Sentiment analysis with Python in SQL Server Machine Learning Services
One very popular machine learning scenario is text analysis. In this blog post, we will show you two different ways in which you can implement sentiment analysis in SQL Server using Python and Machine Learning Services. This means analyzing text to determine the sentiment of text as positive or negative.
(If you don't know what SQL Server Machine Learning Services is, you can read more about it here.)
Sentiment analysis using pre-trained model
You don't have to be a data scientist to use machine learning in SQL Server. You can use pre-trained models available for usage out of the box to do your analysis. The following example shows you how you quickly get started and do text sentiment analysis.
Before starting to use this model, you need to install it. The installation is quick and instructions for installing the model can be found here: How to install the models on SQL Server
Once you have SQL Server installed with Machine Learning Services, enabled external script execution, and installed the pre-trained model, you can execute the following script to create a stored procedure that uses Python and the microsoftml function get_sentiment with the pre-trained model to determine the probability of positive sentiment of a text:
-- Create stored procedure that uses a pre-trained model to determine sentiment of a given text
CREATE OR ALTER PROCEDURE [dbo].[get_sentiment](@text NVARCHAR(MAX)) AS
AS
BEGIN
DECLARE @script nvarchar(max);
--The Python script we want to execute
SET @script = N'
import pandas as p
from microsoftml import rx_featurize, get_sentiment
analyze_this = text
# Create the data
text_to_analyze = p.DataFrame(data=dict(Text=[analyze_this]))
# Get the sentiment scores
sentiment_scores = rx_featurize(data=text_to_analyze,ml_transforms=[get_sentiment(cols=dict(scores="Text"))])
# Lets translate the score to something more meaningful
sentiment_scores["Sentiment"] = sentiment_scores.scores.apply(lambda score: "Positive" if score > 0.6 else "Negative")
';
EXECUTE sp_execute_external_script
@language = N'Python'
, @script = @script
, @output_data_1_name = N'sentiment_scores'
, @params = N'@text nvarchar(max)'
, @text = @text
WITH RESULT SETS (("Text" NVARCHAR(MAX),"Score" FLOAT, "Sentiment" NVARCHAR(30)));
END
GO
Let's run the stored procedure to get the sentiment of two product reviews:
--The below examples test a negative and a positive review text
-- Negative review
EXECUTE [dbo].[get_sentiment] N'These are not a normal stress reliever. First of all, they got sticky, hairy and dirty on the first day I received them. Second, they arrived with tiny wrinkles in their bodies and they were cold. Third, their paint started coming off. Fourth when they finally warmed up they started to stick together. Last, I thought they would be foam but, they are a sticky rubber. If these were not rubber, this review would not be so bad.';
GO
--Positive review
EXECUTE [dbo].[get_sentiment] N'These are the cutest things ever!! Super fun to play with and the best part is that it lasts for a really long time. So far these have been thrown all over the place with so many of my friends asking to borrow them because they are so fun to play with. Super soft and squishy just the perfect toy for all ages.'
GO
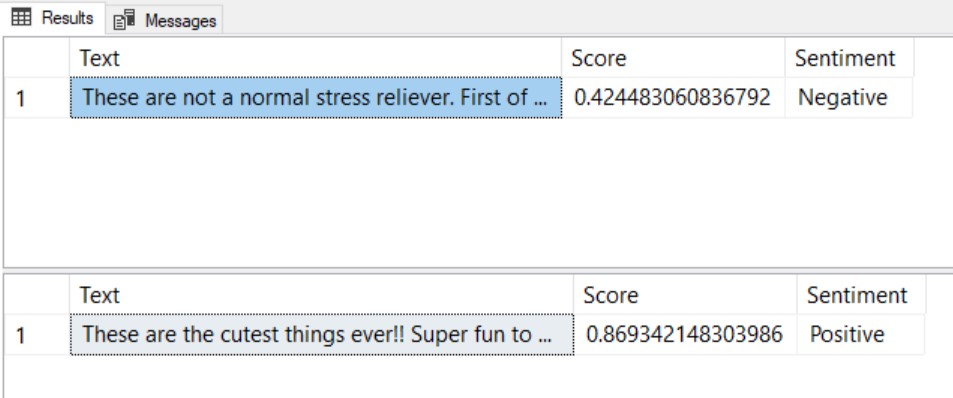
As you can see, the predictions were accurate. The model recognized the positive review as positive and the negative review got a lower score.
Train a model for sentiment analysis and score using that model
Now let's train our own model for sentiment analysis, to be able to classify product reviews as positive, negative or neutral. This sample is using data in the following database.
First, we are going to create a table for storing the model and some views for our training/testing datasets.
USE [tpcxbb_1gb]
GO
--**************************************************************
-- STEP 1 Create a table for storing the machine learning model
--**************************************************************
DROP TABLE IF EXISTS [dbo].[models]
GO
CREATE TABLE [dbo].[models](
[language] [varchar](30) NOT NULL,
[model_name] [varchar](30) NOT NULL,
[model] [varbinary](max) NOT NULL,
[create_time] [datetime2](7) NULL DEFAULT (sysdatetime()),
[created_by] [nvarchar](500) NULL DEFAULT (suser_sname()),
PRIMARY KEY CLUSTERED
(
[language],
[model_name]
)
)
GO
-- STEP 2 Look at the dataset we will use in this sample
-- Tag is a label indicating the sentiment of a review. These are actual values we will use to train the model
-- For training purposes, we will use 90% percent of the data.
-- For testing / scoring purposes, we will use 10% percent of the data.
CREATE OR ALTER VIEW product_reviews_training_data
AS
SELECT TOP(CAST( ( SELECT COUNT(*) FROM product_reviews)*.9 AS INT))
CAST(pr_review_content AS NVARCHAR(4000)) AS pr_review_content,
CASE
WHEN pr_review_rating <3 THEN 1
WHEN pr_review_rating =3 THEN 2
ELSE 3
END AS tag
FROM product_reviews;
GO
CREATE OR ALTER VIEW product_reviews_test_data
AS
SELECT TOP(CAST( ( SELECT COUNT(*) FROM product_reviews)*.1 AS INT))
CAST(pr_review_content AS NVARCHAR(4000)) AS pr_review_content,
CASE
WHEN pr_review_rating <3 THEN 1
WHEN pr_review_rating =3 THEN 2
ELSE 3
END AS tag
FROM product_reviews;
GO
Next, we will create a stored procedure that uses Python and the microsoftml rx_logistic_regression to train a model. The problem we are solving is a multiclass classification problem. A good way to quickly figure out which algorithms are used for what type of problems is to use this cheat sheet.
Before training the model, the product review data is featurized using featurize_text. Once the model is trained, it is saved to a table in the database. We will train the model using 90 % of the dataset and use the remaining 10% for test/validation.
-- STEP 3 Create a stored procedure for training a
-- text classifier model for product review sentiment classification (Positive, Negative, Neutral)
-- 1 = Negative, 2 = Neutral, 3 = Positive
CREATE OR ALTER PROCEDURE [dbo].[create_text_classification_model]
AS
BEGIN
DECLARE @model varbinary(max)
, @train_script nvarchar(max);
--The Python script we want to execute
SET @train_script = N'
##Import necessary packages
from microsoftml import rx_logistic_regression,featurize_text, n_gram
import pickle
## Defining the tag column as a categorical type
training_data["tag"] = training_data["tag"].astype("category")
## Create a machine learning model for multiclass text classification.
## We are using a text featurizer function to split the text in features of 2-word chunks
#ngramLength=2: include not only "Word1", "Word2", but also "Word1 Word2"
#weighting="TfIdf": Term frequency & inverse document frequency
model = rx_logistic_regression(formula = "tag ~ features", data = training_data, method = "multiClass", ml_transforms=[
featurize_text(language="English",
cols=dict(features="pr_review_content"),
word_feature_extractor=n_gram(2, weighting="TfIdf"))])
## Serialize the model so that we can store it in a table
modelbin = pickle.dumps(model)';
EXECUTE sp_execute_external_script
@language = N'Python'
, @script = @train_script
, @input_data_1 = N'SELECT * FROM product_reviews_training_data'
, @input_data_1_name = N'training_data'
, @params = N'@modelbin varbinary(max) OUTPUT'
, @modelbin = @model OUTPUT;
--Save model to DB Table
DELETE FROM dbo.models WHERE model_name = 'rx_logistic_regression' and language = 'Python';
INSERT INTO dbo.models (language, model_name, model) VALUES('Python', 'rx_logistic_regression', @model);
END;
GO
-- STEP 4 Execute the stored procedure that creates and saves the machine learning model in a table
EXECUTE [dbo].[create_text_classification_model];
--Take a look at the model object saved in the model table
SELECT * FROM dbo.models;
GO
The last step is to use the model we just trained to test the model using the test dataset.
-- STEP 5 --Stored procedure that uses the model we just created to predict/classify the sentiment of product reviews
CREATE OR ALTER PROCEDURE [dbo].[predict_review_sentiment]
AS
BEGIN
-- text classifier for online review sentiment classification (Positive, Negative, Neutral)
DECLARE
@model_bin varbinary(max)
, @prediction_script nvarchar(max);
-- Select the model binary object from the model table
SET @model_bin = (select model from dbo.models WHERE model_name = 'rx_logistic_regression' and language = 'Python');
--The Python script we want to execute
SET @prediction_script = N'
from microsoftml import rx_predict
from revoscalepy import rx_data_step
import pickle
## The input data from the query in @input_data_1 is populated in test_data
## We are selecting 10% of the entire dataset for testing the model
## Unserialize the model
model = pickle.loads(model_bin)
## Use the rx_logistic_regression model
predictions = rx_predict(model = model, data = test_data, extra_vars_to_write = ["tag", "pr_review_content"], overwrite = True)
## Converting to output data set
result = rx_data_step(predictions)';
EXECUTE sp_execute_external_script
@language = N'Python'
, @script = @prediction_script
, @input_data_1 = N'SELECT * FROM product_reviews_test_data'
, @input_data_1_name = N'test_data'
, @output_data_1_name = N'result'
, @params = N'@model_bin varbinary(max)'
, @model_bin = @model_bin
WITH RESULT SETS (("Review" NVARCHAR(MAX),"Tag" FLOAT, "Predicted_Score_Negative" FLOAT, "Predicted_Score_Neutral" FLOAT, "Predicted_Score_Positive" FLOAT));
END
GO
-- STEP 6 Execute the multi class prediction using the model we trained earlier
EXECUTE [dbo].[predict_review_sentiment]
GO
The result is a predicted score (probability) for each sentiment category. Tag is the actual sentiment of the review. (3=positive, 2=neutral, 1=negative).
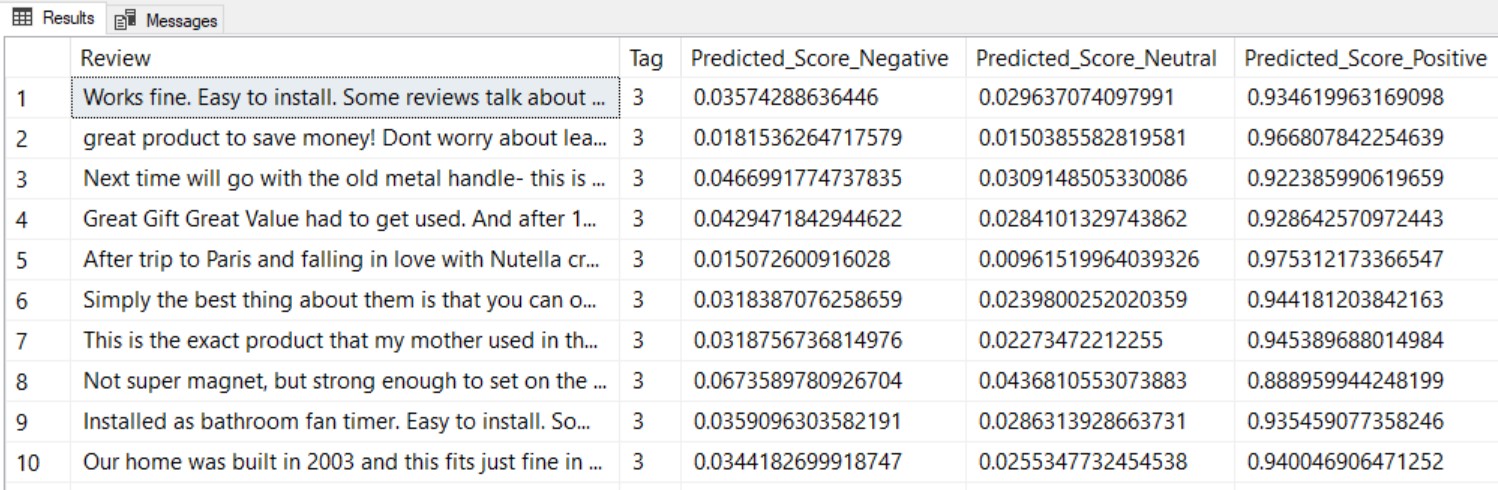
In this way, a company selling products online could get a better understanding of customer satisfaction of specific products based on the review sentiments.
(Note: For the pre-trained model scenario, there is currently an issue with path lengths that we are working on fixing. Make sure that your SQL Server instance is installed under a shorter installation path if you want to use that script, since there is currently a path length limit from Python that can cause issues. A suggestion is to install SQL server in a location like this: C:\SQL\MSSQL14.MSSQLSERVER?)
All scripts are also available on GitHub.
Go to aka.ms/mlsqldev for getting started tutorials with R and Python in SQL Server.
Update 7/19/2018: Many people are hitting an error that refers to "TlcBridge error: Error: *** Exception: ‘resourcePath’". This means that the models are not installed in the correct location. We will be updating the installation instructions on the Docs shortly to make it easier to install these models. In the meantime, once you have installed the models, please make sure that they are saved in the following paths under the Microsoft SQL Server directory of your SQL Server instance:
- "PYTHON_SERVICES\Lib\site-packages\microsoftml\mxLibs" for Python
- "R_SERVICES\library\MicrosoftML\mxLibs\x64" for R
If you notice that the model files (AlexNet_Updated.model, ImageNet1K_mean.xml, pretrained.model, ResNet_101_Updated.model, ResNet_18_Updated.model, ResNet_50_Updated.model) are saved in another location, then try to manually copy the files to the directories specified above. That should solve the resourcePath issue.