Row-Level Security: Performance and common patterns
This post demonstrates three common patterns for implementing Row-Level Security (RLS) predicates:
- Rows assigned directly to users
- Row assignments in a lookup table
- Row assignments from a JOIN
In addition, this post shows how RLS has performance comparable to what you’d get with view-based workarounds for row-level filtering. The benefits of using RLS instead of views include:
- RLS reduces code complexity by centralizing access logic in a security policy and eliminating the need for an extra view on top of every base table
- RLS avoids common runtime errors by requiring schemabinding and performing all permission checks when the policy is created, rather than when users query
- RLS simplifies application maintenance by allowing users and applications to query base tables directly
To demonstrate the three common patterns, we’ll use RLS to filter rows in a Sales table based on increasingly complex criteria. To enable reasonable performance comparisons, we've populated this table with 50,000 rows of random data.
Full demo script: https://rlssamples.codeplex.com/SourceControl/latest#RLS-Performance-Common-Patterns.sql
Pattern 1: Rows assigned directly to users

The simplest way to use RLS is to assign each row directly to a user ID. A security policy can then ensure that rows can only be accessed by the assigned user. As described in Building More Secure Middle-Tier Applications with Azure SQL Database using Row-Level Security, it is common to use CONTEXT_INFO to store the user ID connecting to the database, and use RLS to filter out rows whose assigned user ID does not match.
In this example, we create a security policy that filters our rows whose SalesRepId does not match CONTEXT_INFO (using the appropriate type conversions):
CREATE FUNCTION rls.staffAccessPredicateA(@SalesRepId int)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN SELECT 1 AS accessResult
WHERE CONVERT(int, CONVERT(varbinary(4), CONTEXT_INFO())) = @SalesRepId -- @SalesRepId (int) is 4 bytes
go
CREATE SECURITY POLICY rls.staffPolicyA
ADD FILTER PREDICATE rls.staffAccessPredicateA(SalesRepId) ON dbo.Sales
go
We could have achieved equivalent functionality using a view:
CREATE VIEW vw_SalesA
AS
SELECT * FROM Sales
WHERE CONVERT(int, CONVERT(varbinary(4), CONTEXT_INFO())) = SalesRepId
go
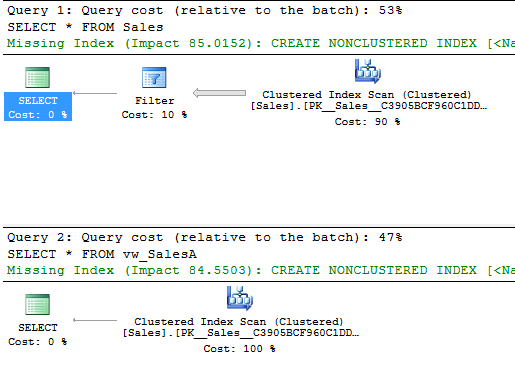
Now SELECT * FROM Sales with RLS enabled returns the same results as SELECT * FROM vw_SalesA without RLS enabled. Moreover, if we examine the Actual Execution Plans for both queries using SSMS, we see that the query optimizer has chosen a very similar plan for both. Sometimes the RLS plan will be slightly better, other times it will be slightly worse. The specific plan can depend on a multitude of exogenous factors, but in general the plans for RLS and for views will be very similar. (Note: We’ll ignore the missing index recommendations here, since these queries are artificially simple and the recommendations would have us place an index on every column.)
Pattern 2: Row assignments in a lookup table

A slightly more complex way to use RLS is to filter rows by looking up assignments in a helper table. For instance, we might have a helper table (“RegionAssignments”) mapping users to Regions. In our filtering logic, we can look up whether the current user should have access to each row based on the assignments stored in RegionAssignments. If one or more rows in RegionAssignments match the criteria, the corresponding row in the base table will be visible:
CREATE FUNCTION rls.staffAccessPredicateB(@Region nvarchar(50))
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN SELECT 1 AS accessResult FROM dbo.RegionAssignments
WHERE CONVERT(int, CONVERT(varbinary(4), CONTEXT_INFO())) = SalesRepId
AND Region = @Region
go
CREATE SECURITY POLICY rls.staffPolicyB
ADD FILTER PREDICATE rls.staffAccessPredicateB(Region) ON dbo.Sales
go
Or equivalently, with a view:
CREATE VIEW vw_SalesB
AS
SELECT Sales.* FROM Sales, RegionAssignments
WHERE CONVERT(int, CONVERT(varbinary(4), CONTEXT_INFO())) = RegionAssignments.SalesRepId
AND Sales.Region = RegionAssignments.Region
go
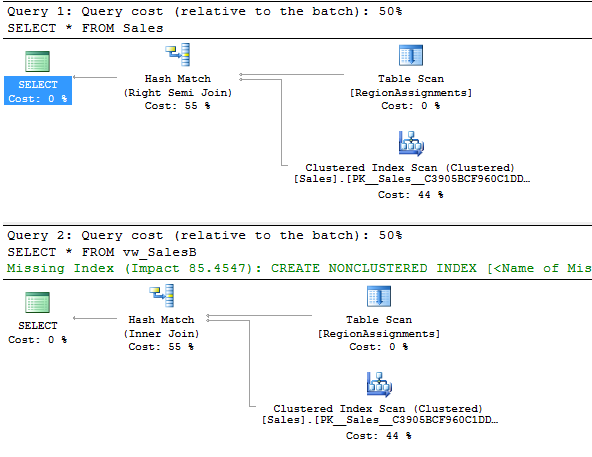
Again, selecting from Sales with RLS enabled yields the same rowset as selecting from vw_SalesB without RLS enabled. In this particular case, the query plans are identical:
Pattern 3: Row assignments from a JOIN

A more complicated RLS pattern is to look up row assignments by joining multiple helper tables in the filtering logic. For instance, we might have one helper table (“RegionAssignments”) mapping users to Regions, and another (“DateAssignments”) mapping users to a StartDate and an EndDate. To filter so that users can only see rows in their assigned region and date interval, we could create the following predicate function and policy:
CREATE FUNCTION rls.staffAccessPredicateC(@Region nvarchar(50), @Date date)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN SELECT 1 AS accessResult FROM dbo.RegionAssignments ra
INNER JOIN dbo.DateAssignments da ON ra.SalesRepId = da.SalesRepId
WHERE CONVERT(int, CONVERT(varbinary(4), CONTEXT_INFO())) = ra.SalesRepId
AND @Region = ra.Region
AND @Date >= da.StartDate
AND @Date <= da.EndDate
go
CREATE SECURITY POLICY rls.staffPolicyC
ADD FILTER PREDICATE rls.staffAccessPredicateC(Region, Date) ON dbo.Sales
go
Or equivalently, with a view:
CREATE VIEW vw_SalesC
AS
SELECT Sales.* FROM Sales, RegionAssignments
INNER JOIN DateAssignments on RegionAssignments.SalesRepId = DateAssignments.SalesRepId
WHERE CONVERT(int, CONVERT(varbinary(4), CONTEXT_INFO())) = RegionAssignments.SalesRepId
AND Sales.Region = RegionAssignments.Region
AND Sales.Date >= DateAssignments.StartDate
AND Sales.Date <= DateAssignments.EndDate
go
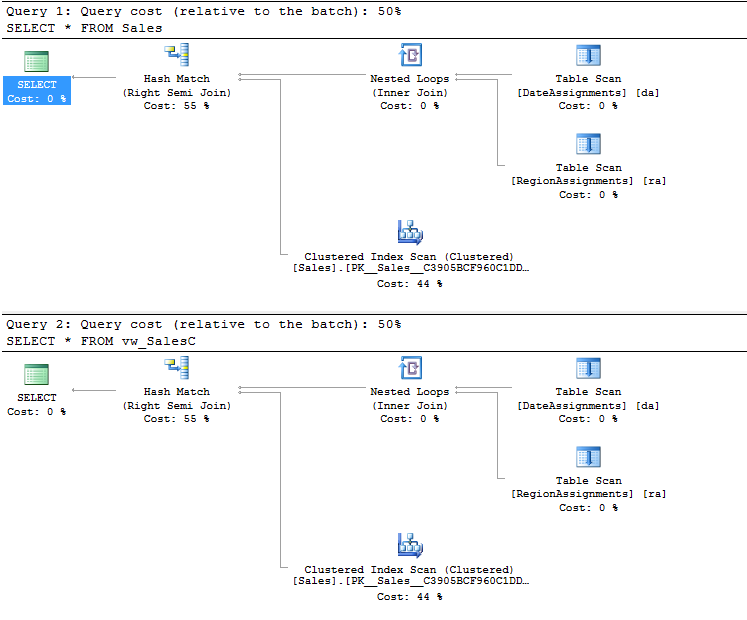
Once again, selecting from the base table with RLS enabled yields the same rowset as selecting from the view without RLS enabled. And once again, in this case the query plans are identical:
Summary
RLS allows you to implement filtering logic of arbitrary complexity; however, there are a handful of particularly common patterns as shown in this post. In general, RLS will have performance comparable to what you’d get if using views, while affording a number of benefits around security, maintenance, and convenience.
We’ll have more guidance around performance in future blog posts, but for now we recommend the following best practices:
- Avoid joining too many helper tables in your predicate function: the more joins you have, the worse the performance.
- If your predicate does a lookup in a helper table, try to put an index on the lookup column.
- Avoid using disjunctions (logical OR) in your predicate where possible, as there is a known performance issue described in Row-Level Security for Middle-Tier Apps – Using Disjunctions in the Predicate.