Real-Time Operational Analytics: Filtered nonclustered columnstore index (NCCI)
The previous blog https://blogs.msdn.microsoft.com/sqlserverstorageengine/2016/03/04/real-time-operational-analytics-dml-operations-and-nonclustered-columnstore-index-ncci-in-sql-server-2016/ showed how updateable nonclustered columnstore index (NCCI) processes DML operations (i.e. Insert, Update and Delete) and why NCCI is more expensive to maintain than a traditional rowstore btree index. SQL Server 2016 provides following two options to reduce the impact of NCCI on the transactional workload.
- Filtered nonclustered columnstore index (NCCI)
- Option to delay compression in columnstore index
In this blog, I will focus on filtered nonclustered columnstore index.
Filtered index is not a new option. It was first introduced in SQL Server 2008 and now with SQL Server 2016, it is supported on NCCI. The picture below shows a NCCI with and without filtered predicate.
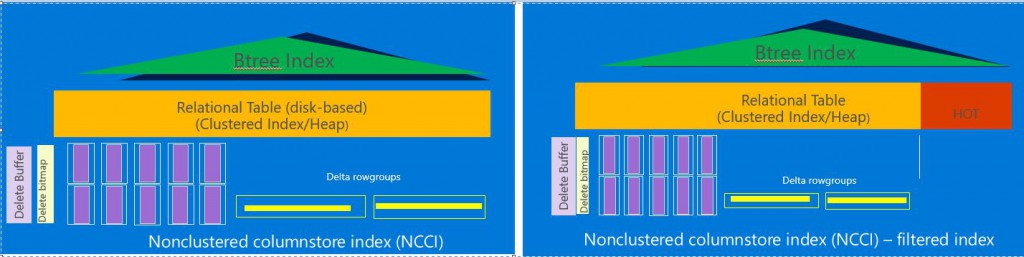
The picture on the left shows an NCCI without filtered predicate and the one on the right shows an NCCI with filtered condition. You will notice portion of disk-based table marked ‘hot’ which represents the data on which there is no NCCI. In other words, any changes made by transactional workloads in ‘hot’ part, there is no overhead of maintaining the NCCI. However, when you run an analytics query that uses NCCI, the SQL Server optimizer will combine the ‘hot’ data automatically requiring no changes to the query. Since there is no NCCI on the ‘hot’ data, the analytics query will be slower but still it will provide real-time analytics. In a nutshell, the filtered NCCI trades off analytics query performance to minimize the impact on transactional workload. You may wonder how SQL Server can identify the ‘hot’ rows (i.e. the ones that don’t qualify with the filtered condition) efficiently without requiring a full table scan? The trick is to have a regular btree clustered index (CI) on the columns used for the filtering condition. You could use a regular NCI to do the same but it will be very inefficient and therefore NOT recommended.
Let us take an example to illustrate these points. The schema and the data load is identical to what I had used in the example in the blog https://blogs.msdn.microsoft.com/sqlserverstorageengine/2016/03/04/real-time-operational-analytics-dml-operations-and-nonclustered-columnstore-index-ncci-in-sql-server-2016/ except for the NCCI which uses a filtered condition ‘orderstatus = 5’. The example is related to Order Processing application where rows are marked ‘cold’ once customer has received the shipment, shown by the condition (orderstatus = 5). Note, there is also a clustered btree index with key column ‘orderstatus’. CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus) where orderstatus = 5
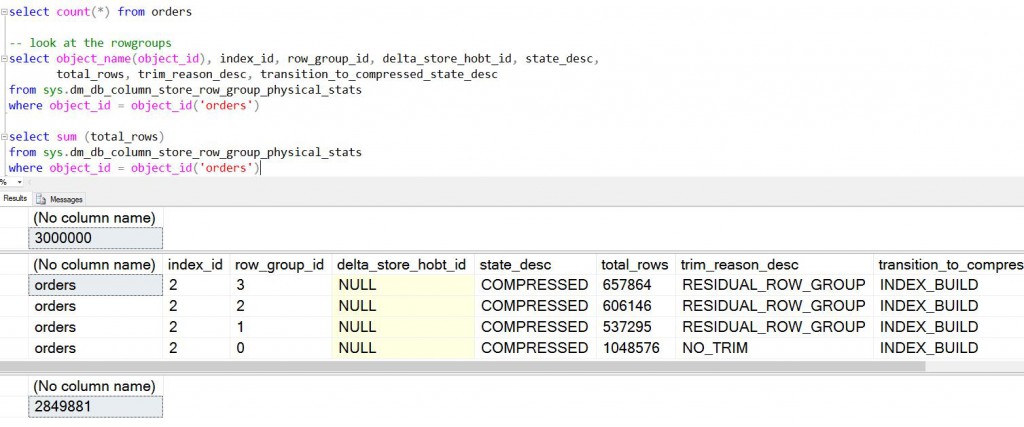
Just like before, I load 3 million rows and create the NCCI. What you see that even though we had inserted 3 million rows, the total rows in NCCI are 2849881. The remaining rows (i.e. the ‘hot’ rows) don’t meet the filtered predicate.
Once the data has been loaded, now let us run one query to show that the generated query plan picks both the rows in NCCI and also the ones that don’t meet the filtered condition automatically using clustered btree index. The numbers of rows flowing thru btree clustered index are (3000000-2849881) = 150119 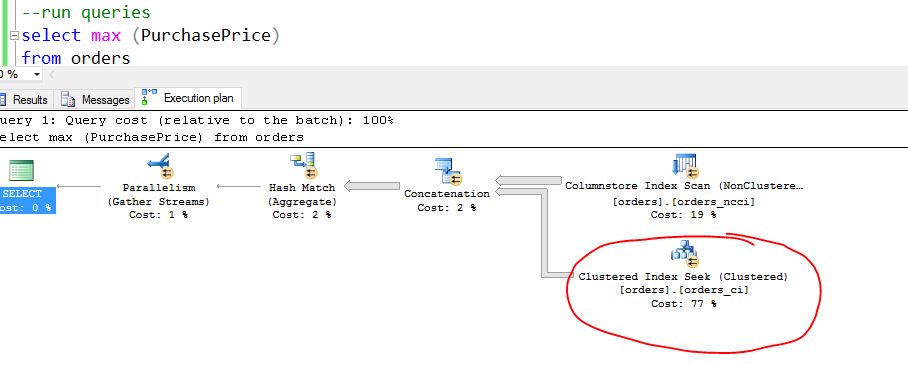
In summary, the filtered NCCI allows you to minimize impact on the transactional workload while still providing you performant analytics queries in real-time. The filtered NCCI works best if the clustered btree index naturally aligns to the filtered predicate condition. If this does not work for your application, then the next choice is to use compression delay option with NCCI. I will describe that in a future blog.
Thanks
Sunil