Columnstore Index: How does SQL Server delivers Industry leading performance for Analytic Queries?
Most commercial database vendors now offer some implementation of columnstore technology. The columnstore implementation by each database vendor has its own pros and cons but one key thing to point out is that SQL Server leads the pack for the industry standard benchmark TPCH https://www.tpc.org/tpch/results/tpch_price_perf_results.asp?resulttype=noncluster for Data Warehouses as defined by its the performance metric Composite Query-per-Hour Performance Metric (QphH@Size) and the TPC-H Price/Performance metric expressed as $/QphH@Size in non-clustered configuration. In fact, if you can look at the top 4 numbers in 10TB DW category are all on SQL Server 2014 as shown in the picture below. 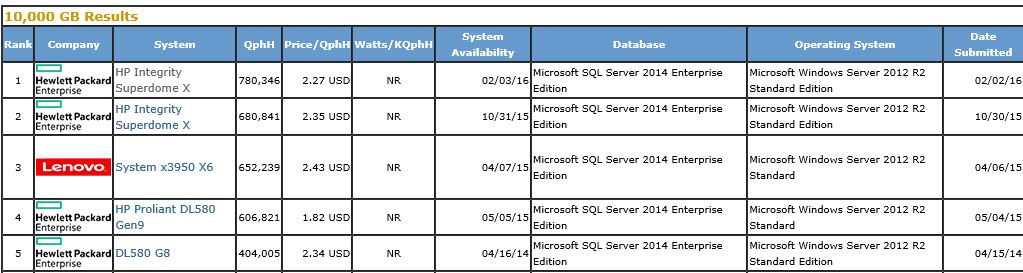
If you look at 3 TB numbers, SQL Server 2016 improves the numbers by 40% over SQL Server 2014 on the same hardware. 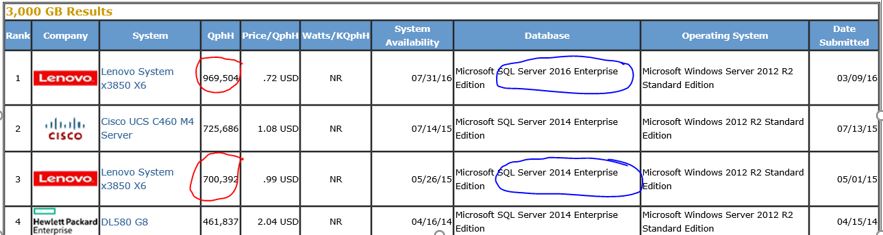
So what is the magic? Well it is a combination of many factors and some those are described below
- High data compression and column elimination to reduce IO significantly when processing large number of rows. Please refer to https://blogs.msdn.microsoft.com/sqlserverstorageengine/2016/03/13/columnstore-index-why-do-we-need-it/
- Batch Mode Processing: An relational operator (e.g. Join, Scan, Aggregate) running in Batch Mode processes multiple rows (i.e. a batch of rows) together typically around 900 rows to speed up analytic queries by an order of magnitude. This is only available when processing rows from columnstore indexes. SQL Server team continues to add batch mode processing for common relational operators for analytics queries as shown in the table below
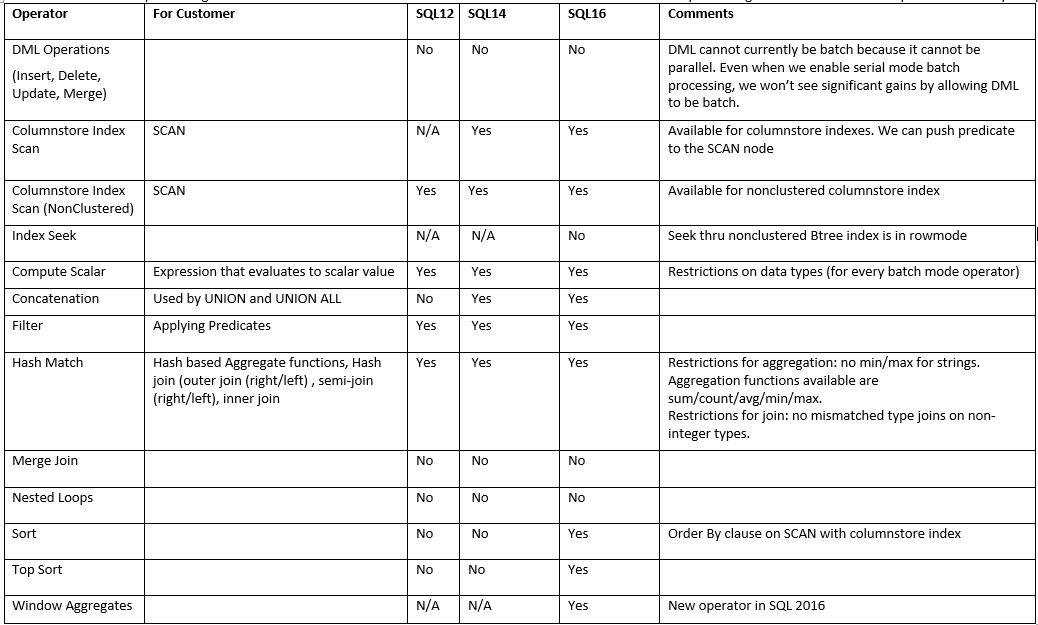
- Applying predicates directly on the compressed data.
- Using regular btree indexes on CCI in SQL Server 2016.
- Rowgroup elimination by leveraging metadata stored with each column within a rowgroup.
- Aggregate Pushdown: SQL Server 2016 computes aggregates at the SCAN node when possible
- String predicate Pushdown: SQL Server 2016 allows pushing of string predicates to the SCAN node. This was not allowed in earlier versions of SQL Server
- Faster processing by leveraging SIMD https://en.wikipedia.org/wiki/SIMD in SQL Server 2016.
Please refer to https://msdn.microsoft.com/en-us/library/gg492088.aspx for details on columnstore index in SQL Server.
Thanks
Sunil