Designing Product Catalogs in SQL Server using JSON
Product catalog is a common pattern in retail and e-commerce. The products in retail and e-commerce apps might have various properties/attributes. Depending on the type, some products might have dimensions and weight, others color, taste, price, number of doors, CPU, memory, etc. Attributes for this data may vary and can change over time to fit application requirements.
Designing a table that should store different types of products might be a challenge, and traditionally database designers use the following methods:
- Wide sparse tables where we have one generic Product table that could contain few columns that are common to all product types and a lot of custom columns that are applicable only to some specific types of properties. In this case, you would need put a lot of columns in the product table and make them sparse. The drawback of this method is that you need to alter the schema whenever you add or remove attribute, which might be a challenge if you need to consolidate schema across different databases.
- Table inheritance where there is one generic Product table with common properties, and separate tables that contain attributes for specific product type (for example Toy, Car, etc.). The drawback of this design is the fact that there might be a lot of joins between tables to re-construct one entity.
- Common trade-off is EAV pattern where the properties that are common for all product types are placed in one Product table, and all custom properties are placed in separate three-column ProductAttribute(ProductID, Field, Value) table. This model is flexible in terms of schema changes, but a client needs to send separate queries for main entity and attributes in utility table to reconstruct the whole entity on the client-side.
Retail use case is one of the top cases in NoSQL databases where entire product is stored in one physical unit - document formatted as one JSON object, that has only the properties that available for the particular product type. This design enables a client to read and save product using single request without any additional join. This design is suitable for workloads where product attributes are not frequently changed, and where most of the operations are reading the products by id or inserting new products.
The same design can be used in SQL Database where NoSQL collection is equivalent to two-column table:
CREATE TABLE Products (
id int primary key identity,
attributes nvarchar(max)
)
Attributes can be stored in attributes column in JSON format, and you can either read entire document as single string, or extract attributes using built-in JSON functions that are available in SQL Database. The drawback of this approach (both in NoSQL and SQL/JSON) is that there is still some overhead for extracting attributes from documents, even if you use types or indexes. Nothing can match direct access to relational column in terms of data access performance.
SQL Server and Azure SQL Database enable you to use hybrid approach where you can combine relational and NoSQL concepts in the same table. In SQL database you can model product catalog as a table where common/most important columns are stored as classic relational columns, and variable attributes are stored in JSON document. If properties of some entities might vary, we can combine relational columns with JSON key:values.
We can divide product properties using the following rules:
- Properties that are common for all products will be stored as columns (e.g. title, price, foreign keys)
- Properties that are not common can be stored in single JSON column as key:value pairs.
This way we have one simple table that does not require additional JOIN operators, and still enable us to use properties in JSON as any other column. Example of the Product table created using this approach is shown in the following figure:
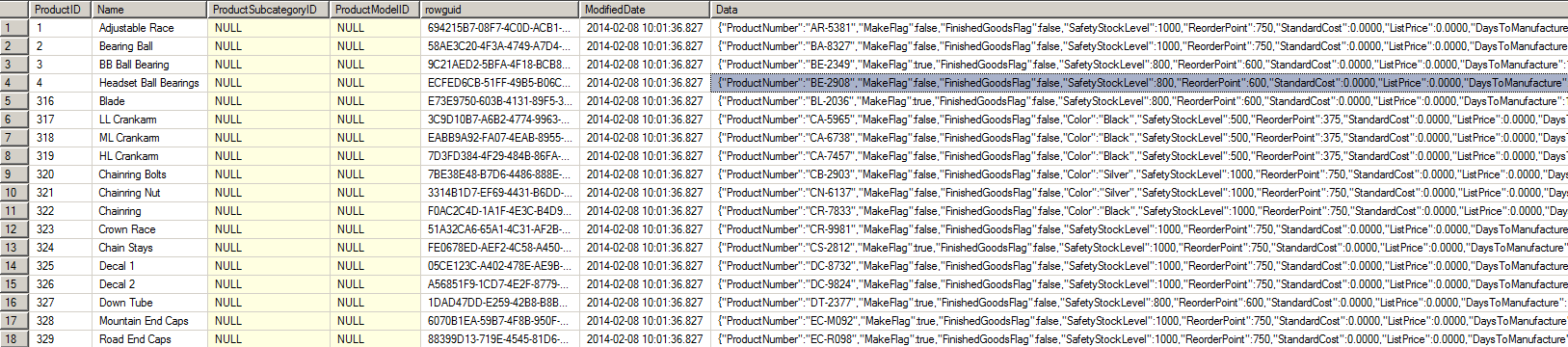
This design provides easy access to product that compares to NoSQL database, and also enables you to optimize data design and expose the most commonly user product attributes as classic table columns.
SQL Database enables you to optimize performance of the queries executed on this hybrid table the same way as you optimize performance of standard relational columns:
- Indexing - you can use the standard NON CLUSTERED and Full Text Search indexes on the properties in JSON column to optimize access. Any index that can be created on classic relational columns can be applied on values in JSON column. You can find more information about indexing techniques in the indexing JSON data post.
- Materialization of JSON fields - you can expose some fields from the JSON column as computed columns. In addition, computed column could be defined as PERSISTED, meaning that it would materialize value from JSON column.
Case study - Adventure Works
In this example, we will see how can we transform Product table in Adventure Works database to hybrid table.
If you look at Production.Product table in AdventureWorks2016 database you will notice that only few columns such as Name, ProductModelID, ModifiedDate, and are generic. Other columns are specific for products in AW domain and if we would like to store new types of product such as self phones, cars, etc., we would need to introduce new columns while most of the existing columns will not be used because they might not be applicable.
Therefore, I will create more generic and simple table ProductCatalog that will contain JSON key value pairs for most of the columns in the Product table that are specific to bicycles:
DROP TABLE IF EXISTS [dbo].[ProductCatalog]
CREATE TABLE [dbo].[ProductCatalog](
[ProductID] [int] IDENTITY(1,1) NOT NULL CONSTRAINT [PK_ProductCatalog_ID] PRIMARY KEY ,
[Name] nvarchar(50) NOT NULL,
[ProductSubcategoryID] [int] NULL,
[ProductModelID] [int] NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
[Data] [nvarchar](max) NULL
)
Now I can move products into this table:
SET IDENTITY_INSERT ProductCatalog ON
INSERT INTO ProductCatalog(ProductID, Name, ProductSubcategoryID, ProductModelID, rowguid, ModifiedDate,Data)
SELECT ProductID, Name, ProductSubcategoryID, ProductModelID, rowguid, ModifiedDate,
(SELECT ProductNumber,MakeFlag,FinishedGoodsFlag,Color,SafetyStockLevel,ReorderPoint,StandardCost,ListPrice,Size,SizeUnitMeasureCode,
WeightUnitMeasureCode,Weight,DaysToManufacture,ProductLine,Class,Style,SellStartDate,SellEndDate,DiscontinuedDate
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER) AS Data
FROM Production.Product
SET IDENTITY_INSERT ProductCatalog OFF
Only columns that are common across all products are retained as table columns. All other columns are formatted as JSON key value pairs and stored in Data column.
Now we can return all additional properties as a whole JSON object or slice results using some properties:
SELECT *, JSON_VALUE(Data, '$.Color') AS Color
FROM ProductCatalog
WHERE JSON_VALUE(Data, '$.ProductNumber') = 'DT-2377'
With JSON in SQL Server 2016 we can easily create flexible key:value structures that could be contain any set of properties. This is common NoSQL pattern that could be easily applied in SQL server.
In the second part of this case study https://blogs.msdn.com/b/sqlserverstorageengine/archive/2015/12/21/indexing-data-in-json-product-catalogs.aspx you might see how to add indexes in this product catalog.