SQL Server Updates behavior
Recently a client asked me:
“We want to place all the fields of the table in the SET clause of an UPDATE, no matter if the values are changed or not. How does it impact the I/O? Does SQL Server update every field, even if the old value matches the new one? What about indexes?” It’s a common scenario: the application loads lots of data in a form, then a user change from one value up to every value in the form, then saves the changes. They want to avoid checking which field was updated on client side and deal with complex T-SQL underneath. They want to update everything.
Makes sense. Let’s start digging!
I need to create a table with a bunch of rows and a few indexes
Then write a few updates queries:
A good starting point is the queries execution plans.
Here's how a couple of execution plans look like from my update queries:

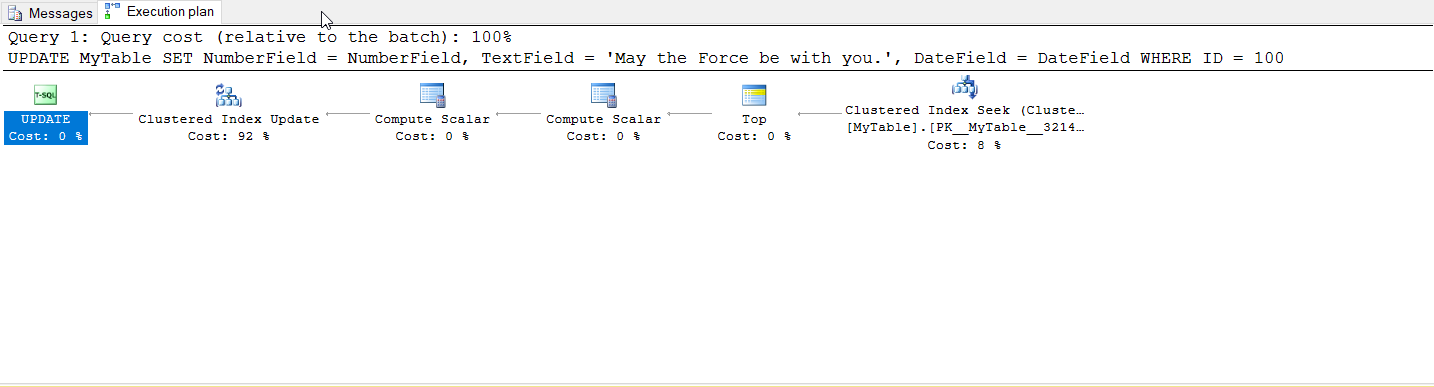
The execution plan is computed before the actual query execution and does not take in account if the fields are to update or not. But in the execution plans there are some “compute scalar” operators. Maybe SQL Server use them to check if the field need to be really updated or not, at least I have a clue.
A closer look to the buffer pool will help me to find the answer, here the DMV sys.dm_os_buffer_descriptors comes handy.
This DMV returns a description about all the pages that are in SQL Server Buffer pool. The keystone here is colum “is_modified”, that marks dirty pages. My plan is to run a “real” update query and a “matching” update query. After each run check what’s in the DMV.
This is the query that I use in this case to check the status of the pages in the buffer pool.
To be sure that pages are clean, I will issue a checkpoint before each test..
If i run a "not" update query, pages in the buffer pool stay clean.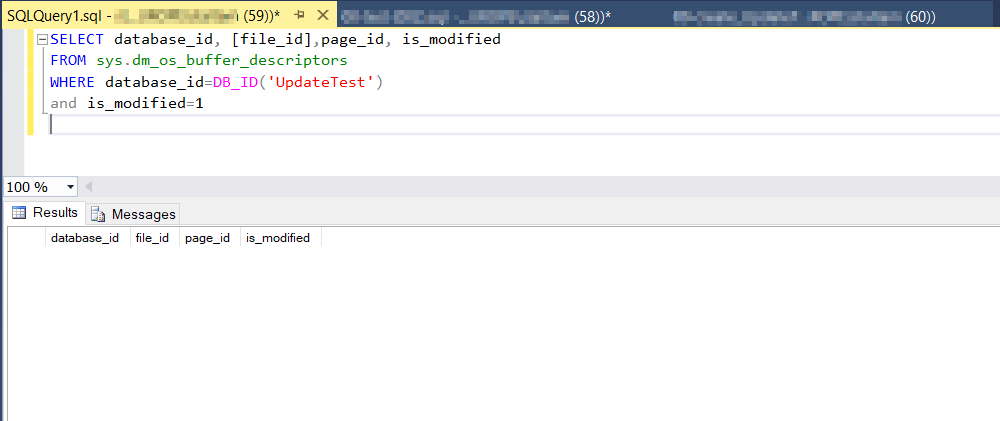
If I run a "real" update query lots of pages in the buffer pool now are dirty:
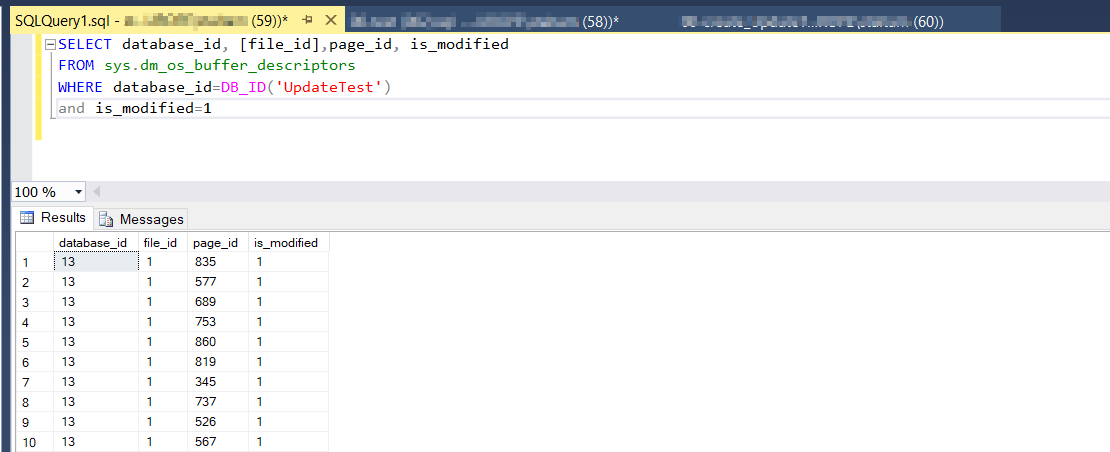
SQL Server is always efficient! Sadly this not means that your I/O is safe.
If you look closer to the execution plans, you will see that SQL Server Engine needs to check if an update is "real" or not, the only way to do it is to perform some reads.
If the plan uses a non-clustered index that does not cover the query a lookup in the cluster index is needed.
Always check your execution plan to avoid expensive read operations!
Have Fun
Stefano
PS: I want to thank my colleague, mentor and dear friend Francesco (check out his blog!) for the wonderful discussion that we had about this topic and the ways to demonstrate it. This is only a quick and simple method!