SQL Server 2016 Service Pack 1 (SP1) released !!!
With cloud first strategy, the SQL Product Team has observed great success and adoption of SQL Server 2016 compared to any previous releases. Today, we are even more excited and pleased to announce the availability of SQL Server 2016 Service Pack 1 (SP1) . With SQL Server 2016 SP1, we are making key improvements allowing a consistent programmability surface area for developers and organizations across SQL Server editions. This will enable you to build advanced applications that scale across editions and cloud as you grow. Developers and application partners can now build to a single programming surface when creating or upgrading intelligent applications, and use the edition which scales to the application's needs.
In addition to a consistent programmability experience across all editions, SQL Server 2016 SP1 also introduces all the supportability and diagnostics improvements first introduced in SQL 2014 SP2, as well as new improvements and fixes centered around performance, supportability, programmability and diagnostics based on the learnings and feedback from customers and SQL community.
SQL Server 2016 SP1 also includes all the fixes up to SQL Server 2016 RTM CU3 including Security Update MS16–136.
Following is the detailed list of improvements introduced in SQL Server 2016 SP1
The following table compares the list of features which were only available in Enterprise edition which are now enabled in Standard, Web, Express, and LocalDB editions with SQL Server 2016 SP1. This consistent programmatically surface area allows developers and ISVs to develop and build applications leveraging the following features which can be deployed against any edition of SQL Server installed in the customer environment. The scale and high availability limits do not change, and remain as–is for lower editions as documented in this MSDN article.
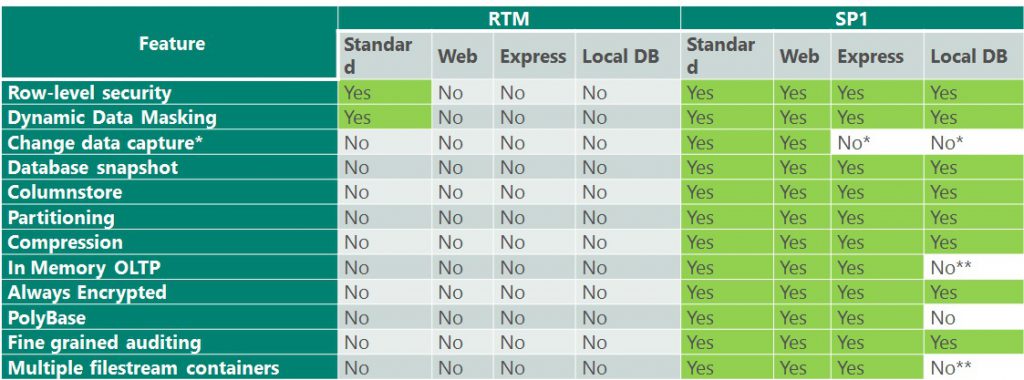 * Requires SQL Server agent which is not part of SQL Server Express Editions
* Requires SQL Server agent which is not part of SQL Server Express Editions
** Requires creating filestream file groups which is not possible in Local DB due to insufficient permissions.
Boosting transaction processing using Storage Class Memory in Windows Server 2016 - One of the most significant performance overheads for high transactional workloads systems is committing to the transaction log. This is especially true when employing In-Memory OLTP tables which remove most other bottlenecks from high update rate applications. SQL Server 2016 SP1 adds a significant new performance feature, the ability to accelerate transaction commit times by orders of magnitude, when employing Storage Class Memory (NVDIMM-N nonvolatile storage) supported in Windows Server 2016. This scenario is also referred to as “Persistent Log buffer” which is explained in detail in our SQL Server storage engine blog.
Database Cloning – Clone database is a new DBCC command added that allows DBAs and support teams to troubleshoot existing production databases by cloning the schema and metadata, statistics without the data. Cloned databases is not meant to be used in production environments. To see if a database has been generated from a call to clonedatabase you can use the following command, select DATABASEPROPERTYEX('clonedb', 'isClone'). The return value of 1 is true, and 0 is false. In SQL Server 2016 SP1, DBCC CLONEDATABASE added supports cloning of CLR, Filestream/Filetable, Hekaton and Query Store objects. DBCC CLONEDATABASE in SQL 2016 SP1 gives you the ability to generate query store only, statistics only, or pure schema only clone without statistics or query store. A CLONED database always contains the schema and the default clone also contains the statistics and query store data. For more information refer KB 3177838.
DBCC CLONEDATABASE (source_database_name, target_database_name) –– Default CLONE WITH SCHEMA, STATISTICS and QUERYSTORE metadata.
DBCC CLONEDATABASE (source_database_name, target_database_name) WITH NO_STATISTICS –– SCHEMA AND QUERY STORE ONLY CLONE
DBCC CLONEDATABASE (source_database_name, target_database_name) WITH NO_QUERYSTORE –– SCHEMA AND STATISTICS ONLY CLONE
DBCC CLONEDATABASE (source_database_name, target_database_name) WITH NO_STATISTICS,NO_QUERYSTORE –– SCHEMA ONLY CLONECREATE OR ALTER (Yes, we heard you !!!) – New CREATE OR ALTER support makes it easier to modify and deploy objects like Stored Procedures, Triggers, User–Defined Functions, and Views. This was one of the highly requested features by developers and SQL Community.
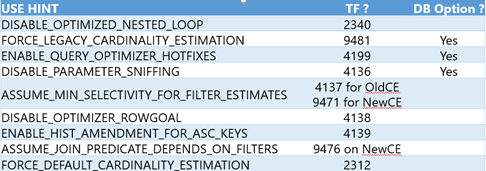
New USE HINT query option – A new query option, OPTION(USE HINT('<option>')) , is added to alter query optimizer behavior using supported query level hints listed below. Nine different hints are supported to enable functionality which was previously only available via trace flags. Unlike QUERYTRACEON, the USE HINT option does not require sysadmin privileges.
- Programmatically identify LPIM to SQL service account – New sql_memory_model, sql_memory_model_desc columns in DMV sys.dm_os_sys_info to allow DBAs to programmatically identify if Lock Pages in Memory (LPIM) privilege is in effect at the service startup time.
- Programatically identify IFI privilege to SQL service account – New column instant_file_initialization_enabled in DMV sys.dm_server_services to allow DBAs to programmatically identify if Instant File initialization (IFI) is in effect at the SQL Server service startup.
- Tempdb supportability – A new Errorlog message indicating the number of tempdb files and notifying different size/autogrowth of tempdb data files at server startup.
- Extended diagnostics in showplan XML – Showplan XML extended to support Memory grant warning, expose max memory enabled for the query, information about enabled trace flags, memory fractions for optimized nested loop joins, query CPU time, query elapsed time, top waits, and information about parameters data type.
- Lightweight per–operator query execution profiling – Dramatically reduces performance overhead of collecting per–operator query execution statistics such as actual number of rows. This feature can be enabled either using global startup TF 7412, or is automatically turned on when an XE session containing query_thread_profile is enabled. When the lightweight profiling is on, the information in sys.dm_exec_query_profiles is also available, enabling the Live Query Statistics feature in SSMS and populating a new DMF sys.dm_exec_query_statistics_xml.
- New DMF sys.dm_exec_query_statistics_xml – Use this DMF to obtain actual query execution showplan XML (with actual number of rows) for a query which is still being executed in a given session (session id as input parameter). The showplan with a snapshot of current execution statistics is returned when profiling infrastructure (legacy or lightweight) is on.
- New DMF for incremental statistics – New DMF sys.dm_db_incremental_stats_properties to expose information per–partition for incremental stats.
- Better correlation between diagnostics XE and DMVs – Query_hash and query_plan_hash are used for identifying a query uniquely. DMV defines them as varbinary(8), while XEvent defines them as UINT64. Since SQL server does not have "unsigned bigint", casting does not always work. This improvement introduces new XEvent action/filter columns equivalent to query_hash and query_plan_hash except they are defined as INT64 which can help correlating queries between XE and DMVs.
- Better troubleshooting for query plans with push–down predicate – New EstimatedlRowsRead attribute added in showplan XML for better troubleshooting and diagnostics for query plans with push down predicates.
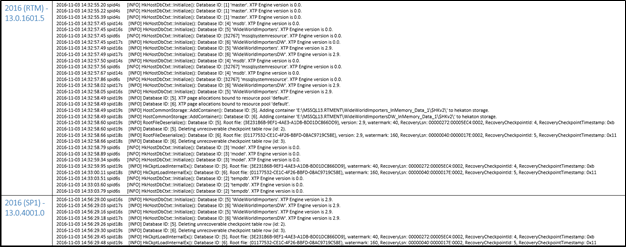
- Removing noisy Hekaton logging messages from Errorlog – With SQL 2016, Hekaton engine started logging additional messages in SQL Errorlog for supportability and troubleshooting which was overwhelming and flooded the Errorlog with hekaton messages. Based on feedback from DBAs and SQL community, starting SQL 2016 SP1, the Hekaton logging messages are reduced to minimal in Error log as shown below.
- Improved AlwaysOn Latency Diagnostics – New XEvents and Perfmon diagnostics capability added to troubleshoot latency more efficiently.
- Manual Change Tracking Cleanup – New cleanup stored procedure sp_flush_CT_internal_table_on_demand introduced to clean the change tracking internal table on demand. For more information, refer KB 3173157.
- DROP TABLE support for replication - DROP TABLE DDL support for replication to allow replication articles to be dropped. For more information, refer KB 3170123.
- Signed Filestream RsFx Driver on Windows Server 2016/Windows 10– The Filestream RsFx driver introduced with SQL Server 2016 SP1 is signed and certified using Windows Hardware Developer Center Dashboard portal (Dev Portal) allowing SQL Server 2016 SP1 Filestream RsFx driver to be installed on Windows Server 2016/Windows 10 without any issue. For more information on this issue, refer to the SQL Tiger team blogpost here.
- Bulk insert into heaps with auto TABLOCK under TF 715 – Trace Flag 715 enables table lock for bulk load operations into heap with no non–clustered indexes. When this trace flag is enabled, bulk load operations acquires bulk update (BU) locks when bulk copying data into a table. Bulk update (BU) locks allow multiple threads to bulk load data concurrently into the same table while preventing other processes that are not bulk loading data from accessing the table. The behavior is similar to when the user explicitly specifies TABLOCK hint while performing bulk load or when the sp_tableoption table lock on bulk load is on for a given table however enabling this TF makes this behavior by default without making any query changes or database changes. For more information, refer to the SQL Tiger team blog post here.
- Parallel INSERT..SELECT Changes for Local temp tables – With SQL Server 2016, Parallel INSERT in INSERT…SELECT operations was introduced. INSERTs into user tables required TABLOCK hint for parallel inserts while INSERTs into local temporary tables were automatically enabled for parallelism without having to designate the TABLOCK hint that user tables require. In a batch workload, INSERT parallelism significantly improves query performance but if there's a significant concurrent workload trying to run parallel inserts, it causes considerable contention against PFS pages which reduces the overall throughput of the system. This behavior introduced regression in OLTP workload migrating to SQL Server 2016. With SQL Server 2016 SP1, Parallel INSERTs in INSERT..SELECT to local temporary tables is disabled by default and will require TABLOCK hint for parallel insert to be enabled.
All the newly introduced Trace flags with SQL Server 2016 SP1 are documented and can be found at https://aka.ms/traceflags.
The full versions of the WideWorldImporters sample databases now work with Standard Edition and Express Edition, starting SQL Server 2016 SP1. No changes were needed in the sample. The database backups created at RTM for Enterprise edition simply work with Standard and Express in SP1. Download is here: https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0
The SQL Server 2016 SP1 installation may require reboot post installation. As a best practice, we recommend to plan and perform a reboot following the installation of SQL Server 2016 SP1.
We will be updating and adding follow-up posts on the Tiger blog in the coming weeks to describe some of the above improvements in detail.
As noted above, SP1 contains a roll-up of solutions provided in SQL Server 2016 cumulative updates up to and including the latest Cumulative Update – CU3 and Security Update MS16–136 released on November 8th, 2016. Therefore, there is no reason to wait for SP1 CU1 to 'catch–up' with SQL Server 2016 CU3 content.
The Service Pack is available for download on the Microsoft Download Center and ready to use in Azure Images Gallery and will also be made available on the, MSDN, Eval Center, MBS/Partner Source and VLSC in the coming weeks. As part of our continued commitment to software excellence for our customers, this upgrade is available to all customers with existing SQL Server 2016 deployments.
To obtain SQL Server 2016 SP1, please visit the links below:
SQL Server 2016 SP1 SQL Server 2016 SP1 Feature Pack SQL Server 2016 Service Pack 1 Release Information
Thank you,
Microsoft SQL Server Engineering Team