Bulk Import Optimizations (Minimal Logging)
In the previous blog I had listed all bulk import optimizations. Now, I will describe each of these optimizations in detail in separate blog entries. Let me first start with minimal logging. By the way minimal logging is also called bulk-logging but the correct term is 'minimal logging'. Bulk logging refers more to the database recovery model that enables minimal logging. Note, that the minimal logging can also be enabled by SIMPLE recovery model as well. This BLOG decribes the behavior for minimal logging as it exists in SQL Server 2005.
Under minimal logging, the SQL Server does not log individual rows and logs only the page and extent allocations. So if each page can fit 100 rows, we are trading 100 log records for 1 log record, a significant improvement. It is useful here to step back and examine how SQL Server does ensures ACID properties even when individual rows are not logged or how does the log backup work.
When the bulk import transaction commits (i.e. the number of rows as specified in the batchsize), the SQL Server flushes all the data pages (a subset of these pages are likely to have been flushed as part of checkpoint) to disk to guarantee the atomocity of the transaction. This is not any more expensive than flushing the log records as the log records would contain the full image of all the rows. And if for some reason, the bulk import transaction needs to be rolled back, all SQL Server needs to do is to traverse the log records and mark the pages/extents to be free again. When the transaction log backup is taken, the SQL Server also backs up the data pages, including index pages when applicable, as part of the transaction log. This enables a database restore by restoring the database backup followed by zero or more transaction log backups. The only drawback of minimal logging is that it does not support point-in-time recovery. This is because during the transaction log backup, the state of the pages involved in the bulk import may have changed between the time bulk import was done and the transaction log back is initiated. One can argue that we could possibly do point-in-time recovery to just before the bulk import had started but it is not supported. If this is of concern, you can do transaction log backup before/after bulk operations. Please refer to BOL for details of point-in-time recovery and associated restrictions.
So far we discussed minimal logging at a conceptual level. Now let us consider a simple example where we will insert 5 rows into a table both with minimal logging and without it and examine the difference.
The table t_heap below has a row length of > 1000 bytes so the log record representing the an insert of the data row will also be > 1000 bytes so it will be easy to spot when we examie the log records
create table t_heap (c1 int, c2 int, c3 decimal (38,2), c4 char(1000))
Let us execute the following command to insert 5 rows through optimized Bulk Import
bulk insert t_heap
from 'C:\t_heap-c-small.dat' with (TABLOCK)
Now we can look at the top 5 log records by executing the following query
select 5 operation,context,[log record length]
from fn_dblog(null, null)
where allocunitname='dbo.t_heap'
order by [Log Record Length] Desc
Here are the top 5 log records returned. You will notice that all records are < 100 bytes. In other words, the individual row inserts were not logged. The log records below refer to PFS, an allocation meta-information related page that tracks free space in the allocated page.
Operation context [log record length]
--------- ------- -------------------
LOP_MODIFY_ROW LCX_PFS 92
LOP_MODIFY_ROW LCX_PFS 92
LOP_MODIFY_ROW LCX_PFS 92
LOP_MODIFY_ROW LCX_PFS 92
LOP_MODIFY_ROW LCX_PFS 92
Now let us take a look at the log records when we insert 5 rows through the normal insert code path as follows
declare @i int
select @i = 0
while (@i < 5)
begin
insert into t_heap values
(@i, @i + 5000, 10.2, replicate ('a', 60))
set @i = @i + 1
end
And here are the top 5 log records and you can see that in this case, each inserted row is fully logged.
operation context [log record length]
--------- ------- -------------------
LOP_INSERT_ROWS LCX_HEAP 1116
LOP_INSERT_ROWS LCX_HEAP 1116
LOP_INSERT_ROWS LCX_HEAP 1116
LOP_INSERT_ROWS LCX_HEAP 1116
LOP_INSERT_ROWS LCX_HEAP 1116
You can use fn_dblog() as a handy way to see if you are getting minimal logging or not.
Till now, we have discussed what does the minimal logging mean and how you can checks if you indeed are getting the minimal logging but we have not looked at the conditions that need to be met for minimal logging. The conditions for minimal logging are
· The database recovery model must be set to BULK_LOGGED or SIMPLE. Under FULL recovery model, as the name implies, all operations are fully logged.
· The target table should not have been marked for replication
· If database backup command is being run concurrently, the minimal logging is temporarily disabled but it does not stop bulk import. So you may see that part of bulk import is fully logged.
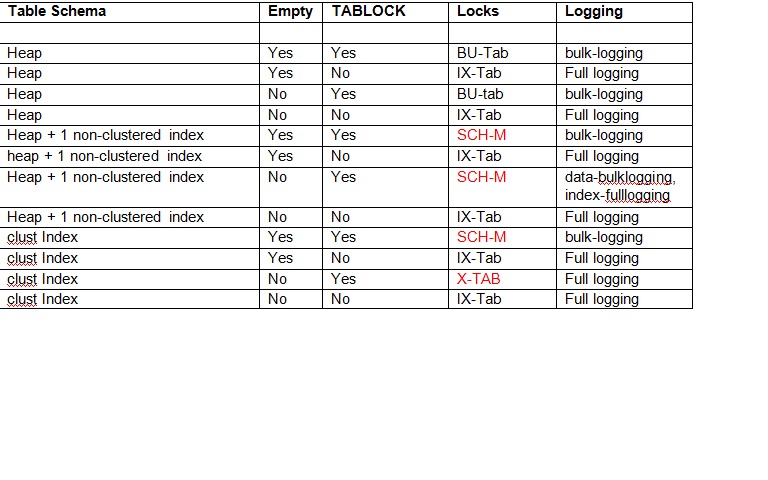
· Minimal logging depends on the indexes defined on the table and whether the table/index is empty or not as described in the table below. You will notice that TABLOCK is required to enable minimal logging.