Docker Tagging: Best practices for tagging and versioning docker images
In any new tech, there are lots of thoughts around “best practices”. When a tech is new, what makes a best practice?
Working at Microsoft, running the Azure Container Registry (ACR), talking with lots of customers, some that use Azure and some that don’t, we’ve had a lot of exposure to what customers have encountered. We’ve been working on a number of scenarios, including container life cycle management and OS & Framework patching with containers. This has surfaced a number of interesting issues. Issues that suggest, “both sides” of the tagging argument have value.
It’s easy to get caught up, arguing a particular best practice, …if you don’t first scope what you’re practicing. I'll start by outlining two basic versioning schemes we’ve found map to the most common scenarios. And, how they are used together to solve the container life cycle management problem.
Container Patterns Support a Self-Healing Model
Before I get into specific tagging schemes, it may help to identify a specific scenario impacted by your tagging scheme.
The most basic container scenario supports restart type policies. docker run --restart always myunstableimage:v0 This helps when a container fails due to some internal reasoning. But, the host is still available. In this case, our code must be resilient. Or, to an old friends point (Pat Helland), "we must write our software with a apology based computing approach." Apology based computing suggest our code must deal with "stuff" that happens. A set of code, or a container may fail and need to re-run that logic.
For the purposes of tagging, I'll stay focused on the other aspect; we must assume a container host may fail at any point. Orchestrators will re-provision the failed node, requiring a new docker pull. Which begs the question: when you have a collection of containers running the same workload, do you want them to all run the same workload, or some of them have the last version, while new nodes have a newer version?
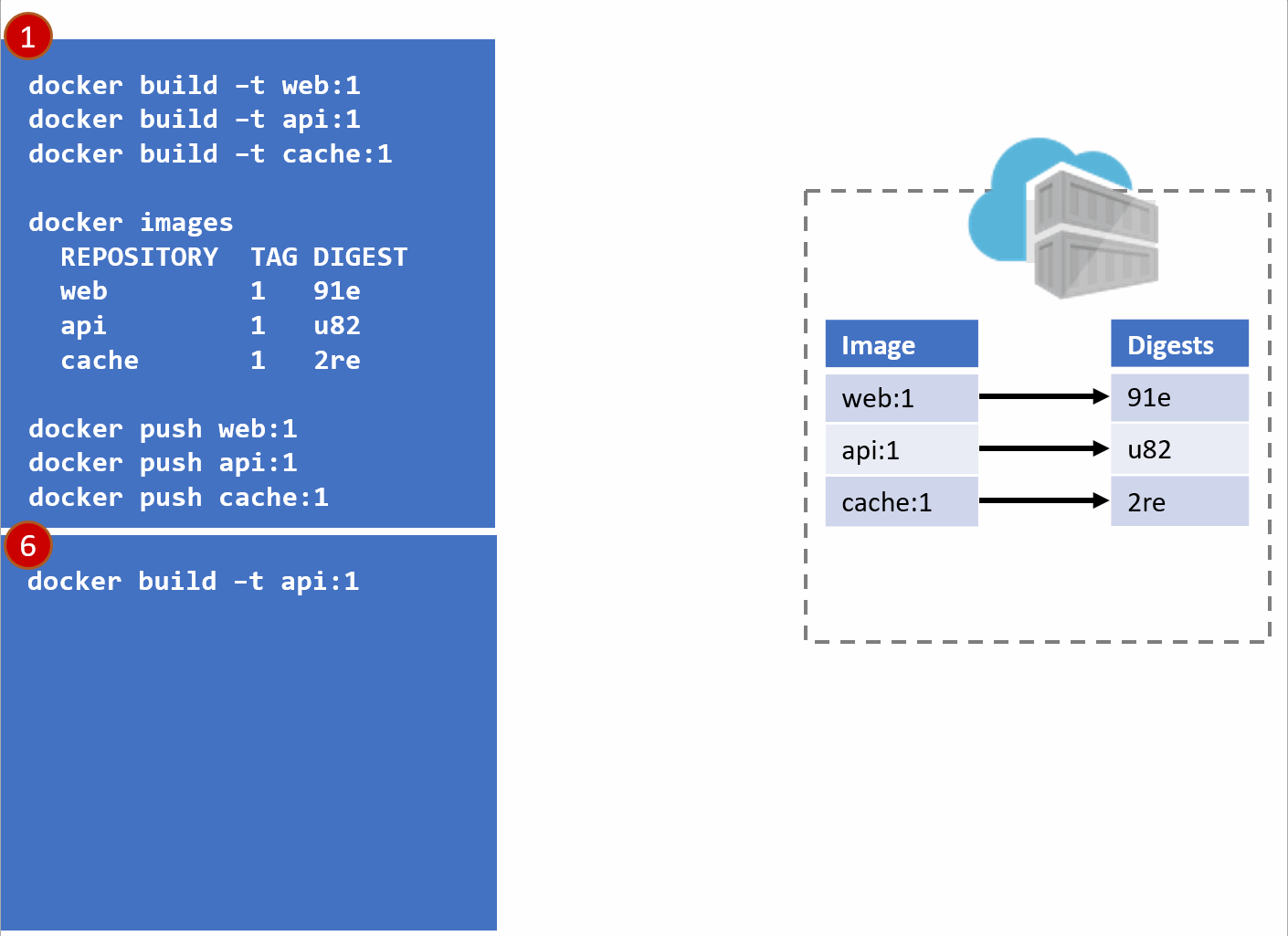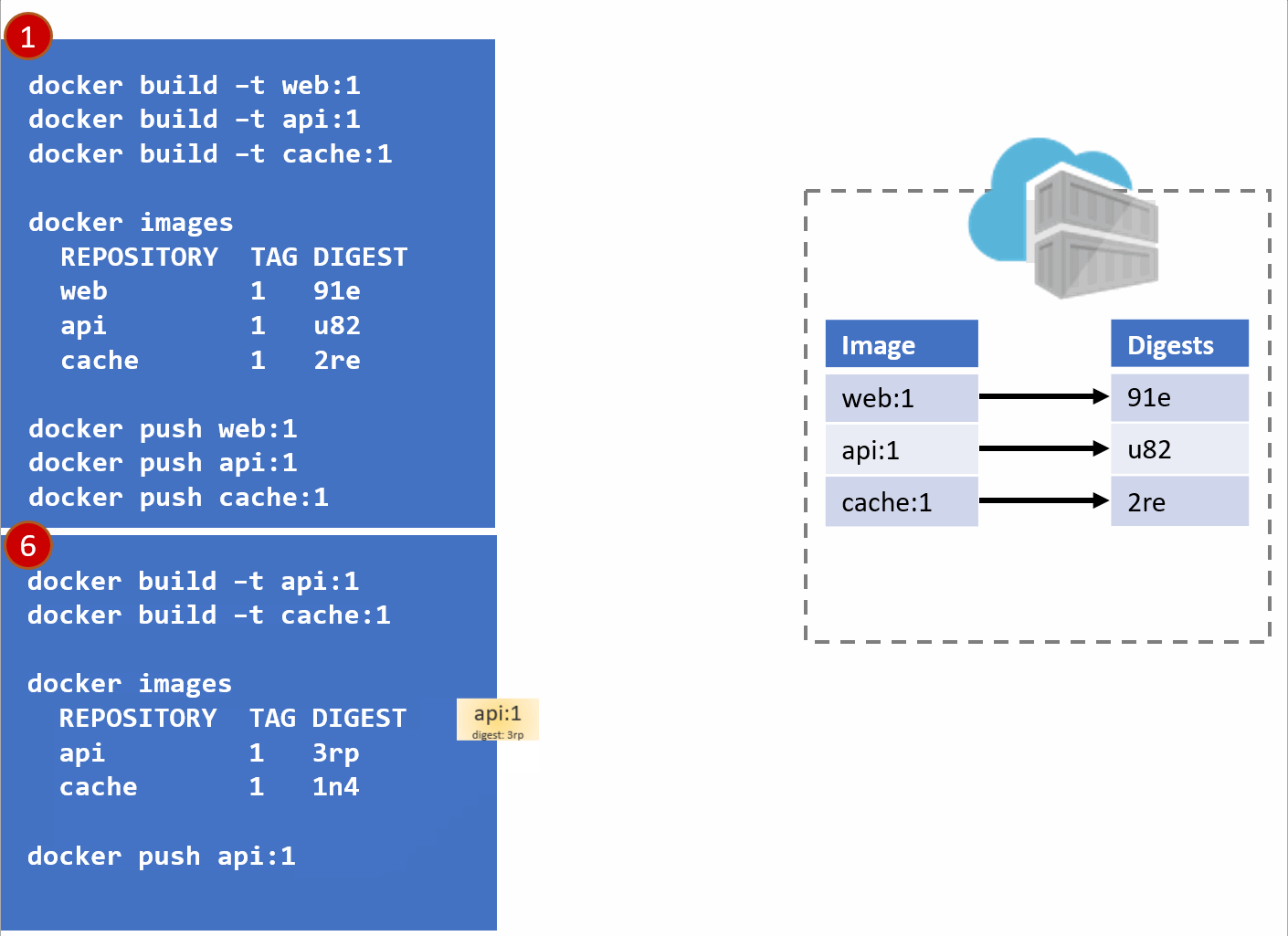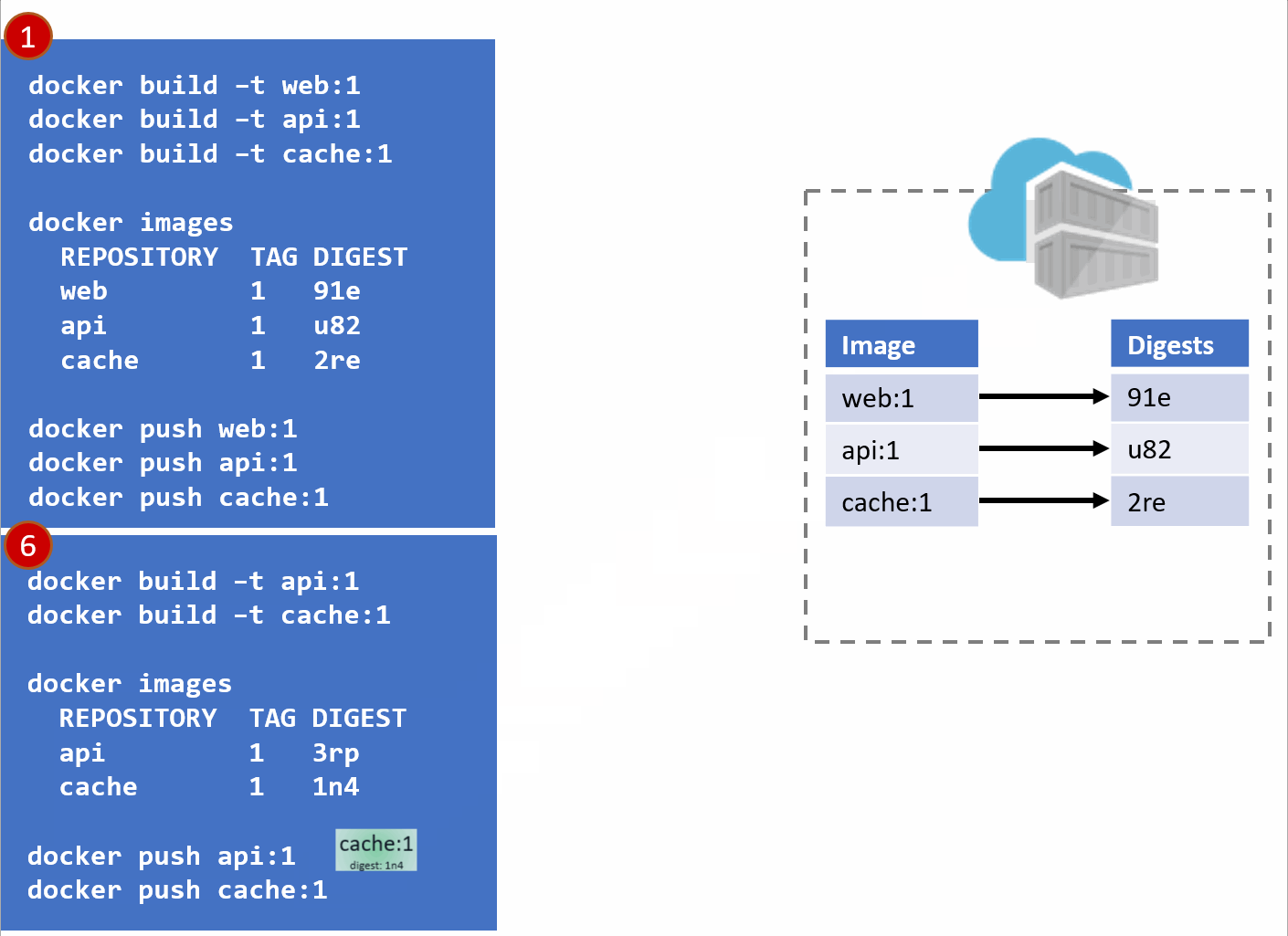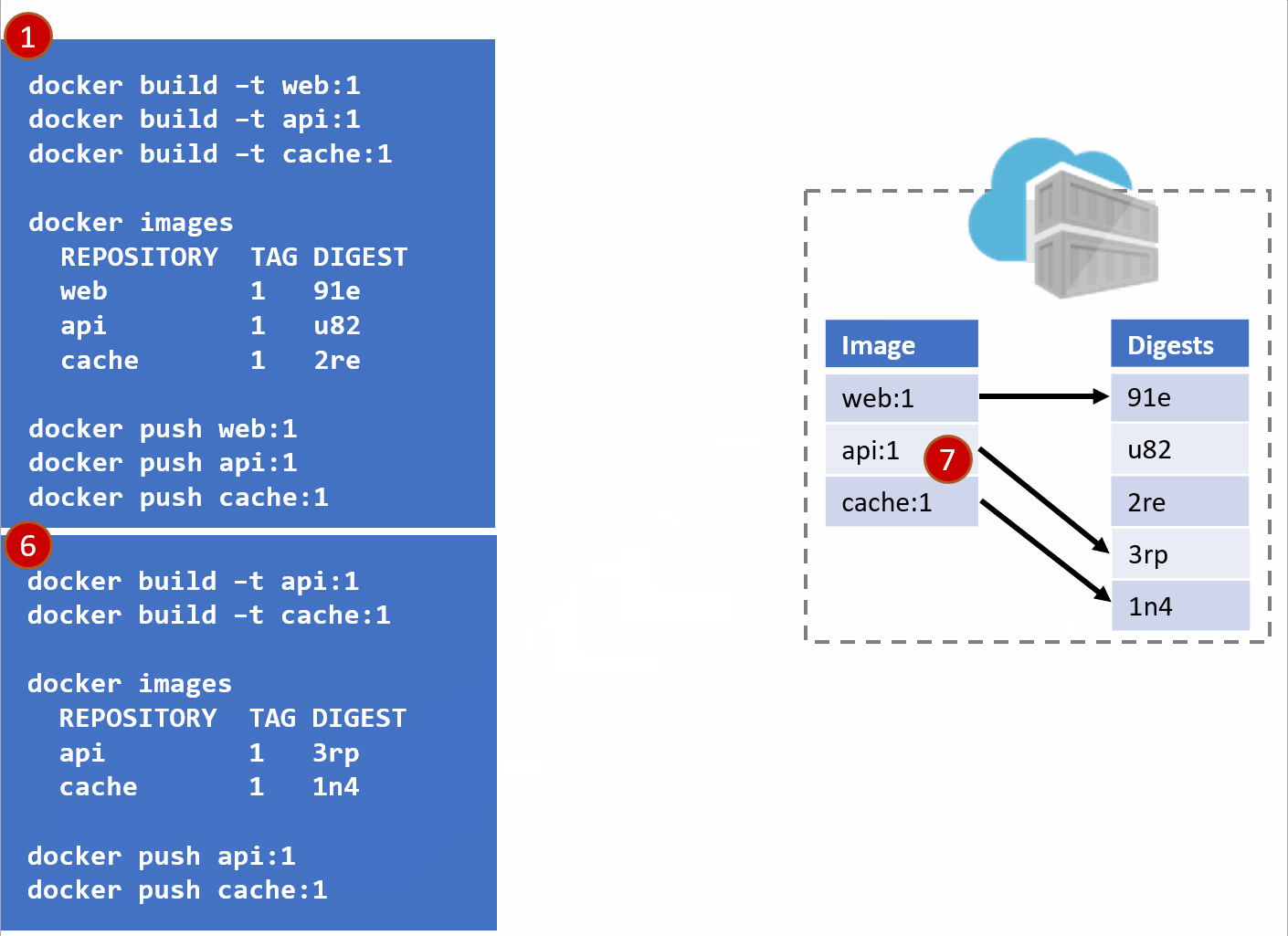
In the above diagram, we have:
- a local build of 3 images:
web:1, api:1, cache:1. Looking closely, we can see every tag has an ID, otherwise known as a digest. - When the images are pushed to a registry, they are stored as two parts. The image:tag, and the underlying digest. These are actually separate elements, with a pointer between them.
- A deployment is made, using the tag. Not the digest. Although, that is an option. Digests aren't as clean as I show here. They actually look like this:
f3c98bff484e830941eed4792b27f446d8aabec8b8fb75b158a9b8324e2da252. Not something I can easily fit in this diagram, and certainly not something you'd want to type, or even try and visually find when looking at the containers running in your environment. - When a deployment is made to a host, the orchestrator keeps track of what you asked it to deploy and keep deployed. This is the important part. ...wait for it...
- With a deployment saved, the orchestrator starts its work. It evaluates what nodes it has to work with and distributes the request.
A few things here. While many would argue Kubernetes has become the defacto standard for container orchestrators, orchestration is a generalized concept. Over time, we expect orchestration to just become the underpinnings to higher level services. But, that's another post...
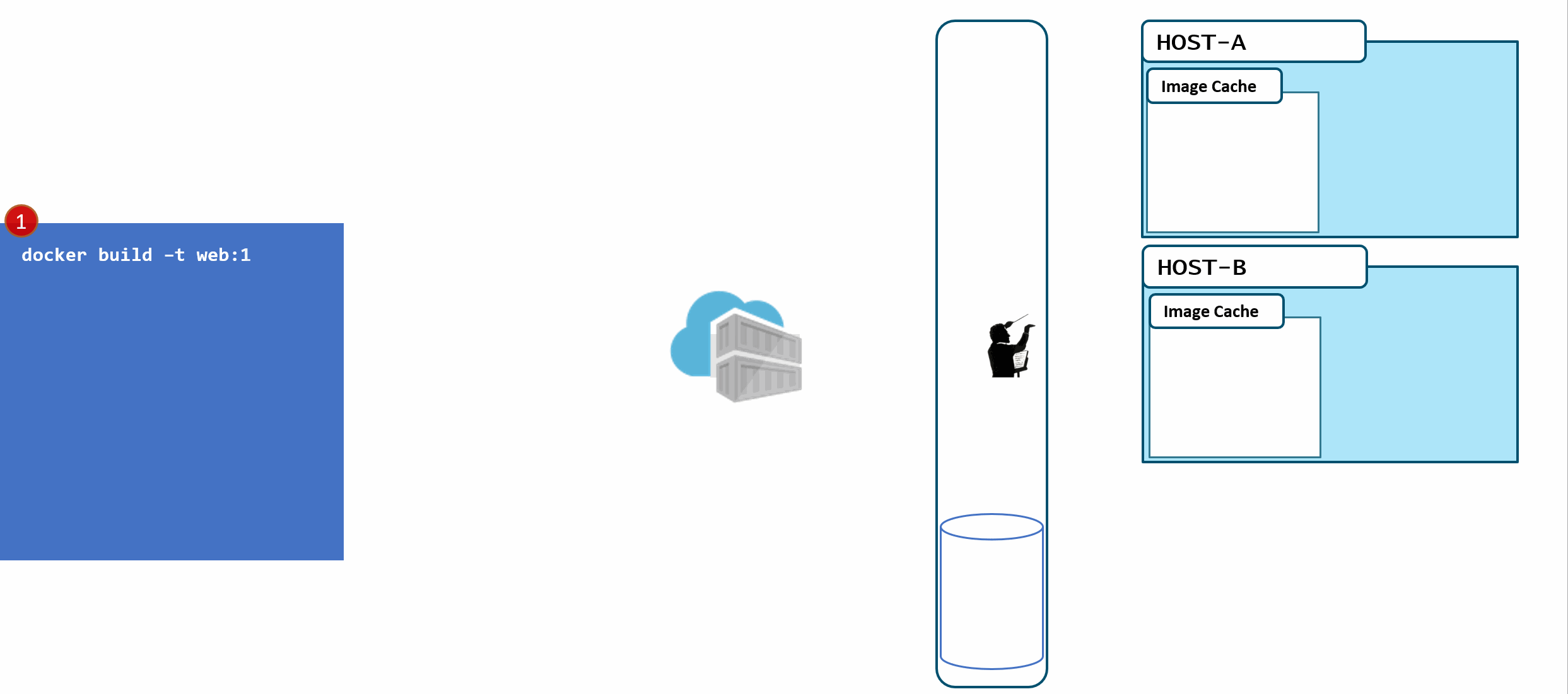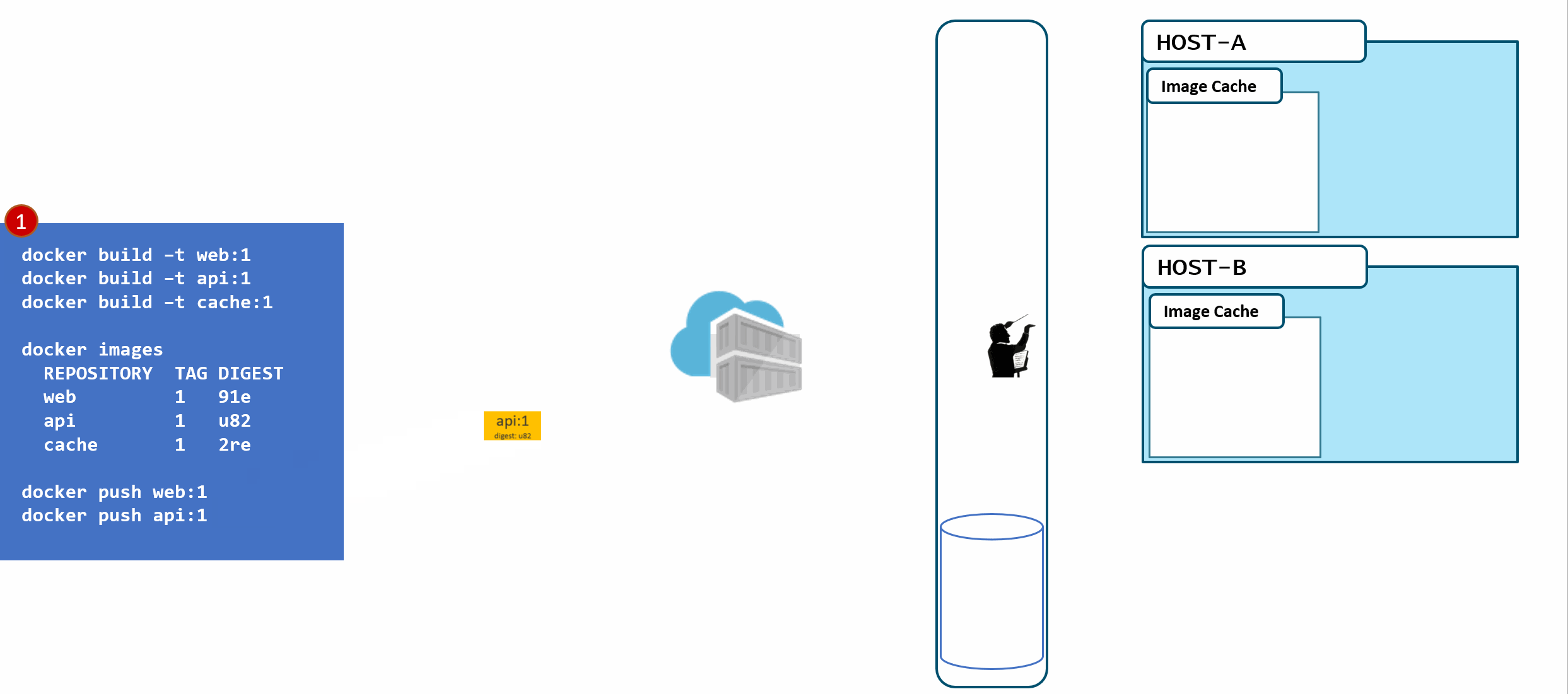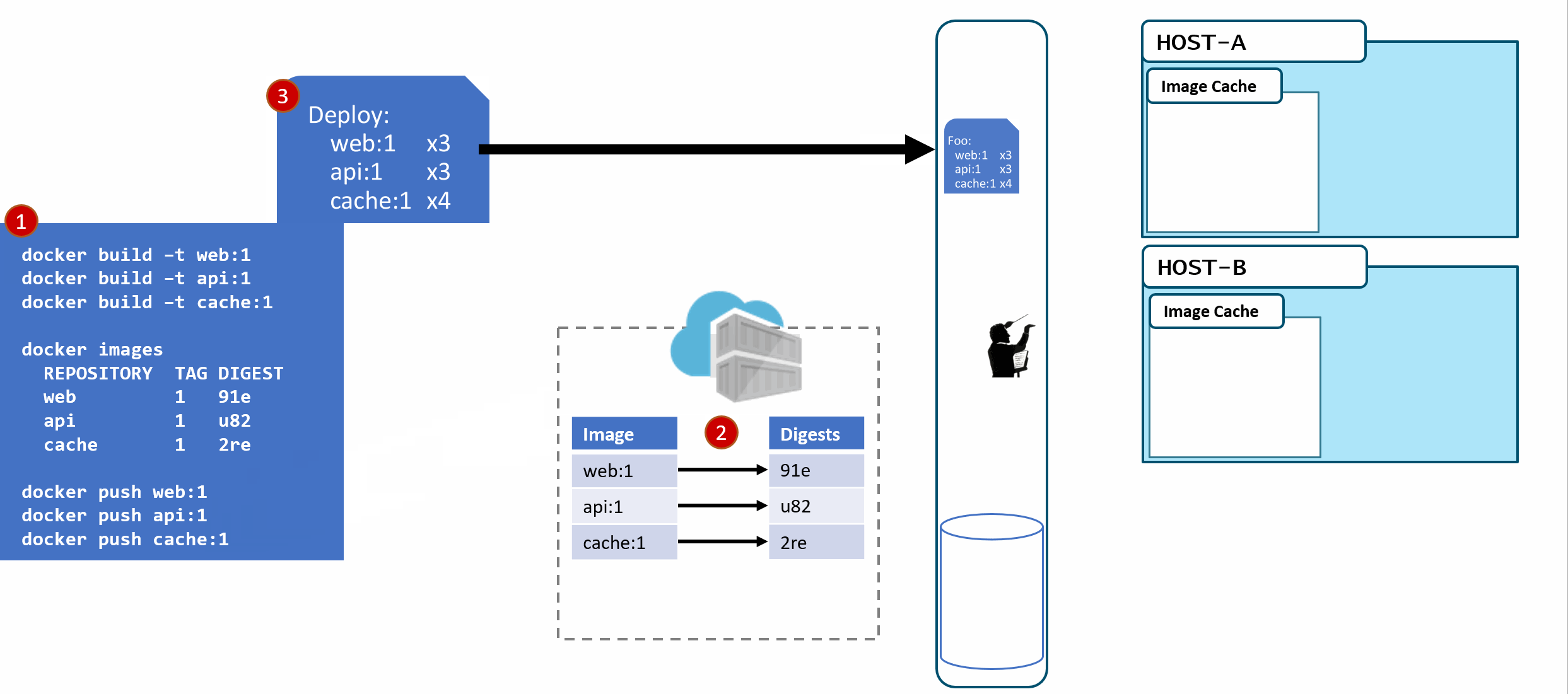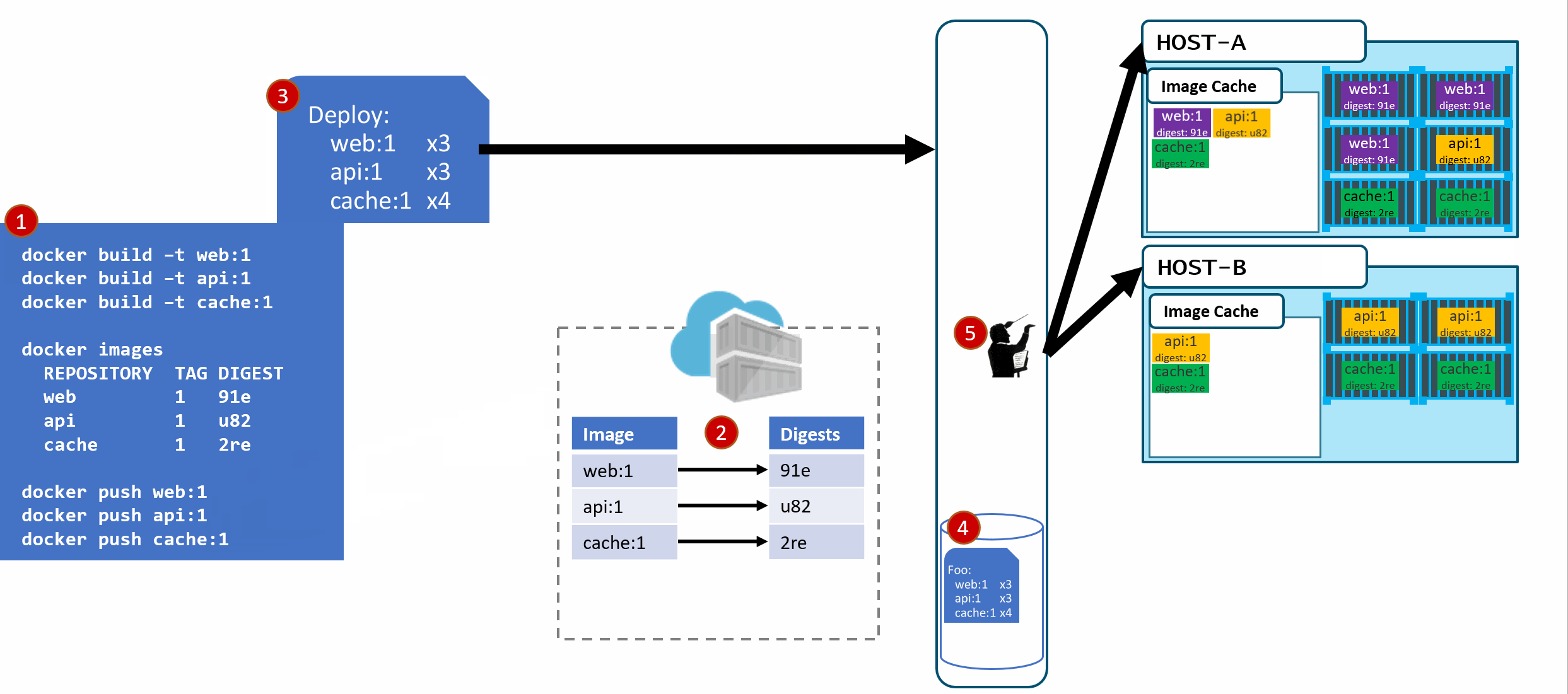
- As our development team moves along, a new version of the api and cache are built and pushed. Since this is just a minor fix to version 1, the team uses the same tag.
- Our registry acknowledges the request, saving the new :1 version of the api and cache. Notice the original tags are now pointing to the new digests (3rp, 1n4)
At this point, you likely see where this is going.
- As Pat would say "Stuff Happens". Actually, Pat would say something else. Our Host-B node has failed.
- No problem, our orchestrator's job is to maintain a requested deployment.
It sees the failure, evaluates the request made of it, and provisions the necessary resources to recover.
Our deployment chart clearly says, keep 3 copies of web:1, 3 copies of api:1 and 4 copies of cache:1. So, it does a docker run of each of those image:tag combinations. It's doing what it was told.
Our Host-C now has the replacement images running
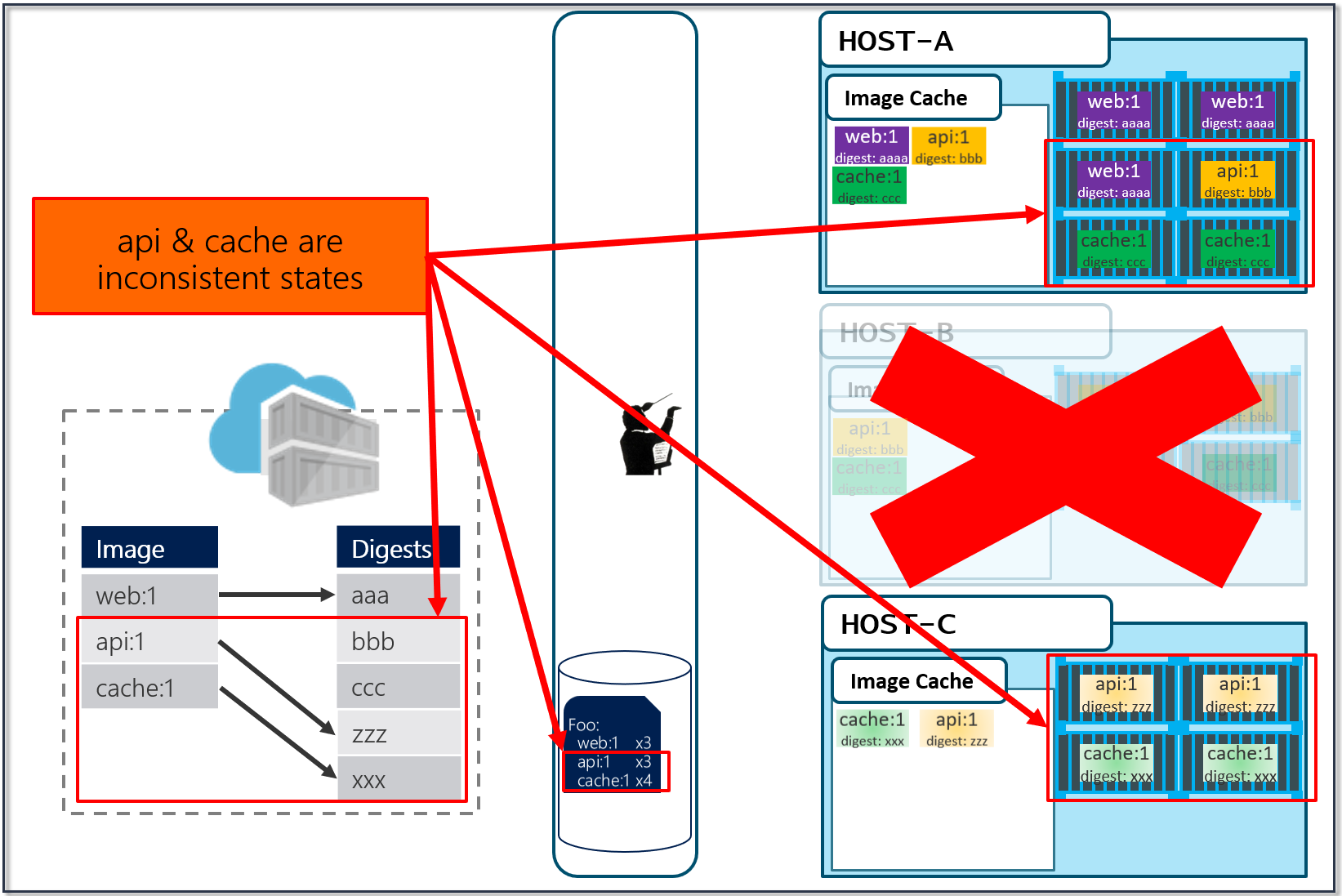
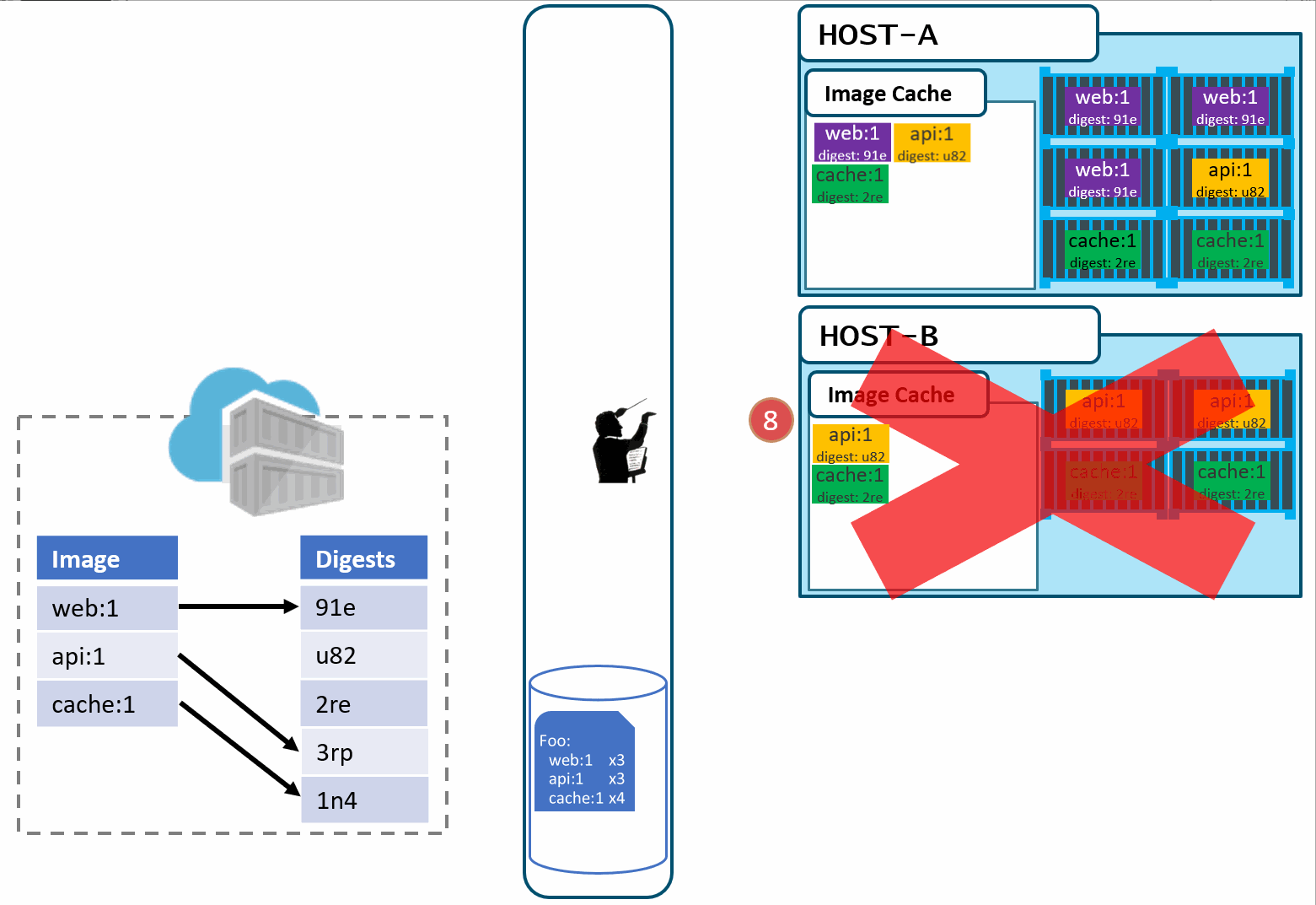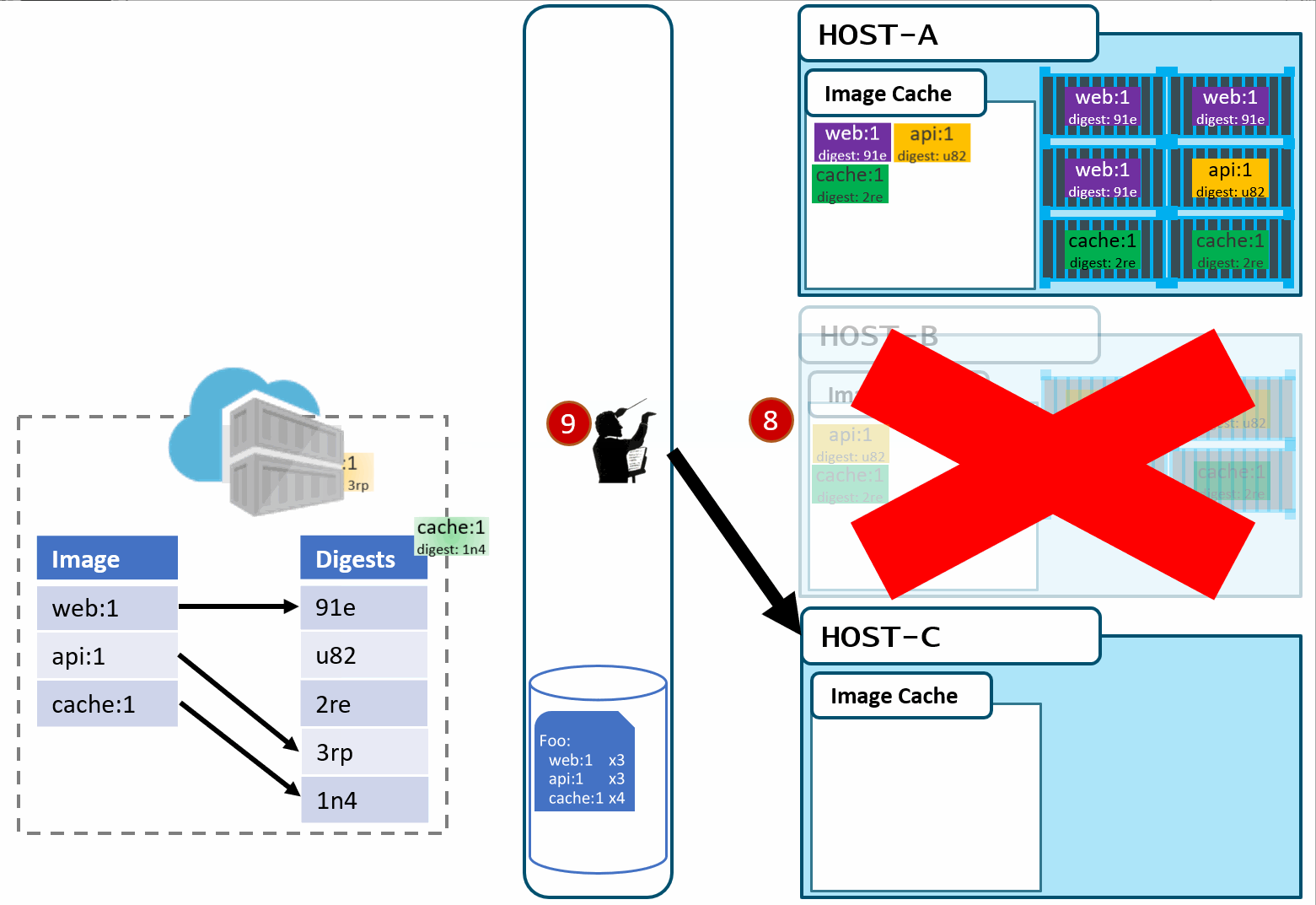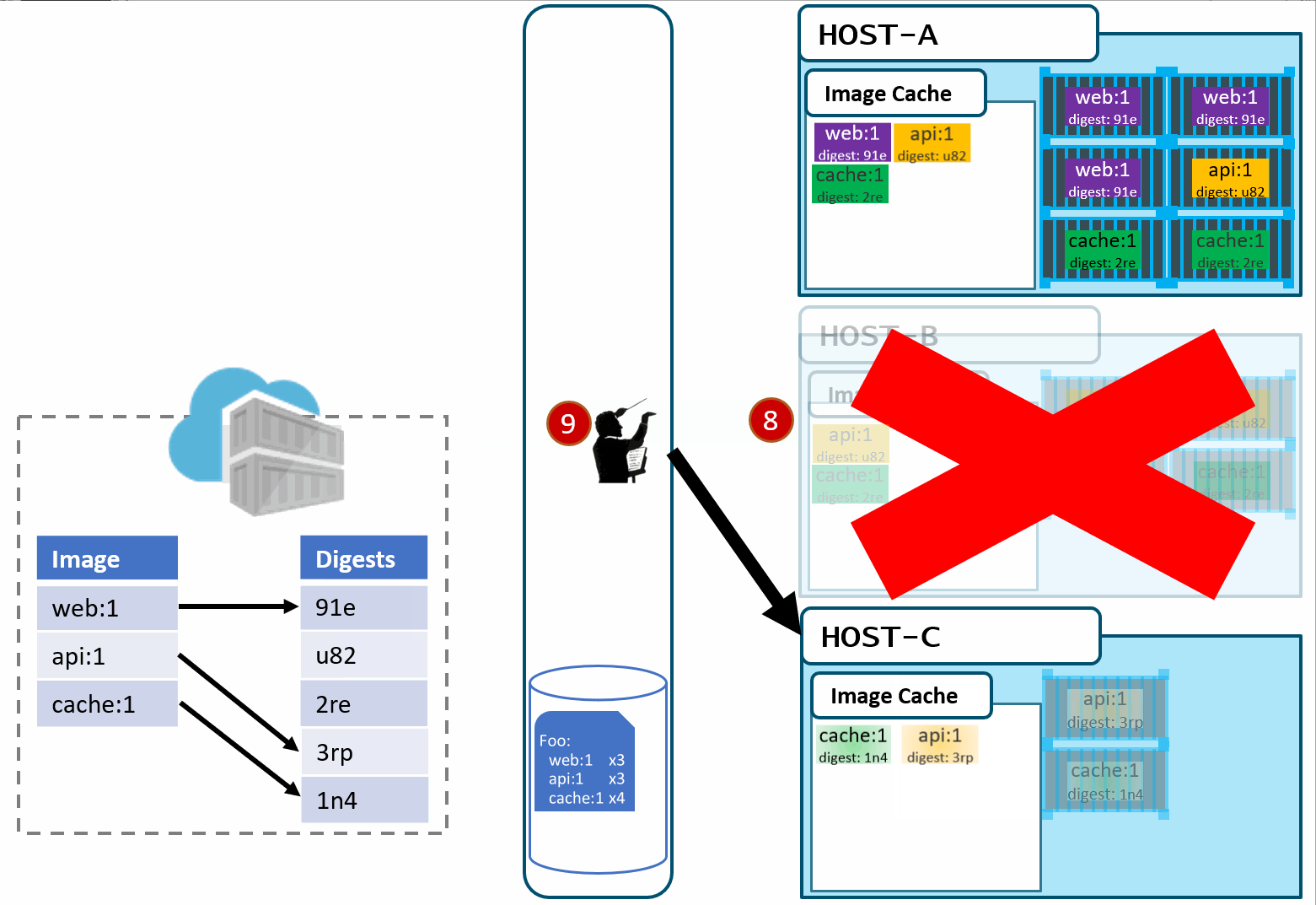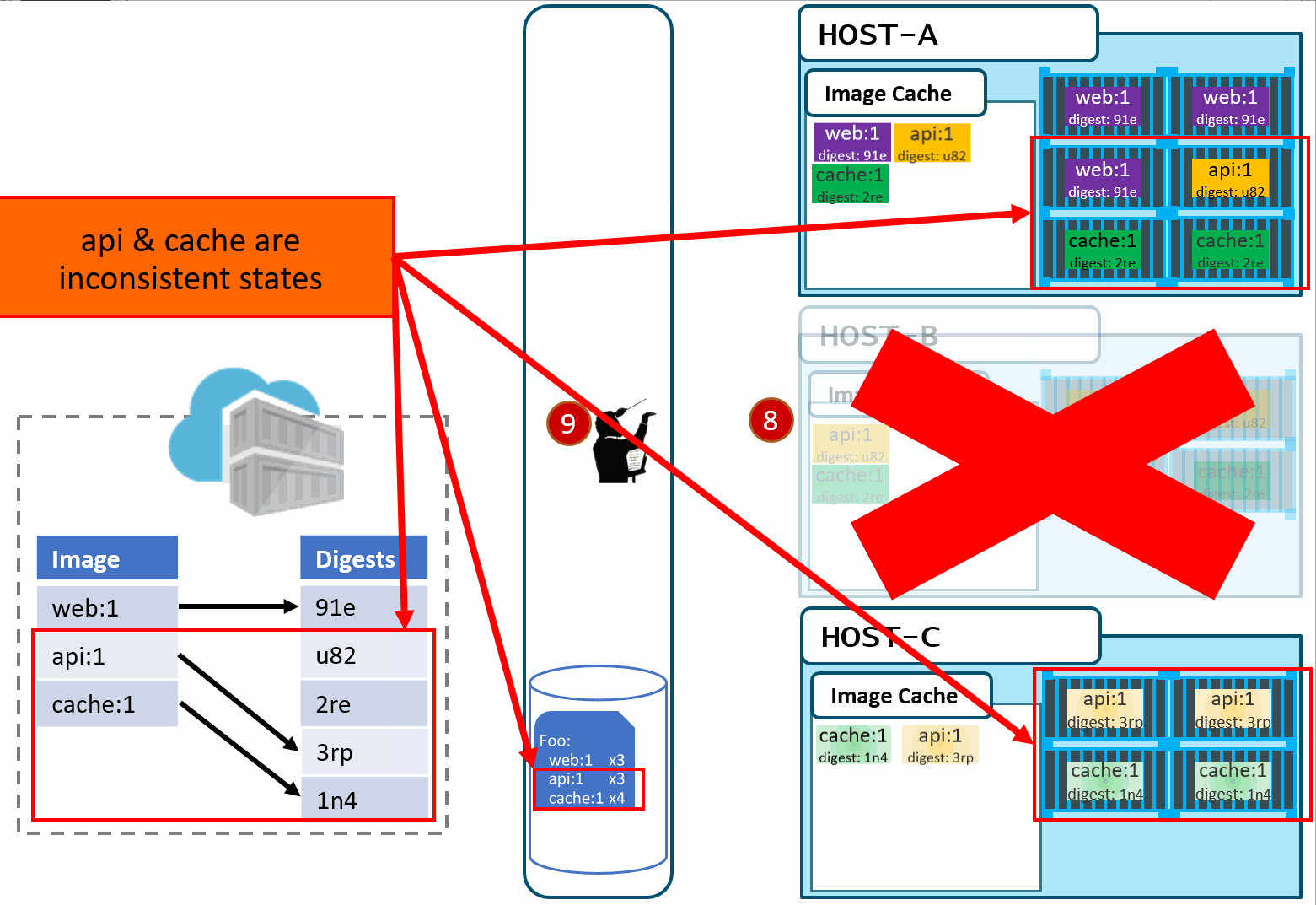
Is this the desired state you want? The orchestrator did it's job. It was told to deploy and maintain a given set of images.
The problem was actually further upstream, when we re-used the same tag for our images.
Now, if you're like most people, you're likely thinking:
- I can deploy with the digest - yup, and you can view lots of these:
f3c98bff484e830941eed4792b27f446d8aabec8b8fb75b158a9b8324e2da252 - I can use semantic versioning, and always bump the number - yup, that sort of works, but read on
- I can use my git commit id - that's pretty good as each commit is unique, and you can easily match a container image to its source. However, do you only rebuild your images when your source changes? ...read on
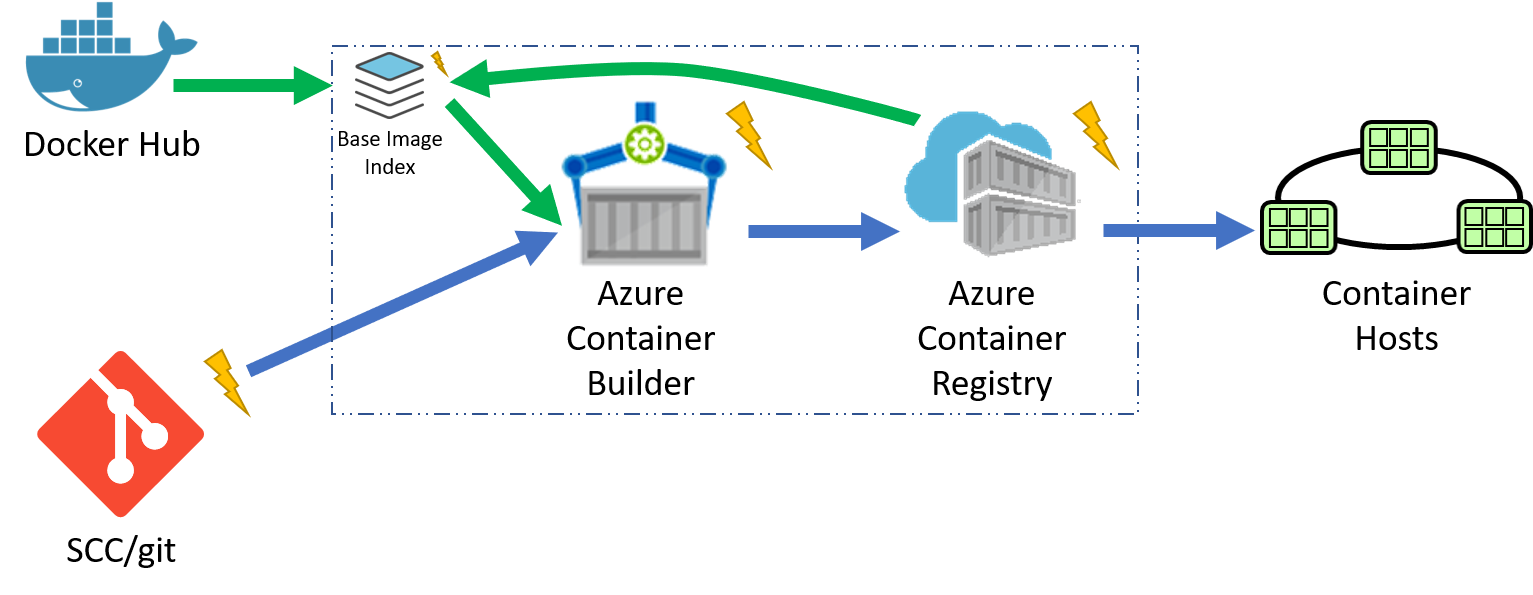
OS & Framework Patching
While I believe in "never say never", using stable tags for deployments are fraught with problems. However, Stable Tags do have their value.
Let's consider what happens when developers stop checking in code changes. In the VM world, Ops would continue to patch the running hosts for updates to the framework and patches to the host operating system. And, at some point, those patches may break the apps running on those nodes. One of the many benefits of containers are the ability to isolate the things our apps and services depend upon. Those dependencies are contained within our image, declared within our dockerfile.
A multi-stage dockerfile for an aspnetcore app, based linux FROM microsoft/aspnetcore:2.0 AS base WORKDIR /app EXPOSE 80FROM microsoft/aspnetcore-build:2.0 AS build WORKDIR /src COPY HelloWorld.sln ./ COPY HelloWorld/HelloWorld.csproj HelloWorld/ RUN dotnet restore -nowarn:msb3202,nu1503 COPY . . WORKDIR /src/HelloWorld RUN dotnet build -c Release -o /appFROM build AS publish RUN dotnet publish -c Release -o /appFROM base AS final WORKDIR /app COPY --from=publish /app . ENTRYPOINT ["dotnet", "HelloWorld.dll"]
In the above example, we can see two images. The aspnetcore-build:2.0 image to compile our code, then we copy the output from our build image to an optimized asnetcore:2.0 image. See: .NET and MultiStage Dockerfiles for more details
For the focus of tagging and OS & Framework patching, notice our base image, used for the image we actually deploy.
FROM microsoft/aspnetcore:2.0 AS base
You can see we're using the stable tag, 2.0. This is where semantic versioning does play a role. The ASP.NET Core team releases new capabilities, indicated by the major version. They shipped 1.0, 2.0 and you can imagine they'll continue to ship new capabilities. In the real world, new capabilities means things change, behaviors change, and thus, you want the development team to make a conscious choice which major version of aspnetcore they depend upon. This basic pattern is used across all major frameworks, java, go, node, etc.
While the team focuses on new capabilities, they must also service each version. The aspnetcore image contains aspnetcore, dotnet core, as well as linux or windows server nanao base layers, depending on which architecture you're running. How do you get OS & Framework updates? Should you have to bump your FROM statement for every release? While the team will publish additional tags for minor, non-breaking changes, each team does update their stable major tags.
This does mean, depending on when you pull aspnetcore:2.0, you'll get different content. But, that's the intent. Whenever you pull the stable tag, you should get the latest OS & Framework patched image. I say should as not all repo owners do proper maintenance on their images. Why, because it's actually pretty hard. (insert smallest fiddle) .
To stay focused on tagging schemes, I'll point you this post on OS & Framework Patching with Docker Containers – a paradigm shift.
What Tagging Scheme Should I Use?
Stable Tags
Stable tags mean a developer, or a build system can continue to pull a specific tag, which continues to get updates. Stable doesn't mean the contents are frozen, rather stable implies the image should be stable, for the intent of that version. To keep it "stable", it's serviced to keep the evil people from corrupting our systems. (ok, evil can also be a simple mistake that has huge impacts)
An example:
A framework team ships 1.0. They know they'll ship updates, including minor updates. To support stable tags for a given major and minor version, they have two sets of stable tags.
- :1 - a stable tag for the major version. 1 will represent the "newest" or "latest" 1.* version.
- :1.0 a stable tag for version 1.0, allowing a developer to bind to updates of 1.0, and not be rolled forward to 1.1
- :latest which will point to the latest stable tag, no matter what the current major version is.
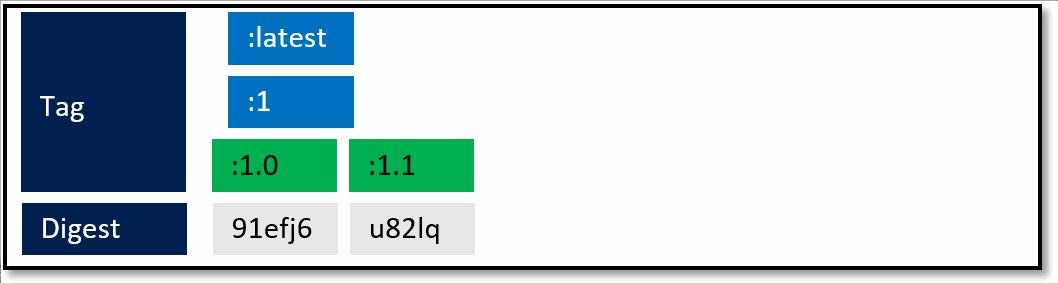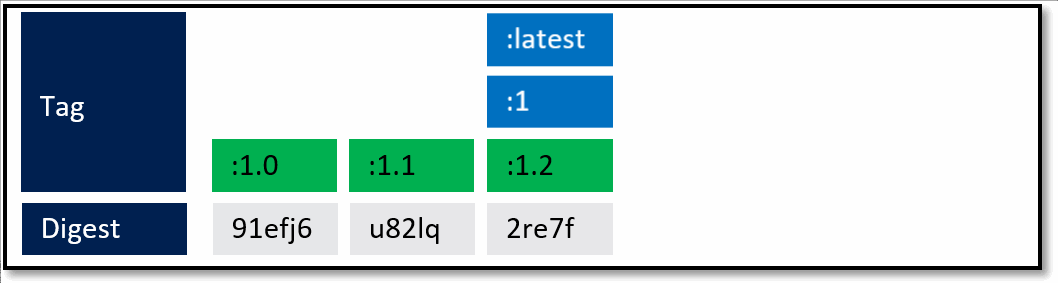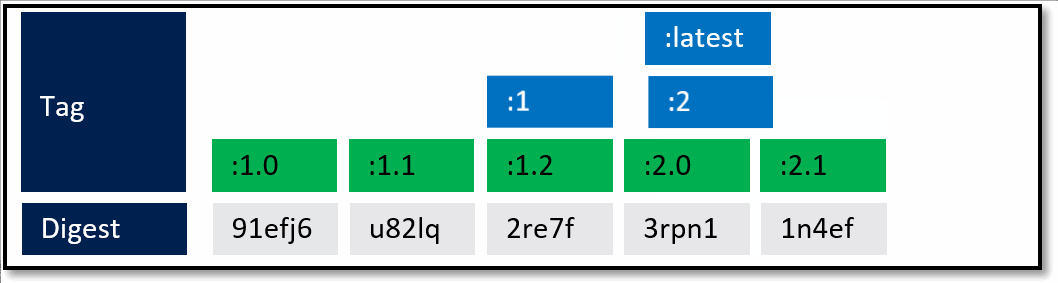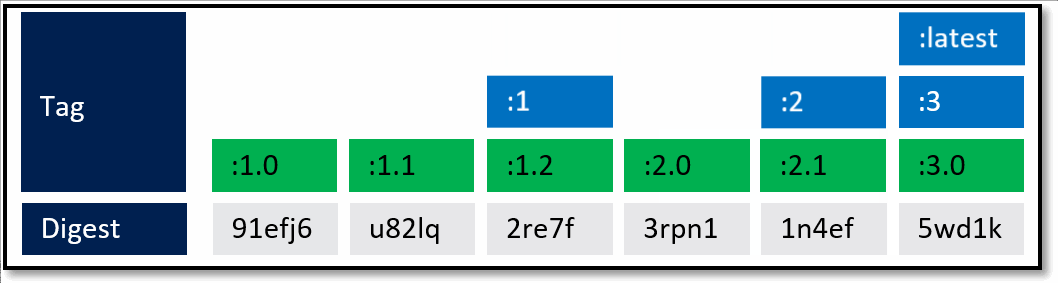
What's not quite captured above are servicing releases to any of the given tags. As base image updates are available, or any type of servicing release of the framework, the stable tags will be updated to the newest digest that represents the most current stable release of that version.

In the above example, updates are provided for the specific versions. In this case, both the major and minor tags are continually being serviced. From a base image scenario, this allows the image owner to provide serviced images.
If you really wanted to bind to a specific image, that never changes, you'd set your FROM statement to the digest.
FROM favframework@sha256:45b23dee08asdfls3a7fea6c4cf9c25ccf269ee113ssc19722f87876677c5cb2
However, I'd highly suggest "never" doing binding to a digest. Yeah, I went there - never. If you bind to the digest, how would you get servicing of your base image?
Unique Tagging
Unique tagging simply means, every image pushed has a unique tag. Tags are "never" reused. We've had a number of customers request the ability to enforce this policy, which we'll be adding to ACR. Along with several other policies.

What value should use for your unique tags?
There are a number of options.
git commit- works until you start supporting base image updates, where your build system will kick off, with the same git commit as the previous built. However, the base image will have new content. Using a git commit winds up being a semi-stable tag.- date-time-stamp - this is a fairly common approach as you can clearly tell when the image was built. But, how do correlate it back to your build system? Do you have to find the build that was completed at the same time? What time zone are you in? Are all your build systems calibrated to UTC?
- digest - it's unique, or should be. But, it's really not usable as it's just toooooo long. And, it doesn't really correlate with anything easily found.
- build id - this one is closest to the best as its likely incremental, gives you correlation back to the specific build to find all the artifacts and logs.
- <build-system>-<build id> - If your company has several build systems, prefixing the tag with the build system helps you differentiate the API team's Jenkins build system from the Web teams VSTS build system.
Wrapping up
Whew, that was a lot... As with many things, an answer, especially a best practice, depends on ___. Hopefully I've given some context for the various tagging schemes, and the reasoning behind them.
To summarize:
- Use stable tagging for base images
"Never" deploy with stable tags as deploying stable tags leads to instability - Use unique tags for deployments
as you likely want deliberate deployments of a consistent version of components. Your hosts won't accidentally pull a newer version, inconsistent with the other nodes when "stuff" happens - Use build id's
for your deployed images, so you can correlate it back to the rest of the information in your build system
You may have a good reason for deploying stable tags such as a test environment. But, just realize that images will be updated underneath, and you can very easily spend hours troubleshooting a node that pulled a slightly different version of that tag.
Some things to also consider:
- Container best practices are evolving
- The underlying technology is evolving
- You're learning. I like to remind people, learning docker takes a day to realize it's cool, but 3 months to really "get it". Then, you're really just getting started
- I'm just a person with an opinion, and I've very possibly missed something. Tell me what you think...
Steve
When you stop learning, you start dying... PowerPoint deck with the animations used in the gifs