et cette moitié a la même valeur unicode pour les caractères du script d’exemple (la variabilité est sur la 2ème paire, il est facile de la faire apparaitre en changeant l’offset du substring). On verra plus bas le pourquoi de cette valeur D800. La table « SC » par contre fait apparaitre des valeurs distinctes, et >65536 ou 0xFFFF, impliquant plus de 2 octets d’encodage.
· La 6ème colonne fait apparaitre le flux binaire brut correspondant au stockage de la chaine unicode dans SQL Server. Un élément important est d’observer que pour les caractères du BMP (typiquement, nos caractères latins), l’encodage binaire et le codepoint unicode ont la même valeur (ex : 0x0061 pour le ‘a’). Cette colonne permet également de visualiser directement la taille d’encodage doublée pour nos chaines exotiques. Vous constaterez également que le flux binaire est strictement identique pour la table t_nosc et t : l’utilisation des collations SC ne modifie pas l’encodage, et à nouveau, on voit que SQL Server a bien stocké 4 octets par caractère même dans la collation par défaut. Enfin, on voit que les caractères exotiques ont visiblement un encodage qui n’est pas ‘juste’ le codepoint unicode, ce sera l’objet de notre exploration ci-dessous.
Nous allons maintenant nous intéresser à l’encodage d’un caractère UTF16 à 4 octets (donc une ‘surrogate pair’) dans SQL Server.
Notre cobaye sera le caractère de la ligne 5, que nous pouvons retrouver en tapant son codepoint 1031E sur https://www.unicode.org/charts/charindex.html. Comment arriver de cette valeur à l’encodage binaire de la dernière colonne ?
https://www.unicode.org/faq/utf_bom.html#utf16-3 Nous indique un algorithme de conversion mais qui est peu lisible pour un humain, voyons les étapes successives :
· Codepoint Unicode 0x0001031E
· On retire 0x10000
o 0x0001031E - 0x10000 = 0x00031E
· Traitement du 1er élément de la surrogate pair (‘lead’ pair ou ‘high offset)
o 10 bits ‘hauts’ = Masque 0xFFC00
o select convert(varbinary, convert(int,0x31E) & 0xFFC00)
o = 0x00000000
o Ajout de l’offset arbitraire des Lead surrogate : 0xD800
o 0x0 + 0xD800 = 0xD800
· Traitement du 2ème élément de la surrogate pair (‘trailing’ ou ‘low offset’)
o 10 bits ‘bas’ = Masque 0x003FF
o select convert(varbinary, convert(int,0x31E) & 0x3FF)
o = 0x0000031E
o Ajout de l’offest arbitraire des Trailing Surrogate : 0xDC00
o 0x0000031E+0xDC00 = 0xDF1E
· La surrogate pair est donc :
o 0xD800 0xDF1E
· N’oublions pas la convention ‘little endian’ et appliquons le byteswap :
o 0x00D81EDF
· Nous retrouvons bien l’encodage retourné par SQL Server !
Comme rapidement évoqué plus haut, les offsets arbitraires utilisés pour encoder la lead et trailing pair aboutissent à des valeurs d’encodage pour chaque paire qui sont réservées pour des surrogate pairs : si pour une raison donnée on se retrouve à considérer une seule moitié de la paire, sa valeur indique sans équivoque qu’elle est une moitié leading ou une trailing et qu’elle doit être nécessairement associée à sa ‘conjointe’ pour être décodée. Il ne peut pas y avoir de ‘mauvaise interprétation’ silencieuse d’une ‘demi paire’ UTF16 en tant que caractère codé sur 2 octets.
En pratique le ‘Basic Multilingual Plane’ a toutes les chances de contenir l’ensemble des caractères que vous stockerez dans SQL Server, et ces valeurs seront donc encodées directement sur 2 octets qui seront nativement gérés par SQL Server, sans autre réglage particulier que d’utiliser des types unicodes (nvarchar, nchar..). Quand bien même un caractère rare se glisserait dans votre flux de données, qui nécessiterait un encodage sur 4 octets, nous avons vu que SQL Server pourra le stocker et le restituer sans problème, toujours sans ‘réglage’ supplémentaire. Mais si vous prévoyez de faire des manipulations de chaines avancées au sein de SQL Server, et que des caractères UTF16 sur 4 octets sont prévus, alors dans ce cas l’utilisation des collations avancées de SQL Server 2012 semble pertinente.
A bientôt !
Guillaume Fourrat
Ingénieur d'Escalade