AlwaysOn: Readable Secondary and data latency
One question that I often get asked is if there will any data latency if you are using 'Sync' replica for read workload. The short answer is yes. Here is the blog that explains it in detail.
While the reporting workload running on the secondary replica gets to access the data as it is changing on the primary but there is some data latency, typically of the order of seconds. If your reporting or read work load cannot tolerate data latency then there is no choice but to run it on the primary replica. Most customers whom I interacted with indicated that their reporting workload can indeed tolerate data latency of the order of minutes. This is good news because as offloading reporting workload to secondary replica allows customers to leverage their investment in High Availability configuration and deliver better performance to both the primary and read workloads.
While this is well and good, but there is some misconception that if you enable readable secondary on a ‘sync’ replica, then there is no data latency. This confusion is rooted in the fact that ‘sync’ replica must send an ACK to primary replica for the ‘commit’ log record. Yes, it is true that ‘sync’ replica guarantees that there is no data loss (i.e. RPO = 0) but it does not guarantee, at least not in SQL-12, that REDO thread running on the secondary replica will apply commit log record before the ACK is sent to the primary. In fact, the REDO thread runs asynchronously to the log hardening logic. So there is indeed some data latency. You may wonder if this data latency is more when you have configured the secondary replica in ‘Async’ mode. This is a little tricky question to answer. If the network between primary/secondary replicas is not able to keep up (i.e. not enough bandwidth) with the transaction log traffic, the ‘Async’ replica can fall further behind leading to higher data latency. In ‘sync’ replica case, the insufficient network bandwidth does not cause higher data latency on the secondary but it can slow down the transaction response time/throughput on the primary.
Another dimension to data latency is when you have configured two or more secondary replicas for read workload. The primary replica sends log records to each of the secondary replicas independently. Within each secondary replica, the log records are applied by REDO thread asynchronously. As you can imagine, this means that each replica is at different point-in-time, though very likely to be close to each other with the result the same query executed on two different readable secondary may return different result. Note, this is not any different than transaction replication with multiple subscribers. Each subscriber will have data at different point-in-time.
The more interesting question here is what happens if you have scaled out your reporting applications across multiple readable secondary? Let us take an example where AlwaysOn is configured with three replicas on node N1, N2, and N3 and you have two reporting applications App1 and App2. The primary replica in on node N1 while the readable secondary are on node N2 and N3. As indicated earlier, the node N2 and N3 can be at different point-in-time. In this configuration, there are two interesting cases as follows
- Case-1: You scale out your reporting workload by running App1 on node N2 and App2 on node N3. In this case, App1 does not see the data on node N3 therefore not impacted by the fact that the data on N3 could be at different point-in-time. Similar case holds for App2 as well. The down side of this configuration is, for example, if App2 cannot offload work to node N3 if it hits temporary spike in the workload.
- Case-2: You scale out both App1 and App2 on node N2 and N3. In other words, each application accesses data both no node N2 and N3 as shown in the figure below for App1. Here all connections for App1 get distributed to node N2 and N3.
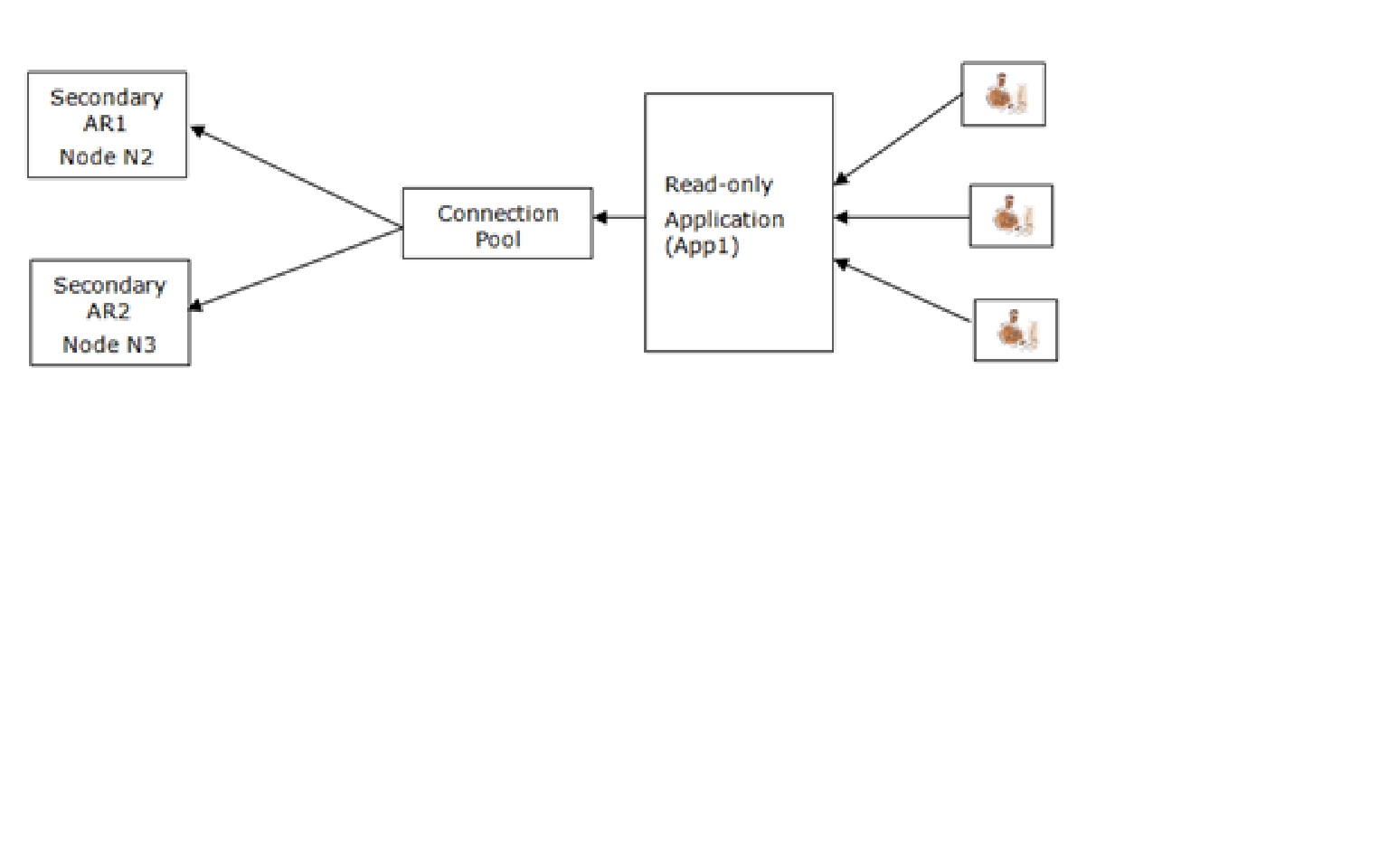 It is good to know that you have both options available to you for scale out your read workload. I look forward to your experience with offloading read workload to the secondary replica and any feedback to improve the product in future. Happy offloading read workload to the secondary replica
It is good to know that you have both options available to you for scale out your read workload. I look forward to your experience with offloading read workload to the secondary replica and any feedback to improve the product in future. Happy offloading read workload to the secondary replica
Thanks
Sunil Agarwal