OPENJSON - one of best ways to select rows by list of ids
Selecting table rows by id in SQL Server
In this post I will talk about different way to select rows from the table by list of ids. I will compare performance of some common approaches (IN, LIKE, and OPENJSON).
Problem
Let's talk about simple and common problem - We have a list of identifiers and we want to select all rows from a table that have ids in that list. As an example ,user selected some records in the UI, and we need to fetch these records by ids. How can we do this?
Solutions
You have following options:
1. Use IN where you can pass list of ids:
select BusinessEntityID, FirstName, LastName
from Person.Person
where BusinessEntityID IN (1,2,3)
This is the simplest method but it has few problems:
- You would need to create this query in application layer by concatenating ids or use dynamic SQL
- There is a risk of SQL injection
- Query plans cannot be cached because query text is always different.
2. Use LIKE, e.g:
select BusinessEntityID, FirstName, LastName
from Person.Person
where ','+ @list + ',' LIKE '%,'+cast(BusinessEntityID as nvarchar(20)) + ',%'
In this case @list must be formatted as CSV array e.g. 1,2,3. This is probably the most commonly used anti-pattern that has following problems:
- It is slow
- There is a risk of SQL injection
- Query plans cannot be cached because query text is always different.
However, people are using this approach because they can pass @list as a parameter to stored procedures.
3. Use OPENJSON that will split array of ids into table value function and merge it with source table:
select BusinessEntityID, FirstName, LastName
from Person.Person
join openjson(@list) ON value = BusinessEntityID
Note that @list must be formatted as JSON array e.g. [1,2,3] so you will need to surround your CSV list with brackets.
This is my favorite approach because:
- There is no SQL injection
- I can parametrize @list and use it in stored procedures
- Performance are fine (see below)
Performance comparison
I'm using SQLQueryStress tool provided by Adam Machanic to compare results of these three approaches. In three examples I will create random list of three ids and select some rows using these three methods. I'm running 100 threads in 50 iterations:
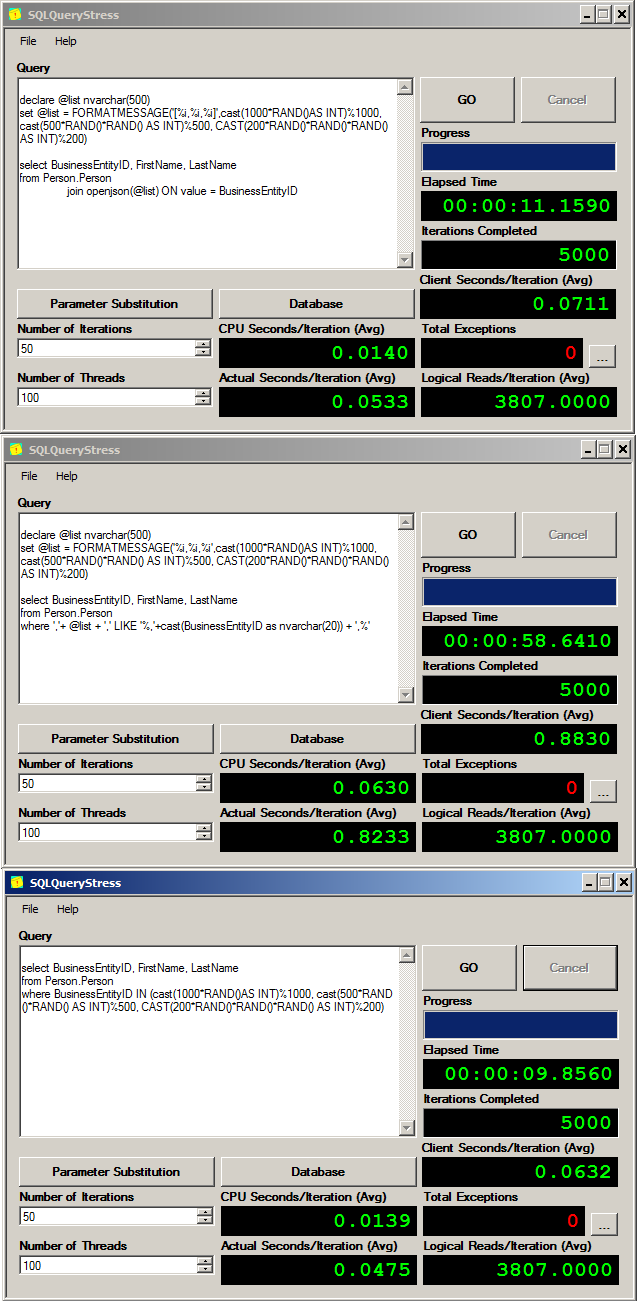
As you can see, LIKE is the slowest way to do this and you should avoid it. Performance of OPENJSON and IN are close 10s compared to 11s (results might vary and in some cases I got very close numbers).
Therefore, you can see that OPENJSON is good approach for this scenario. feel free to repeat this experiment in your databases and compare results.