SQL Data Warehouse and Non-Clustered Indexes
One performance optimization that is often over looked in SQL Data Warehouse (SQL DW) is the use of non-clustered indexes (NCI) on tables with a clustered columnstore index (CCI). Clustered columnstore enhances the general performance benefits that RDBM systems bring to set based operations. Great value is derived from being able to apply set based operators on large amounts of data in parallel. However, not all operations in a workload are set based.
Massively parallel processing (MPP) systems like SQL DW generally provide enhanced scan rates due to parallelization of work across partitioned data, which in turn allows you to find specific rows very quickly. At a given number of nodes, as table sizes grow, the length of time to locate specific rows in your data grows linearly with the number of rows in the table. If the performance of lookups appears to increase with your table size at your performance level, you may find that adding a non-clustered index will improve your seek operations (lookups) on certain IDs in your fact tables, such as looking up records of a single employee or order etc.
As an example, one of the more expensive operations in a database can be a delete operation. Your table type, the amount of data you’re deleting, and the amount of rows you’re deleting can all influence the amount of time a delete operation takes. As a rule of thumb, if you’re deleting from a high-cardinality column on a large table where a value represents less than 5% of the total table size, consider putting . Because NCIs can impact load performance on a table, consider performing table cleanup with a maintenance schedule such as monthly where you create an NCI, perform your delete operations, and then drop the index.
Delete operations generally should not be used to remove large amounts of data from a table. In this case, creating a new table with CTAS is more performant.
As an example, consider this taxi trip table:
CREATE TABLE [dbo].[Trips2013]
(
[DateID] [int] NOT NULL
, [MedallionID] [int] NOT NULL
, [HackneyLicenseID] [int] NOT NULL
, [PickupTimeID] [int] NOT NULL
, [DropoffTimeID] [int] NOT NULL
, [PickupGeographyID] [int] NULL
, [DropoffGeographyID] [int] NULL
, [PickupLatitude] [float] NULL
, [PickupLongitude] [float] NULL
, [PickupLatLong] [varchar](50) NULL
, [DropoffLatitude] [float] NULL
, [DropoffLongitude] [float] NULL
, [DropoffLatLong] [varchar](50) NULL
, [PassengerCount] [int] NULL
, [TripDurationSeconds] [int] NULL
, [TripDistanceMiles] [float] NULL
, [PaymentType] [varchar](50) NULL
, [FareAmount] [money] NULL
, [SurchargeAmount] [money] NULL
, [TaxAmount] [money] NULL
, [TipAmount] [money] NULL
, [TollsAmount] [money] NULL
, [TotalAmount] [money] NULL
)
This table has 170,261,328 rows. If we look at the distribution of MedallionID, there are 13,688 different MedallionIDs, each with less than 1 percent of the total record set.
DECLARE @Total FLOAT = (SELECT COUNT_BIG(*) FROM [dbo].[Trips2013])
SELECT COUNT(*) AS NumRecords
, CAST(COUNT(*)/@Total AS DECIMAL(5,4)) AS PercentOfTotal
, [MedallionID]
FROM dbo.Trips2013
GROUP BY [MedallionID]
ORDER BY COUNT(*) DESC
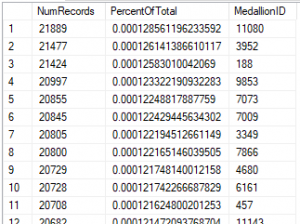
Let’s examine the delete performance to delete records where MedallionID is 11080. We’ll test the performance of CCI and HEAP tables, with and without NCI.
Here are the corresponding DML statements:
-- CCI NO NCI
IF OBJECT_ID('CCI_DELETE', 'U') IS NOT NULL DROP TABLE CCI_DELETE
CREATE TABLE CCI_DELETE
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
AS SELECT * FROM [dbo].[Trips2013]
OPTION (label = 'Creating CCI_DELETE table')
-- CCI WITH NCI
IF OBJECT_ID('CCI_NCI_DELETE', 'U') IS NOT NULL DROP TABLE CCI_NCI_DELETE
CREATE TABLE CCI_NCI_DELETE
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
AS SELECT * FROM [dbo].[Trips2013]
OPTION (label = 'Creating CCI_NCI_DELETE table')
CREATE NONCLUSTERED INDEX CCI_NCI_DELETE_index ON CCI_NCI_DELETE([MedallionId])
-- HEAP NO NCI
IF OBJECT_ID('HEAP_DELETE', 'U') IS NOT NULL DROP TABLE HEAP_DELETE
CREATE TABLE HEAP_DELETE
WITH
(
DISTRIBUTION = ROUND_ROBIN,
HEAP
)
AS SELECT * FROM [dbo].[Trips2013]
OPTION (label = 'Creating HEAP_DELETE table')
-- HEAP WITH NCI
IF OBJECT_ID('HEAP_NCI_DELETE', 'U') IS NOT NULL DROP TABLE HEAP_NCI_DELETE
CREATE TABLE HEAP_NCI_DELETE
WITH
(
DISTRIBUTION = ROUND_ROBIN,
HEAP
)
AS SELECT * FROM [dbo].[Trips2013]
OPTION (label = 'Creating HEAP_NCI_DELETE table')
CREATE NONCLUSTERED INDEX HEAP_NCI_DELETE_index ON HEAP_NCI_DELETE([MedallionId])
-- CI NO NCI
IF OBJECT_ID('CI_DELETE', 'U') IS NOT NULL DROP TABLE CI_DELETE
CREATE TABLE CI_DELETE
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED INDEX (DateID ASC)
)
AS SELECT * FROM [dbo].[Trips2013]
OPTION (label = 'Creating CI_DELETE table')
-- CI WITH NCI
IF OBJECT_ID('CI_NCI_DELETE', 'U') IS NOT NULL DROP TABLE CI_NCI_DELETE
CREATE TABLE CI_NCI_DELETE
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED INDEX (DateID ASC)
)
AS SELECT * FROM [dbo].[Trips2013]
OPTION (label = 'Creating CI_NCI_DELETE table')
CREATE NONCLUSTERED INDEX CI_NCI_DELETE_index ON CI_NCI_DELETE([MedallionId])
-- DELETE FROM CCI NO NCI
DELETE FROM CCI_DELETE
WHERE MedallionId = 11080
OPTION (label = 'DELETE CCI NO NCI')
-- DELETE FROM CCI WITH NCI
DELETE FROM CCI_NCI_DELETE
WHERE MedallionId = 11080
OPTION (label = 'DELETE CCI WITH NCI')
-- DELETE FROM HEAP NO NCI
DELETE FROM HEAP_DELETE
WHERE MedallionId = 11080
OPTION (label = 'DELETE HEAP NO NCI')
-- DELETE FROM HEAP WITH NCI
DELETE FROM HEAP_NCI_DELETE
WHERE MedallionId = 11080
OPTION (label = 'DELETE HEAP WITH NCI')
-- DELETE FROM CCI NO NCI
DELETE FROM CI_DELETE
WHERE MedallionId = 11080
OPTION (label = 'DELETE CI NO NCI')
-- DELETE FROM CCI NO NCI
DELETE FROM CI_NCI_DELETE
WHERE MedallionId = 11080
OPTION (label = 'DELETE CI WITH NCI')
-- OVERALL
SELECT AVG(DATEDIFF(millisecond, start_time, end_time)) AS avg_duration
, [label]
FROM sys.dm_pdw_exec_requests
WHERE [label] = 'DELETE CCI NO NCI'
OR [label] = 'DELETE CCI WITH NCI'
OR [label] = 'DELETE HEAP NO NCI'
OR [label] = 'DELETE HEAP WITH NCI'
OR [label] = 'DELETE CI NO NCI'
OR [label] = 'DELETE CI WITH NCI'
GROUP BY [label]
ORDER BY avg_duration DESC
What we would expect to have happen here is that a table with NCI would perform deletes faster. Why is this? In the absence of an NCI, each of the SQL Server compute nodes will have to completely scan each distribution table of dbo.Trips2013 where MedallionID = 11080. With columnstore, there is some benefit of segment elimination, but without tight boundaries on segment min and max values, SQL Server will have to end up scanning most of the columnstore segments.
An NCI on top of your CCI provides pointers to the physical row locations. As long we’re not deleting large numbers of consecutive records, this physical pointer should enable us to find the columnstore segments that contain rows that match our delete predicate faster than scanning all segments.
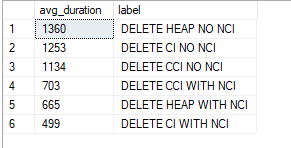
Running these statements 10 times on DW1000, as we would expect, our average time demonstrates that having NCI for targeted lookups is indeed more performant for deletes than without an NCI. Bear in mind, these tests were run with round robin distributions. Hashing on a specific column may yield differences in performance due to data skew and where the deleted rows ultimately end up.
If you would like to try this for yourself, I used the 2013 New York taxi cab data that’s hosted publicly by the SQL Data Warehouse team which you can download following instructions here: /en-us/azure/sql-data-warehouse/load-data-from-azure-blob-storage-using-polybase.