Columnstore Index: Parallel load into clustered columnstore index from staging table
SQL Server has supported parallel data load into a table using BCP, Bulk Insert and SSIS. The picture below shows a typical configuration of a Data Warehouse where data is loaded from external files either using BCP or SSIS. SQL Server supports parallel data load. 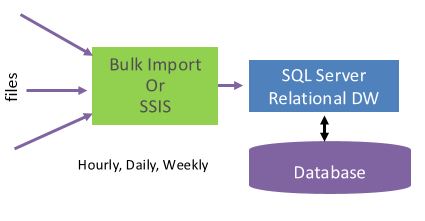
Another common scenario of loading data is via a staging table. Data is first loaded into one or more staging tables where it is cleansed and transformed and then it is moved to the target table as shown below. 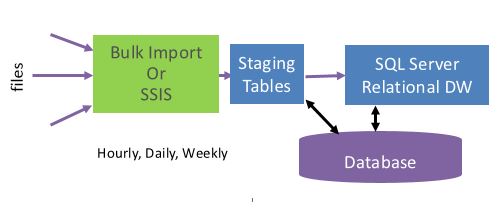
While this works well, one challenge is that though loading data into staging tables can done in parallel, the data load from staging table into target tables is single-threaded which can slowdown the overall ETL process. To give you an extreme example, let us say you are running on a 64-core machine and the last step in your ETL is to move data from staging table to target table. If INSERT is single threaded, you will notice that only one of 64 CPUs are being used. Ideally, you want all 64 cores to be used for faster migration of data to target table. With SQL Server 2016, you can move data from staging table into a target table in parallel which can reduce the overall data load time significantly.
Example: This example shows data migration from a staging table into a target table with CCI both with/without parallel insert
-- create a target table with CCI
select * into ccitest_temp from ccitest where 1=2
go
create clustered columnstore index ccitest_temp_cci on ccitest_temp
-- Move the data from staging table into the target table
-- You will note that it is single threaded
insert into ccitest_temp
select top 4000000 * from ccitest
Here is the query plan. You will note that the 4 million rows are being inserted single threaded into the target table
This data movement took
SQL Server Execution Times:
CPU time = 11735 ms, elapsed time = 11776 ms.
Here is how the rowgroups look. Note, there are 4 compressed rowgroups. These rowgroups are directly compressed as number of rows are > 100k. Only one rowgroup has BULKLOAD as the trim reason as other three compressed rowgroups were not trimmed.

Now, let us the same data migration but with TABLOCK.
-- Now use the TABLOCK to get parallel insert
insert into ccitest_temp with (TABLOCK)
select top 4000000 * from ccitest
Here is the query plan. You will note that the 4 million rows are being inserted single threaded into the target table
This data movement took 7.9 seconds as compared to 11.7 seconds with single-threaded plan. That is almost 35% reduction in the elapsed time.
SQL Server Execution Times: CPU time = 21063 ms, elapsed time = 7940 ms. Here is how the rowgroups look. Note, there are 4 compressed rowgroups each with 1 million rows and the compression was triggered due to BULKLOAD. It is set to BULKLOAD because each of the 4 threads (the machine I am testing on has 4 cores) ran out of rows after accumulating 1000000 rows and did not reach the magic marker of 1048576.

SQL Server 2016 requires following conditions to be met for parallel insert on CCI
- Must specify TABLOCK
- No NCI on the clustered columnstore index
- No identity column
- Database compatibility is set to 130
While these restrictions are enforced in SQL Server 2016 but they represent important scenarios. We are looking into relaxing these in subsequent releases. Another interesting point is that you can also load into 'rowstore HEAP' in parallel as well.
Thanks
Sunil Agarwal