SQL Server 2016 - It Just Runs Faster: Always On Availability Groups Turbocharged
When we released Always On Availability Groups in SQL Server 2012 as a new and powerful way to achieve high availability, hardware environments included NUMA machines with low-end multi-core processors and SATA and SAN drives for storage (some SSDs). Performance issues surrounding Availability Groups typically were related to disk I/O or network speeds. As we moved towards SQL Server 2014, the pace of hardware accelerated. Our customers who deployed Availability Groups were now using servers for primary and secondary replicas with 12+ core sockets and flash storage SSD arrays providing microsecond to low millisecond latencies. While we were confident in the design of SQL Server 2012, several customers reported to us performance problems that did not appear to be with disk subsystems, CPU, or networks. The rapid acceleration in technology brought on a new discovery and paradigm. Now disk I/O and CPU capacity were no longer an issue. Our design needed to scale and be adaptable to the modern hardware on the market. We needed to start thinking about how fast can we replicate to a synchronous secondary replica in terms of % of the speed of a standalone workload. (one without a replica).
The result is a design for SQL Server 2016 that provides high availability for the most demanding workloads on the latest hardware with minimal impact and scalable for the future. Our design for SQL Server 2012 and SQL Server 2014 is still proven and meets the demands for many of our customers. However, if you are looking to accelerate your hardware, our Always On Availability Group design for SQL Server 2016 can keep pace.
First, we looked at the overall architecture of the replica design. Prior to SQL Server 2016, it could take as many as 15 worker thread context switches across both the primary and secondary replicas to replicate a log block. On the super speed of a fast network and disk for primary and secondary, we needed to streamline the design. So now the path can be as little as 8 worker thread context switches across both machines provided the hardware can keep pace.
More aspects of this new design include a streamline design with the ability for the LogWriter thread on the primary to directly submit network I/O to the secondary. Our communication workers can stream log blocks in parallel to the secondary and execute on hidden schedulers to avoid any bottlenecks with other read workloads on the primary. On the secondary, we can spin up multiple LogWriter threads on NUMA machines and apply redo operations from the log in parallel. We also streamlined several areas of the code to avoid spinlock contention where it was not needed. We also streamlined and improved our encryption algorithms (including taking advantage of AES-NI hardware) so ensure it could keep us the pace as well.
Our goal become clear. We aspired to achieve 95% of transaction log throughput with a single synchronous secondary as compared to a standalone workload (90% if using encryption). The results we achieved were remarkable.
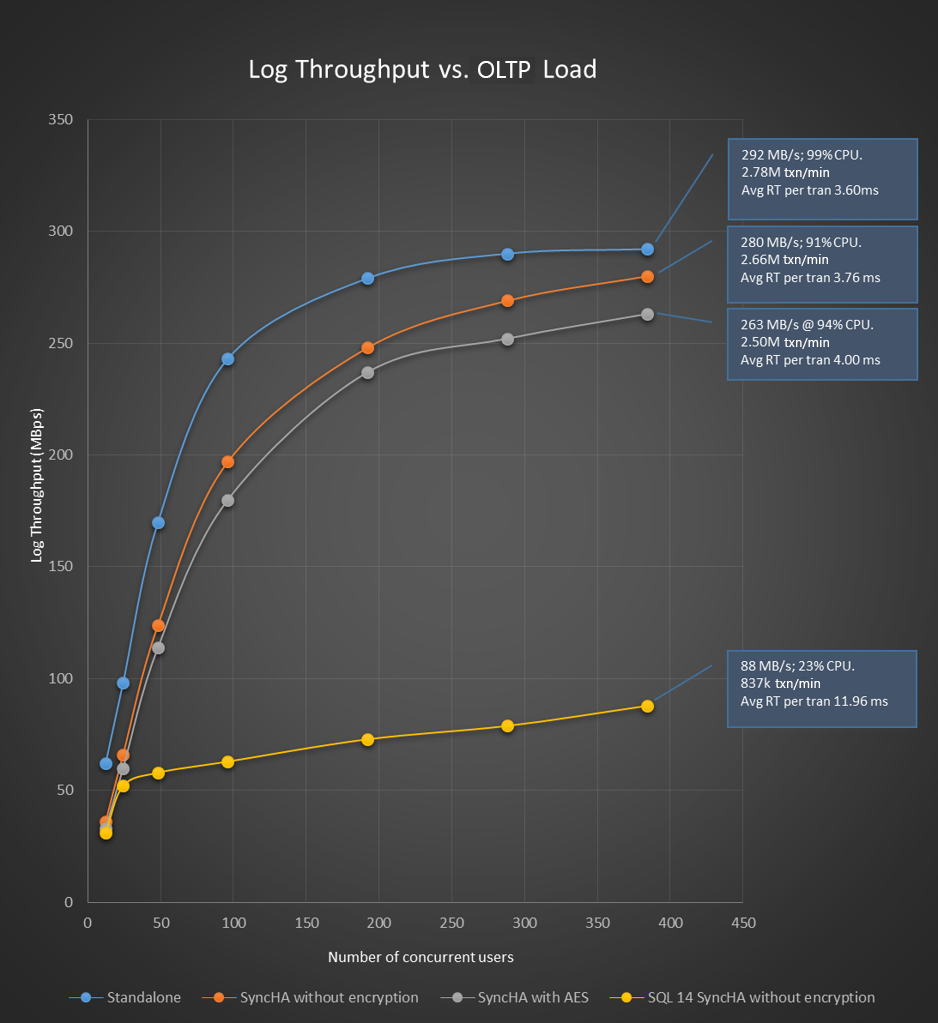
This chart shows our scaled results using a OLTP workload derived from TPC benchmarks. The Blue line represents a standalone OLTP workload. The Y axis represents throughput as measured by the Performance Monitor counter Databases:Log Bytes Flushed/Sec. (if replicating log blocks is slow the overall workload is slow and can’t push log bytes flushed on the primary) .The X axis is the number of concurrent users as we pushed the workload. The yellow line represents throughput results for SQL Server 2014 with a single sync replica. The Red line is for SQL Server 2016 with a single sync replica and the gray line is SQL Server 2016 with encryption. As you can see as we pushed the workload, SQL Server 2014 struggled to keep up with the scaling of a standalone workload but SQL Server 2016 stays right with it achieving our goal of 95%. And our scaling with encryption is right at the 90% line as compared to standalone.
These results are possible for anyone given a scalable hardware solution. Our tests on both primary and secondary machines used Haswell class 2 socket 18 core processors (with hyper threading 72 logical CPUs) with 384Gb of RAM machine. Our transaction log was on a striped 4x800Gb SSD and data on a 4x1.8TB PCI based SSD drive.
Performance is not the only reason to consider an upgrade to SQL Server 2016 for Always On Availability Groups. Consider these enhancements that make it a compelling choice:
- Domain Independent Availability Groups. See more in this blog post.
- Round-robin load balancing in readable secondaries
- Increased number of auto-failover targets
- Support for group-managed service accounts
- Support for Distributed Transactions (DTC)
- Basic HA in Standard edition
- Direct seeding of new database replicas
So amp up your hardware and upgrade to SQL Server 2016 to see Always Availability Groups Turbocharged.
If you are new to SQL Server, get introduced to Always On Availability Groups with this video. Want to dive deeper? Learn more of the details from Kevin Farlee from this video or head right to our documentation at https://aka.ms/alwaysonavailabilitygroups.
Bob Ward
Principal Architect, Data Group, Tiger Team