Capturing logs during failed Task Sequence Execution
Every OSD administrator knows the feeling of configuring a complex (or even simple) OSD Deployment, testing and releasing - only to have the deployment fail. At failure, OSD will begin a countdown to reboot and, on restart, the logs are often lost and we administrators are left wondering what went wrong. To find out we have to start the deployment again and spend time waiting for the failure. Wouldn't it be cool if we had a way to automate forcing OSD to collect logs when it fails before exiting? Good news! :)
I have spent some time recently working on just how to do that and we have two examples - both use the same approach but one is for generic task sequences (those sent through advertisements,etc) and the other is for OSD deployments. Lets start with the generic one, explain the needed steps and the show how we incorporate that into OSD.
Take a look at a screenshot of the generic task sequence. In this screenshot we see two groups - the Main TS Group that contains our TS steps and our Error Catching Group. To make this work we need to ensure that the Main TS group is set to 'continue on error'' - you don't have to set the individual steps to continue on error - just the group. From there we need to configur our Error catching group to activate in the event of a problem - note the use of the Task Sequence variable to detect whether an error condition has been flagged when we reach this group.
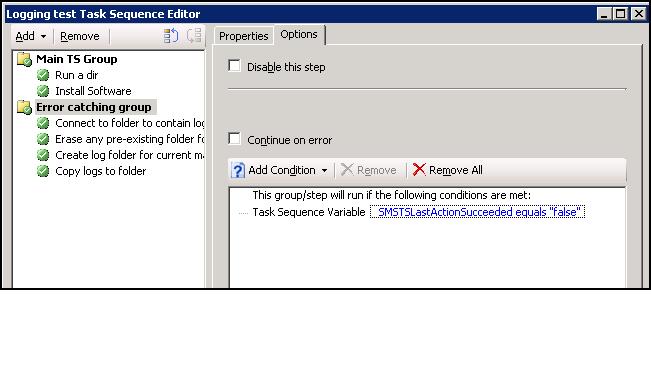
From here we have 4 steps that make up our error catching group, we will discuss each one followed by a series of screenshots showing how each is configured.
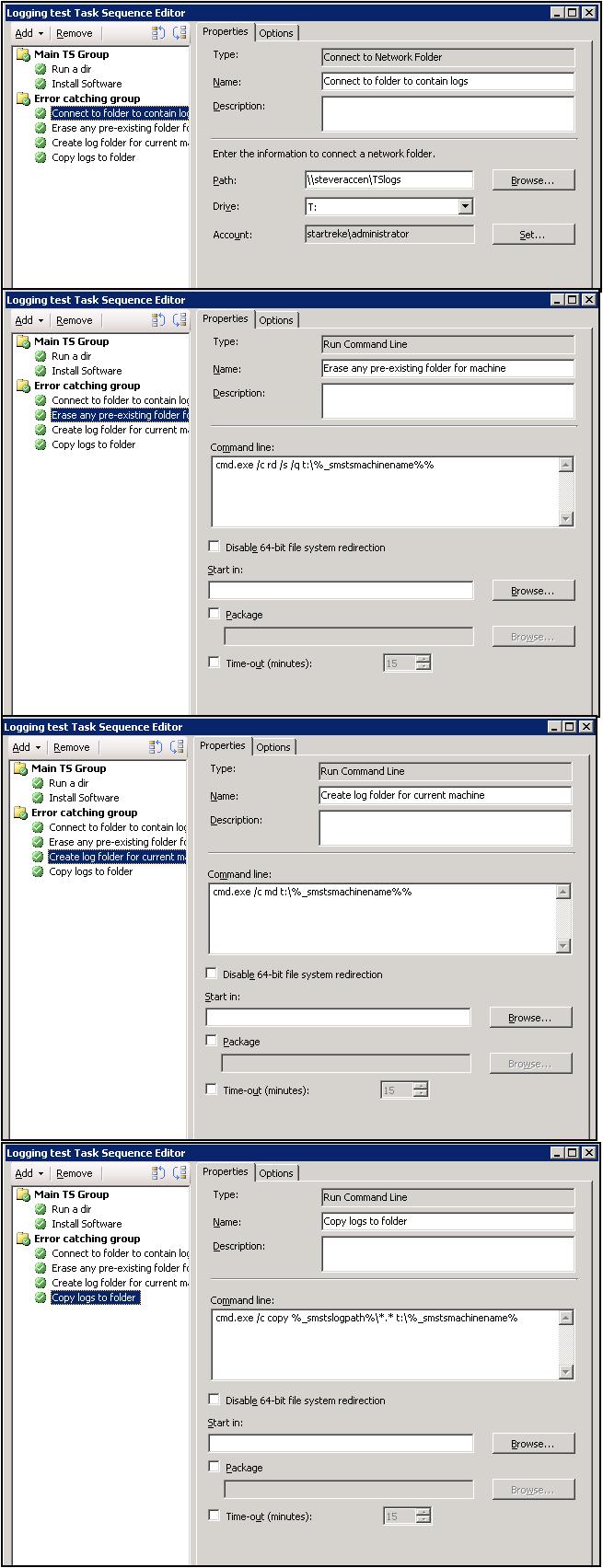
Connect to folder to contain logs - this step uses the 'Connect to Network Folder' step which will connect to a precreated network share, assign a drive letter and provide credentials for the connect
Erase any pre-existing folder for machine - this step uses the 'Run Command Line' step which will attempt to remove any folders that remain from a previous execution of the error control steps
Create log folder for current machine - this step also uses the 'Run Command Line' step which will create a new folder with a name specific to the machine name running the task sequence. Depending on where we see a failure, the machine name might be the assigned machine name or it may be a machine name like 'minint-<random string>. This style of machine name is what you will see if the system failed while in the Windows PE phase of deployment. For this and the previous step, not the use of the task sequence variable to capture the current machine name.
Copy logs to folder - This step will connect to the share defined above and copy any Task Sequence logs to the share. Note the use of the task sequence variable to specify the last known logging directory from which to copy.
Screenshots showing how each step is configured
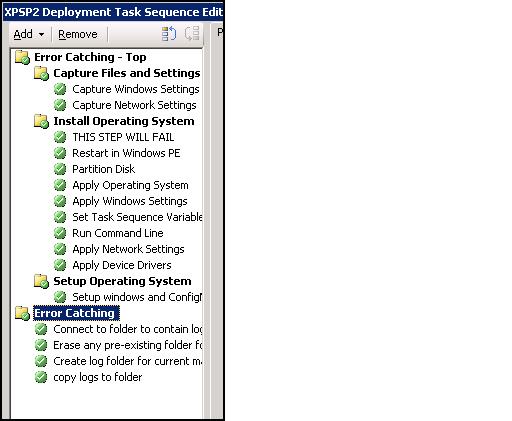
How about an OSD example? The error trapping steps are exactly the same so I won't show that detail again - but the sequence is a bit more complex - take a look at the difference. Note that the ENTIRE portion of the task sequence that does the work is nexted inside of the Error Catching - Top group. The Error Catching - Top group is the only one here that requires 'continue on error to be set' - and then, in the event of an error, control is passed to the Error Catching group
The method I've demonstrated is just one way of doing this. You can choose to use a script or batch file to handle these steps in one single TS step if you like. The key, however, is that you do have to have a top group with 'continue on error' set and a final group that handles the error catching.