Azure SQL Database – scalability
Azure SQL Database is a flexible Platform as a service database that can be easily scaled to fit your needs. You can add more compute or storage to satisfy your performance requirements without waiting for new hardware or migrating data to more powerful machines. Azure enables you to change performance characteristics of your database on the fly and assign more resources when needed or release the resources when they are not needed in order to decrease the cost.
Azure SQL Database supports two types of scaling:
- Vertical scaling where you can scale up or down the database by adding more compute power.
- Horizontal scaling where you can add more databases and to shard your data into multiple database nodes.
[caption id="" align="alignnone" width="859"] Horizontal and Vertical scaling[/caption]
Horizontal and Vertical scaling[/caption]
You would need to scale up your database if you see performance issues that cannot be solved using classic database optimization techniques such as query changes, indexing, etc., and you need to quickly react to fix performance issues. Vertical scaling is useful if you notice some spikes in your workloads where the current performance level cannot satisfy all requests, so you can easily handle peak workload by adding more resources, and go back to the original state when the resources are not needed anymore.
If you cannot get enough resources even on the highest performance level, you might consider horizontal scaling. In horizontal scaling you can split your data in several databases (shards) and every shard would can be scaled up or down independently.
Scaling up/down
Scaling up refers to a process of adding more resources to the database in order to achieve better performance. You can scale-up your database if you see that your workload is hitting some performance limit (e.g. CPU or IO).
Azure SQL Database enables you to choose how many CPU you want to use, how much storage you need, and to dynamically change these parameters any time. Then you can simply add more CPU power or storage if the current resources cannot handle your workload.
As an example, you can create an Azure SQL Database with 16 cores and 500GB storage, and then increase or decrease these numbers depending on your needs.
Changing CPU or storage in instance can be done via Azure portal using simple slider:

Any change that you made will be almost instant. There is no additional provisioning, attaching disks, etc. Database will be reconfigured using the values that you set in the slider, and Azure SQL Database will immediately get more resources.
There is another model called DTU-based model where you put your database in pre-defined performance class (for example, 100DTU, 200DTU, etc.) Every DTU class is a resource bounding box where you are getting maximum number of CPU, Memory, IO Read and Write operations for that class:
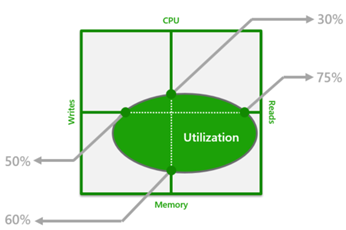
The ratio of CPU/memory/read/writes is calibrated based on Azure SQL Database benchmarks and optimized for generic workloads. Azure SQL Database guarantees that you will always have the amount of resources defined in the DTU class. As long as none of the dimensions in the DTU bounding box reach the limit, your workload can be executed on the selected DTU class without need to scale-up the database. If you are hitting some limit, you would need to go to the higher class.
Another way for scaling up/down is changing service tier from Standard/General Purpose to Premium/Business Critical. In Standard/General Purpose you are getting classic infrastructure with data stored on Azure premium disks, while in Premium/Business Critical you are getting data on local SSD. Switching between these tiers is usually long-term decision that is made if you determine that standard architecture cannot satisfy your latency requirements.
Read scale-out
If your workload is hitting the limit of available resources, and you cannot scale-up database to fix the issues, another option would be to redirect part of your workload to another database node.
Databases in the Premium (DTU-based model) or in the Business Critical (vCore-based model) have several replicas to support the high-availability. Usually these replicas just collect data from primary node, apply changes, and activate if primary node fails.
The Read Scale-Out feature allows you to use the capacity of the read-only replicas for read-only queries. This way the read-only workload will be isolated from the main read-write workload and will not affect its performance. The feature is intended for the applications that include logically separated read-only workloads, such as analytics, and therefore could gain performance benefits using this additional capacity at no extra cost.
The main benefits of Read Scale-Out are:
- Primary database node will not spend resources on the read-only/analytic queries because they are not sent to the primary node anymore. Saved resources might be used to improve the performance of writable workload.
- You can use resources on secondary nodes to handle heavy reports and analytical queries.
Redirecting read-only/analytical queries to secondary replicas is easy. Once you enable read scale-out you can add ApplicationIntent=ReadOnly; property into the connection string for your analytic queries and these queries will be sent to the secondary replica.
Note that data stored in secondary replica might not be identical to the data in primary database. For the performance reasons, process of moving changes from primary to secondary nodes is asynchronous so you might net see the latest data in secondary node. Use secondary read-only replicas if you are planning to run some analytic reports that don’t need precise/exact latest data (e.g. monthly/weekly reports).
Global Scale-out/Sharding
Sharding is approach where you split your data into multiple database nodes. This way you can scale-out your data into several database shards. Every database shard is an independent database where you can add or remove resources as needed. There is also a Elastic Database split-merge tool that enables you to move data between shards and reorganize your data distribution.
Sharding might be useful architecture choice if you have geo-distributed application where every application should access part of data in the region. Every application may access only the shard associated to that region without affecting other shards.
Another scenario where global sharding might be useful is load balancing. You can have a large number of geo-distributed clients that insert data in their own dedicated shards.
You can also use sharding if you cannot get good performance even in the highest performance tiers, or if your data cannot fit into a single 4TB database.
Azure SQL Database enables you to create, manage, and use sharded data using the following libraries:
- Elastic Database client library: The client library is a feature that allows you to create and maintain sharded databases.
- Elastic Database split-merge tool that moves data between sharded databases. This is useful for moving data from a multi-tenant database to a single-tenant database (or vice-versa).
- Elastic Database query(preview): Enables you to run a Transact-SQL query in SQL database that spans multiple databases.
- Linked servers that are available in Azure SQL Managed Instance where you can create a link to remote shard and execute remote queries.
- Elastic client transactions that allow you to run transactions that span several databases in Azure SQL Database. Elastic database transactions are available for .NET applications using ADO .NET.
- Elastic Database jobs(preview): Use jobs to manage large numbers of Azure SQL databases. Easily perform administrative operations such as schema changes, credentials management, reference data updates, performance data collection, or tenant (customer) telemetry collection using jobs.
Using these tools, you can create as many as needed shards and run the queries on one or multiple shards.
Conclusion
Azure SQL database is scalable database platform as a service that enables you to easily increase or remove resources in your database, offload queries to secondary nodes or implement full sharding solution. You have a variety of options to design scalable architecture where the database will adapt your application workload.