Indexing data in JSON product catalogs
In the previous post Designing Product Catalogs in SQL Server 2016 using JSON, I have described how you can design product catalog with JSON. Product catalog contains few columns that are common to all types of products and all custom/specific columns are stored as JSON key:value pairs:
This is simple, flexible and generic structure that can contain any product type. The only problem is that we will use full table scan every time we use JSON_VALUE in some predicate.
In this post I will show how you can add indexes on JSON properties in product catalog. In SQL Server 2016, you can use two type of indexes on JSON text:
- Index on computed column that index some specific properties in JSON.
- Full text search index that can index all key:value pairs in JSON objects.
NONCLUSTERED indexes
If you know that you will frequently filter rows in products catalog using some specific path, you can expose value on that path using computed column and create standard NONSLUSTERED index on that column. As an example, imagine that we are filtering rows by ProductNumber property. We can index that property using the following script:
ALTER TABLE ProductCatalog
ADD vProductNumber AS JSON_VALUE(Data, '$.ProductNumber')
CREATE INDEX jidx_ProductNumber
ON ProductCatalog(vProductNumber)
Note that computed column is not PERSISTED. It will be calculated only when a product_number value in JSON column is changed and when index should be updated. However, there is no additional table space in this case. This index will be used if you add filter predicate that uses $.ProductNumber property in JSON_VALUE function:
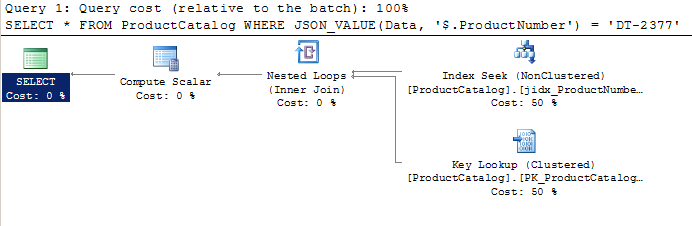
How fast is this solution? Performance are same as performance of indexes on regular columns because the same index is used in both cases.
Note that you can add more than one column in the index, add both computed columns with JSON_VALUE function and standard column in the table, put some columns in INCLUDE section of index to create fully covered indexes, use filtered indexes, etc. This way you are using all benefits of standard SQL Server indexes on JSON values.
Full text indexes
Full text indexes breaks JSON text and enables you to find some words in the text. You can create full text index on JSON column:
-- Assumption is that FT catalog is already created, e.g.:
-- CREATE FULLTEXT CATALOG jsonFullTextCatalog;
-- Create full text index on SalesReason column.
CREATE FULLTEXT INDEX ON ProductCatalog(Data)
KEY INDEX PK_ProductCatalog_ID
ON jsonFullTextCatalog;
Now you can use CONTAINS function that checks does JSON text contains some text value. The interesting feature is NEAR operator that enables you to check are two words near each other:
SELECT ProductID, Name, JSON_VALUE(Data, '$.ProductNumber') AS ProductNumber,
ProductModelID, JSON_VALUE(Data, '$.Color') AS Color
FROM ProductCatalog
WHERE CONTAINS(Data, 'NEAR((Color,Black),1)')
This query will locate all rows where 'Color' and 'Black' are on distance 1 - this is ideal for key:value pairs that are naturally on distance 1.
Note that in some cases this might produce false positive results (i.e. if some other value is 'Color', and the key that is placed after this value is 'Black'). If you believe that this might happen you can add additional predicate JSON_VALUE(Data, '$.Color') = 'Black' that will remove false-positive rows (see example below).
FTS will index all key:value pairs in the document and with NEAR operator we can create complex and flexible queries:
SELECT ProductID, Name
FROM ProductCatalog
WHERE CONTAINS(Data, 'NEAR((Color,Silver),1)
AND NEAR((MakeFlag,true),1)
AND NEAR((SafetyStockLevel,100),1)')
This query will use full text search and seen into table to get the ProductID and Name columns:
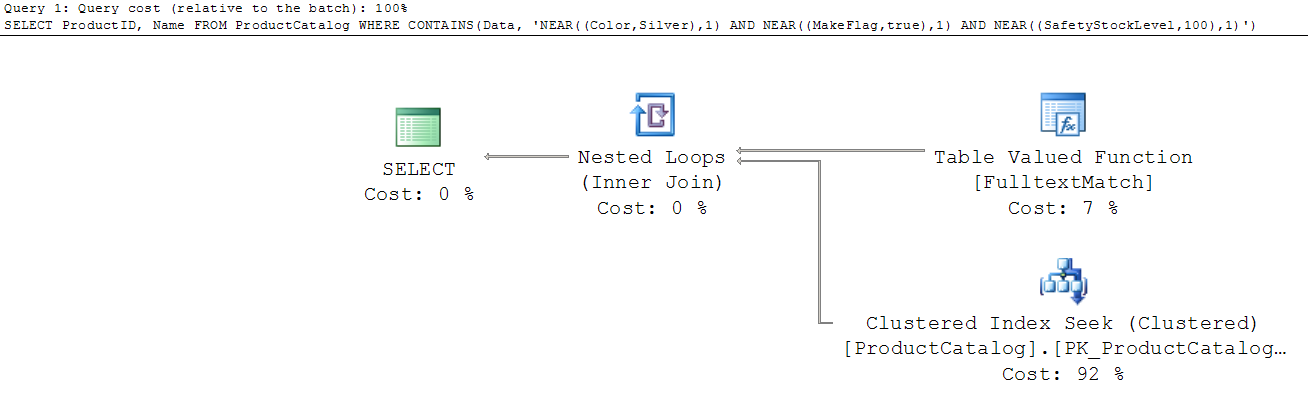
As you might notice, you can use any key:value pair in CONTAINS expression. FTS index will automatically index all key values pairs and enable you to query any of them using NEAR operator.
The only constraint here is the fact that values should be single words because if there is a longer text in the value, FTS will break it into separate words and distance from tokens in the value will be different for every token. However, in simple JSON texts (like the one that is imported from AdventureWorks database) you will be able to index all key values without any problem.
Filtering false positive
Problem with this approach is the fact that FTS is not aware that there is some JSON structure and (thanks to xor88 for pointing out this). Therefore FTS might return some rows that do have words Color and Silver near to each other and it will not be aware that Color might not be a JSON key we want. Therefore, we need to add additional filters to remove false positive results:
SELECT ProductID, Name
FROM ProductCatalog
WHERE CONTAINS(Data, 'NEAR((Color,Silver),1)
AND NEAR((MakeFlag,true),1)
AND NEAR((SafetyStockLevel,100),1)')
AND JSON_VALUE(Data,'$.Color') = 'Silver'
AND JSON_VALUE(Data,'$.MakeFlag') = 'true'
AND JSON_VALUE(Data,'$.SafetyStockLevel') = '100'
In this query FTS/CONTAINS is used to find candidate rows that might satisfy condition we need. In my example it return 16 out of 200.000 rows but some of them might have not have words in the right JSON context. Then the additional filter with JSON_VALUE will check that returned rows actually have these key:value pairs. To summarize:
- CONTAINS will give us high selectivity. Without this part we would end-up with full table scan. However, we cannot be 100% sure that NEAR operators give us correct results with the correct JSON context.
- JSON_VALUE will perform additional check on the smaller set of rows returned by contains/index seek. If FTS returns small number of candidates we will apply these JSON functions on smaller amount of rows. Without this predicate we might have some results that do not satisfy equivalent JSON predicate.
Query plan is shown in following figure:
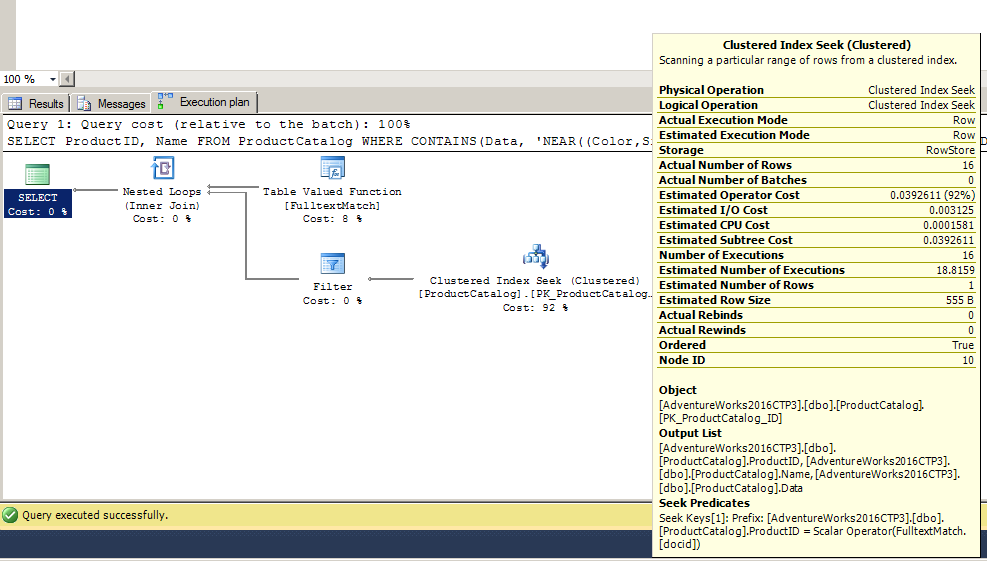
You can notice that full text match will return candidate rows, and index seek will find them in ProductCatalog. You can also notice in the plan that result of full text match is pushed down as index seek predicate. Then Filter operator cleans potential false positive results and we are getting the right results on the output.
This way we can have efficient search by any product field.