{kind=link}
Ask Learn
Preview
Ask Learn is an AI assistant that can answer questions, clarify concepts, and define terms using trusted Microsoft documentation.
Please sign in to use Ask Learn.
Sign inThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
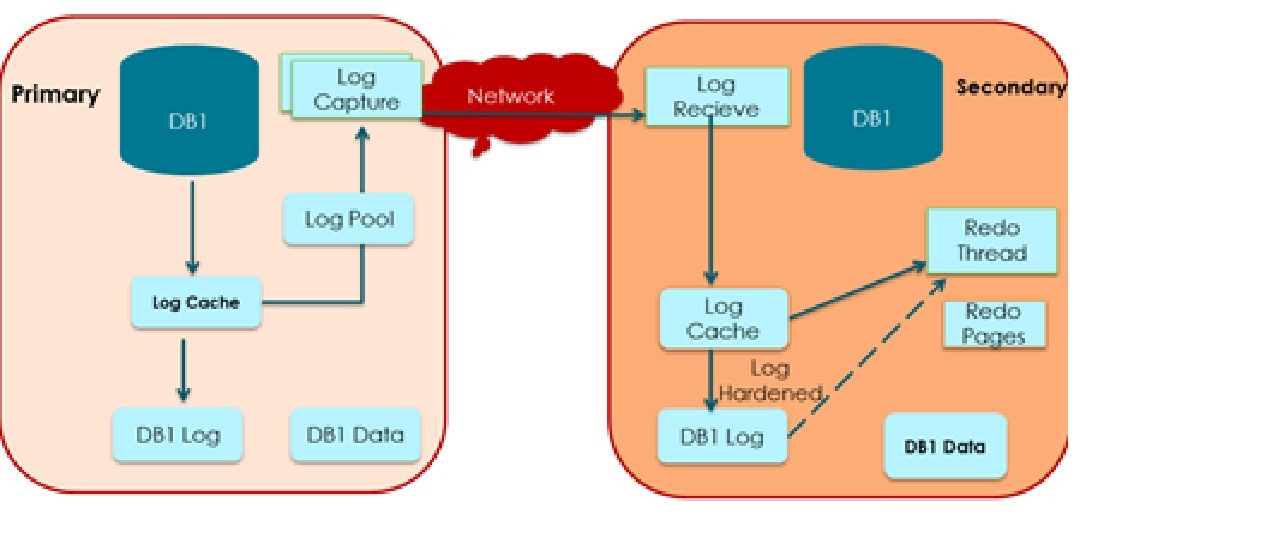
The primary goal of AlwaysOn technology is to provide High Availability for Tier-1 workloads. The ability to leverage secondary replica(s) to offload reporting workloads and database/transaction log backups is useful, but only if it does not compromise High Availability. This is one of the very common concern/question that I have heard from many of you. In this context, let us evaluate the impact of Active Secondary on the primary replica and workload and what you can do to minimize its impact.
o As part of applying log records on the secondary replica, REDO thread reads log records from the log disk and then for each log record, it access the data page(s) to apply the log record. The page access can cause a physical IO if the page is not already in the buffer pool. Now, if read workload is IO bound, it will compete for IO resources with REDO thread thereby slowing it down.
o REDO thread can get blocked by read workload. A blocked REDO cannot apply any log record until it is unblocked which can lead to unbounded impact on the RTO. As described in https://blogs.msdn.com/b/sqlserverstorageengine/archive/2011/12/22/alwayson-minimizing-blocking-of-redo-thread-when-running-reporting-workload-on-secondary-replica.aspx, the design center of readable secondary has eliminated blocking in common scenario and in the event there is blocking, it provides users tell-tale signs both in the dash-board and in the form of XEvent to warn the user of the situation so that a corrective action can be taken
With this, I hope that I have answered most common concerns. I look forward to your questions and suggestions
Thanks
Sunil Agarwal
Anonymous
June 22, 2012
Thank you for this post.
So if I understand this correctly, the main potential bottlenecks in transaction throughput between a primary and a sync replica (excluding the failover scenario) are:
(1) network latency between the primary and the replica;
(2) disk I/O on the sync-replica log drive location (assuming data and log are separated onto distinct spindles).
I will be setting up an environment with a primary, a sync and an async replica sharing the same SAN and being on the same local-area network. I am tempted to allow both the sync and async replicas to be readable, so I can have all 3 nodes being actively used all the time (as opposed to having the sync node sitting as a purely "passive" failover node). I am not sure if that is a good idea for my workload characteristics and what to watch out for, in terms of throughput performance in that scenario.
Any advice would be appreciated.
Anonymous
June 24, 2012
Given your configuration, you should be fine allowing read on both sync and async replica.
thanks
Sunil
Anonymous
November 18, 2014
REDO thread will get blocked only in Synchronous mode ?
Anonymous
September 10, 2015
The comment has been removed
Ask Learn is an AI assistant that can answer questions, clarify concepts, and define terms using trusted Microsoft documentation.
Please sign in to use Ask Learn.
Sign in