Introducing Batch Mode on Rowstore
Last year SQL Server 2017 and Azure SQL Database introduced query processing improvements that adapt optimization strategies to your application workload’s run-time conditions.
These improvements included: batch mode adaptive joins, batch mode memory grant feedback, and interleaved execution for multi-statement table valued functions.
In the SQL Sever 2019 preview, we are further expanding query processing capabilities with several new features under the Intelligent Query Processing (QP) feature family. In this blog post we’ll discuss one of these Intelligent QP features that is now available in public preview, batch mode on rowstore. This feature unlocks the advantages of batch mode execution in cases where there is no columnstore participating in the query.
Batch mode is a different execution mode primarily targeted at analytics queries which are characterized as scanning many rows, and doing significant aggregations, sorts, and group-by operations across these rows. Batch mode has been reserved for queries which involve columnstore indexes until now.
Performing scans and calculations using batches of ~ 900 rows at a time rather than row by row is much more efficient for analytic-type queries. For queries that can take advantage of it, batch mode can easily make queries execute many times faster than the same query against the same data in row mode.
To illustrate the differences, I’ll present an example query which is run against an enlarged version of the WideWorldImportersDW database. We used this query, and ran it to compare between running in row mode and batch mode:
SELECT [Lineage Key],
SUM([Quantity]) AS SUM_QTY,
SUM([Unit Price]) AS SUM_BASE_PRICE,
SUM([Unit Price]*(1+[Tax Rate])) AS SUM_DISC_PRICE,
SUM(([Unit Price]+[Total Including Tax] )*(1+[Tax Rate])) AS SUM_CHARGE,
AVG([Quantity]) AS AVG_QTY,
AVG([Unit Price]) AS AVG_PRICE,
COUNT(*) AS COUNT_ORDER
FROM Fact.[Sale]
WHERE [Invoice Date Key] >= DATEADD(dd, -73, '1998-12-01')
GROUP BY [Lineage Key]
ORDER BY [Lineage Key];
First, we run the query with traditional row mode processing...
Row Mode Processing
Below, you see the query plan with the various operators. If you hover over any of these, you’ll see that they all are running in row mode.
 I’ve right-clicked on the Clustered Index Scan node (farthest operator to the right), and chosen Properties, to display the properties of this operator:
I’ve right-clicked on the Clustered Index Scan node (farthest operator to the right), and chosen Properties, to display the properties of this operator: 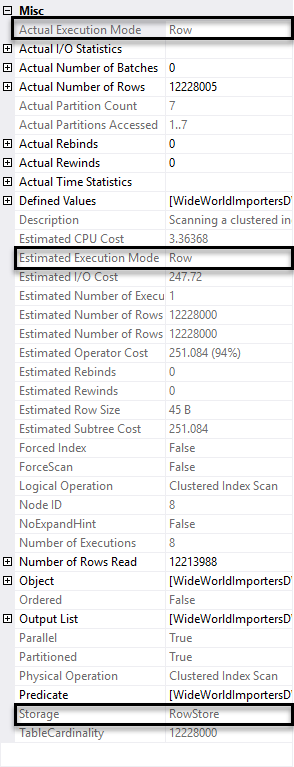
Note that the Actual Execution Mode is “Row”, and that the Storage is “RowStore”. The query returns in approximately 10 seconds on my desktop machine, as shown below:

Batch Mode Processing
Now, we take the same database with the same query, and enable batch mode rowstore by setting the database compatibility level to "150" (a public preview database compatibility level used for the next round of QP features).
You’ll note that there are some minor differences in the query plan, as batch mode processing is able to perform aggregates as part of the scan operation, and handles parallelism differently.
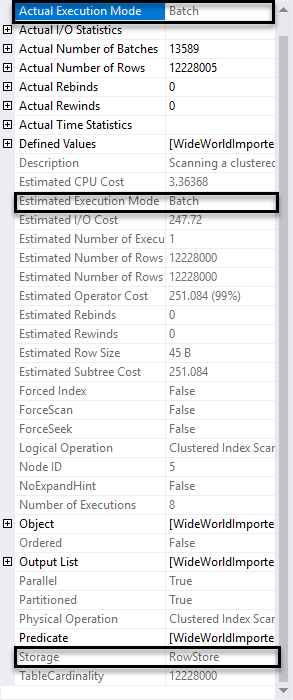
Again, we look at the Properties of the Clustered Index Scan:

Here we see that as expected, the Storage is “RowStore”, but the Actual Execution Mode is now “Batch”.
And the results come back in a little under 1/3 the time of the same query against the same table in row mode.

Application
There are many cases where the data set and the query characteristics would make a great match for batch mode processing, but the table is not a good candidate for columnstore indexes:
- It may be a table with a very high update rate, which can degrade columnstore performance if not mitigated properly
- It may be a legacy table which was created before columnstore indexes were available, or where the schema cannot be changed.
Not suited to every situation
While batch mode can significantly improve analytics queries, the strategy of processing hundreds of rows as a group will not help all queries. Queries that target only a few rows, or that do not perform significant aggregations will not see significant gains.
Results
This is the power of the batch mode on rowstore feature: For queries that need aggregations across a large numbers of rows which batch processing was designed for, the results in terms of query speed and efficiency are very impressive. In this small example, the execution time for the same query, with the same data set, on the same hardware went down from 10 seconds to 3 seconds. That’s over 3 times faster with no application or query changes!
We hope that you have an opportunity to test this new feature! If you have feedback on this feature or other features in the Intelligent QP feature family, please email us at IntelligentQP@microsoft.com. Thanks!