Minimal Logging changes in SQL Server 2008 (part-3)
So far we had discussed (https://blogs.msdn.com/sqlserverstorageengine/archive/2008/03/23/minimal-logging-changes-in-sql-server-2008-part-2.aspx ) how minimal logging changes impact when you are moving data from one table to another table. Now let us look at how does this change more conventional bulk import. As you will see, conventional bulk import takes advantage on these changes as well but these changes are only useful when importing into a btree as conventional bulk import already provides minimal logging for heaps. Here are the series of scenarios that I tried
(1) Inserting into an HEAP. No changes in this behavior
begin tran
-- this is optimized load
-- (1) show that individual rows are not logged
-- (2) show the BU lock
bulk insert t_heap
from 'C:\sql-server-test\minimal-logging\t_source-dat.dat'
with (TABLOCK)
Logging:: Minimal Logging
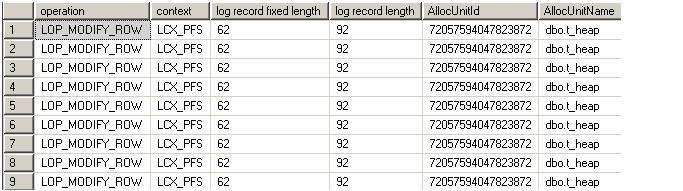
-- if we don't specify TABLOCK, it leads to full logging. This is same what we always had
-- (1) without TABLOCK, no minmal logging.
bulk insert t_heap
from 'C:\sql-server-test\minimal-logging\t_source-dat.dat'
LOGGING: Fully logged
(2) Insert into BTREE
a) Into empty BTREE
create table t_ci (c1 int, c2 int, c3 char(100), c4 char(1000))
go
create clustered index ci on t_ci(c1)
go
begin tran
-- this is optimized load
-- (1) show that individual rows are not logged
-- (2) Lock: X lock on the table
bulk insert t_ci
from 'C:\sql-server-test\minimal-logging\t_source-dat.dat'
with (TABLOCK, datafiletype = 'char')

-- Now, what if don't specify TABLOCK? This is a change from earlier versions. and this is also optimized load. You will need to use TF-610
-- this functionality
-- (1) we get minimal logging
-- (2) IX: at table level
-- (3) you can use this to do parallel load as long as you are
-- (4) importing into disjoint ranges
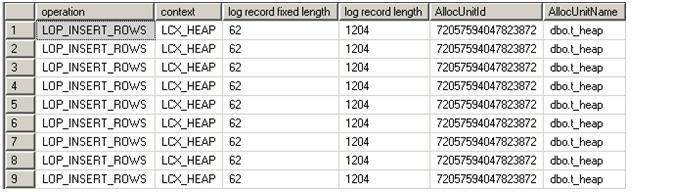
bulk insert t_ci
from 'C:\sql-server-test\minimal-logging\t_source-dat.dat'
with (datafiletype = 'char')
Here are the top 10 log records. Note, in this case, only the range lock is taken
b) Into non-empty btree (when inserting into an increasing range)
-- Inserting rows with disjoint range, we still get minimal logging
-- if you are inserting into a btree but the range you are inserting overlaps partially with the existing data,
-- the logging will go between minimal and full logging. The rule is that you will get minimal logging
-- only when you allocate a new page.
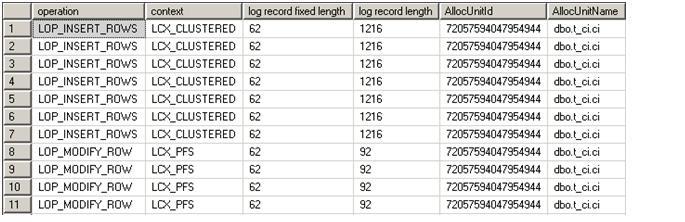
bulk insert t_ci
from 'C:\sql-server-test\minimal-logging\t_newrange-dat.dat'
with (datafiletype = 'char')
Here are the top 10 log records. Note, in this case, only the range lock is taken. Since the SQL Server does not take X lock on the table, you can do parallel bulk import with minimal logging into a btree.
![]()
c) Into a table with clustered and non-clustered indexes
create table t_ci_nci (c1 int, c2 int, c3 char(100), c4 char(1000))
go
create clustered index ci on t_ci_nci(c1)
go
create index nci on t_ci_nci(c2, c3)
go
begin tran
-- this is optimized load
-- (1) show that individual rows are not logged
-- (2) Lock: IX lock on the table
bulk insert t_ci_nci
from 'C:\sql-server-test\minimal-logging\t_source-dat.dat'
with (datafiletype = 'char')
Query Plan:: Notice NCI and CI data is being sorted

Logged Records:: For the clustered index
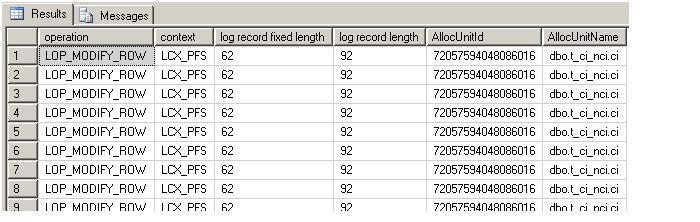
Logged Records:: For the non-clustered index. Note, that index key is atleast > 100 bytes, so clearly it is minimally logged

As you can see, with the minimal logging changes in SQL2008, you have lot more options to bulk import the data with minimal logging. These changes are available on SQL2008/RTM.
Thanks
Sunil