Minimal Logging changes in SQL Server 2008 (part-2)
In the previous example https://blogs.msdn.com/sqlserverstorageengine/archive/2008/03/06/minimal-logging-changes-in-sql-server-2008-part-1.aspx, I described minimal logging while moving data from a source table into a heap. You may recall that it requires a X table lock to get minimal logging. Now, I will show you what happens when you move data from a source table into a btree. In order to get minimal logging with btree, the only requirements are
- Like minimal logging for heap, the database must be set to bulk-logged or simple recovery model
- The input data must be sorted in the index key order. Note, it does not require X tablelock or the btree to be empty. SQL Server accomplishes this by acquiring a X range lock. So for example, if you have a btree with values 1, 100, 1001, 100 and now you want to insert 500 rows with the key range from 110 thru 610, the SQL Server does that by acquiring a X range lock between 100 and 1001 and accomplishes the load. The other transactions can access any data that is outside the range (100, 1001)
- Enable TF-610
Here is one example:
Insert into empty BTREE without TABLOCK is minimally logged except for the rows inserted on the first page.
-- create the source table
create table t_source (c1 int, c2 int, c3 char (100), c4 char(1000))
go
declare @i int
select @i = 1
while (@i < 10000)
begin
insert into t_source values (@i, @i+10000, 'indexkey', 'hello')
select @i= @i + 1
end
-- create a table with clustered index
create table t_ci (c1 int, c2 int, c3 char(100), c4 char(1000))
go
create clustered index ci on t_ci(c1)
go
go
-- minimally logged except for the first page worth of rows
-- Order BY is not necessary. You will only get minimal logging if
-- Optimizer chose to sort the rows before inserting.
-- LOCK: IX at table level
insert into t_ci select * from t_source order by c1
go
Here is the query plan. Please note that SQL Server chose a SORT operator
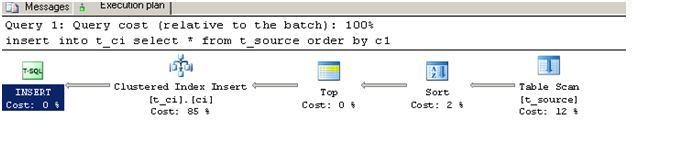
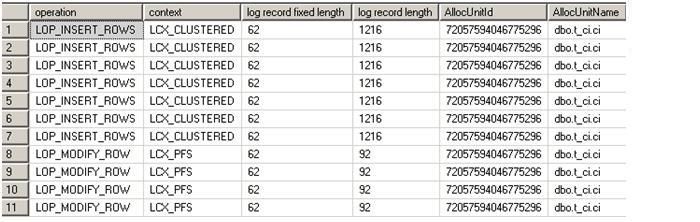
Here are logged records. You will notice, that first 7 are fully logged but after that it is minimally logged. When inserting rows into the btree, the page where the first row is to be inserted may have some rows so for this reason each insert is fully logged. Only once it is done with this page, a new page needs to be allocated, it is minimally logged
When I insert data into new range into a non-empty btree from the previous example, I get minimal logging except for the last page. Again, this works with/without TABLOCK
-- create a table with an non-overlapping range
create table t_newrange (c1 int, c2 int, c3 char(100), c4 char(1000))
go
declare @i int
select @i = 10001
while (@i < 20000)
begin
insert into t_newrange values (@i, @i+10000, 'indexkey', 'hello')
select @i= @i + 1
end
-- minimally logged except for the rows inserted on to the last page.
-- Note, this inserting the data in a new data range.
-- LOCK: X lock on the table.
-- Same logging behavior with/without TABLOCK
insert into t_ci with (TABLOCK) select * from t_newrange order by c1
go
Here are the log records. You will notice that the first 2 inserts are fully logged. Again, there are fully logged because the two rows go to the existing page and from that point onwards, the rows go to new page and hence minimally logged
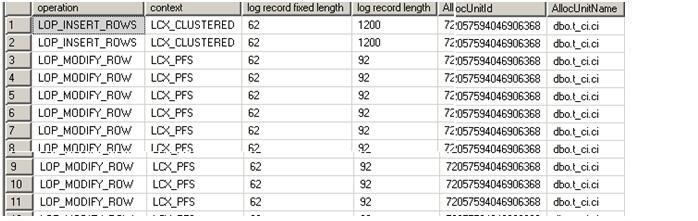
In fact, I can load data into this btree concurrently as follows
-- create a table with clustered index
create table t_ci (c1 int, c2 int, c3 char(100), c4 char(1000))
go
create clustered index ci on t_ci(c1)
go
Now execute the following in two different sessions
-- connection 1
insert into t_ci select * from t_source order by c1
go
-- connection 2
insert into t_ci select * from t_newrange order by c1
go
Both of these inserts are minimally logged and they will insert the data in concurrently.
Thanks
Sunil