De-normalize database schema using JSON
In this post I will talk about de-normalization - transforming complex relational structures into simpler tables using JSON format.
Problem
In traditional relational schema there can be a lot of one-to-many relationships (e.g. Person may have several phones, or several email addresses). Even for the simple string array in the C#/Java classes in application domain model, we must create separate tables in relational model. As an example, an array of email addresses that belong to person class must be stored in EmailAddress table with a foreign key to the parent Person row because array of strings cannot be mapped to some data type.
In order to read Person data with associated emails and phone numbers; we would need to run several queries (e.g. one to return person info, another to return person phones, third to return person email addresses), or join tables and process one flat result set on the client side. This method requires a lot of JOINs and indexes on foreign keys. The similar problem is with inserts. In order to insert person with his emails and phone numbers, we need to insert person row, take identity value generated for primary key and then use this value to insert records in email address/phone number tables. For each "Logical" insert we need to have several actual table inserts and reads.
NoSQL database use different approach. In NoSQL document database you can store primary entity as JSON together with all related information formatted as JSON arrays. This way you can read person with associated emails and phone numbers with a single read operation, and insert new person with all associated information with a single write. There is some cost for serializing/deserializing child entities as JSON in the application layer; however, there is bigger benefit because we don't have multiple read/write operations for every logical action.
How can we use similar approach in SQL Server?
Solution
In order to avoid complex schema, information from related child entities can be formatted as JSON arrays and stored into parent table. This way we have simpler table schema that matches design in application logic and we need a single table seek/scan to return necessary information.
New FOR JSON clause enables you to denormalize complex relational schema and move information from the child tables in the parent row formatted as JSON.
Data model
In this example will be used Person table structure from AdventureWorks2016CTP3 database. In AdventureWorks2016CTP3 database we have a lot of "one to many" relationships between tables, e.g. one person can have many email addresses, many phones, etc. If you want to store these information in relational database, you would need to use something like a structure on the following figure:
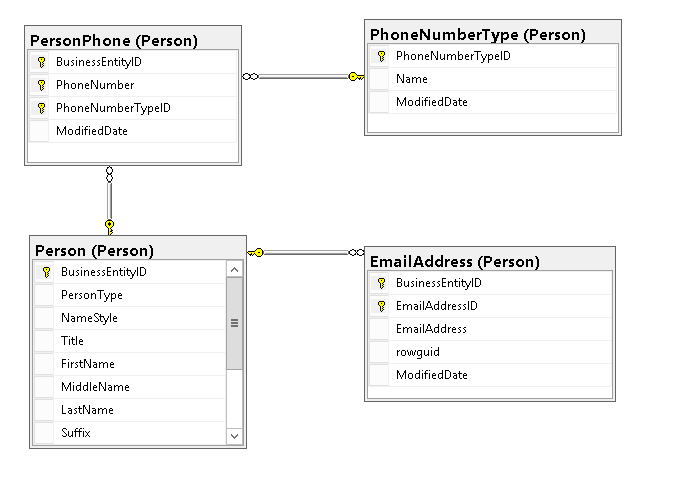
Even for the simple structures such as phone numbers or emails that will be represented as arrays in C# or Java, we need separate tables with foreign key relationships, indexes on foreign keys, etc.
In the another post I have shown how you can return person info with all related information in the single query. Here I will show different approach - pre-aggregating related tables as JSON arrays in parent table. This way we don't need to format related records at the query time - we can just read entire collection from JSON column.
In the following examples will be used Person.Person_json table available in AdventureWorks2016CTP3 database that represents de-normalized version of standard Person.Person table.
Use Case 1: Store phone numbers and their types into single column as JSON array
In this example will be created new text column in Person_json table that will contain array of phone numbers and types:
ALTER TABLE Person.Person_json
ADD PhoneNumbers NVARCHAR(MAX)
CONSTRAINT [Phone numbers must be formatted as JSON array]
CHECK (ISJSON(PhoneNumbers)>0)
Information from PersonPhone and PhoneNumberType tables can be stored in this column using the following query:
UPDATE Person.Person_json
SET PhoneNumbers = (SELECT Person.PersonPhone.PhoneNumber, Person.PhoneNumberType.Name AS PhoneNumberType
FROM Person.PersonPhone
INNER JOIN Person.PhoneNumberType ON Person.PersonPhone.PhoneNumberTypeID = Person.PhoneNumberType.PhoneNumberTypeID
WHERE Person.Person_json.PersonID = Person.PersonPhone.BusinessEntityID
FOR JSON PATH)
In Person_json table will be stored phone number information per each person row. Now we can drop PersonPhone and PhoneNumberType tables since we don't need them anymore.
Use Case 2: Store values of email addreses into single column as JSON array of values
In the second example will be created new text column in Person_json table that will contain array of email addresses:
ALTER TABLE Person.Person_json
ADD EmailAddresses NVARCHAR(MAX)
CONSTRAINT [Email addresses must be formatted as JSON array]
CHECK (ISJSON(EmailAddresses)>0)
Now we can update this column and put all email addresses that belongs to persons formatted as JSON:
UPDATE Person.Person_json
SET EmailAddresses =
dbo.ufnToRawJsonArray(
(SELECT Person.EmailAddress.EmailAddress
FROM Person.EmailAddress
WHERE Person.Person_json.PersonID = Person.EmailAddress.BusinessEntityID
FOR JSON PATH)
, 'EmailAddress')
As a result, in the Email addresses column will be stored emails formatted as JSON arrays:
["ken0@adventure-works.com","ken.adams@adventure-works.com","ken@aw.microsoft.com"]
In this example is used following function that converts array of key:value pairs to array of strings:
-- Utility function that removes keys from JSON
-- Used when we need to remove keys from FOR JSON output,
-- e.g. to generate [1,2,"cell"] format instead of [{"val":1,{"val":2},{"val":"cell"}]
CREATE FUNCTION
dbo.ufnToRawJsonArray(@json nvarchar(max), @key nvarchar(400)) returns nvarchar(max)
as begin
return replace(replace(@json, FORMATMESSAGE('{"%s":', @key),''), '}','')
end
This function simply removes keys from an array so we can get simple arrays of strings.
Conclusion
In this example is shown de-normalization process that helped us to reduce schema with four tables to a single table with two additional JSON columns. De-normalization is common method for simplifying data schema and improving read performance. This is one of the reasons why NoSQL databases become popular.
However, de-normalization is not a silver bullet that will solve all schema complexity and performance problems in your systems. With de-normalization you are getting better read performances but you are increasing table space and your updates will be slower.
Use this approach only if information you want to be de-normalized are not changed frequently (in the example above assumptions is that person will not frequently change his phone numbers and telephone addresses) and when the bottleneck in the system are JOINs and read performance.
Do not de-normalize information that will be frequently changed - separate tables are still the best structures for these kind of data access patterns.