Balisage 2009标识技术会议(六)
第三天(8/13/2009),下午
关键词:SIMD,XML,高性能处理
首先让我揭开上篇文章里的谜底,那是一只笔(右图),有兴趣的读者可以bing一下“PenAgain”。 
今天中午,和其他与会者一起用午餐,我有幸认识从加拿大温哥华专程前来参加Balisage 2009的西蒙•佛雷泽大学(Simon Fraser University)计算机科学系的罗伯特D. 卡麦隆教授(Dr. Robert D. Cameron)。他很高兴地给我介绍了他和他的学生一起正在研究的项目,简而言之是利用现在愈来愈受到关注的CPU支持的SIMD(single instruction,multiple data)[1]指令集提高XML文件的处理速度。
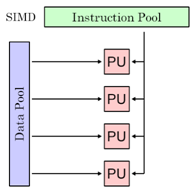
想了解这究竟是一项什么样的技术?得先了解什么是SIMD,所谓的“单一指令,多数据”,也就是说CPU可同时在一个集合的数据上同时执行同一条指令。这个技术现在被广泛运用在计算机的图像处理单元(GPU),而越来越多的主流CPU也具备了类似的功能。我们拿Intel最新i7架构的CPU举例,它支持SSE(Streaming SIMD Extensions)4.2指令集,内置多个128位专门用于SIMD的寄存器。也就是说,可以将16个字节的ASCII数据或是8个双字节的Unicode数据载入一个128位的寄存器,然后同时对这128位数据进行查询,索引,位操作等功能。
而让我大开眼界的是,卡麦隆教授的项目组通过他们的不懈努力终于研究发明了一项独特的技术,称为parabix(Parallel bit streams for XML™)[2],它利用位加法可以充分利用SIMD的优势成倍地提高XML的处理速度,而这项技术更可以广泛运用在其他数据处理领域,比如他们写的UTF8到UTF16的转码程序可以平均使用0.9-6.8个CPU时钟周期处理每字节数据,速度是标准的UNIX下字符编码转换程序iconv的十倍。
经卡麦隆教授允许,我在这里借用parabix公开的技术资料[3]中的内容给读者来介绍一下SIMD位加法的基本概念。假设我们有一窜XML字符数据,如表中所示,我们想做的是找出字符串中所有用“&#数字序列;”表示的Unicode特征项:
原数据共16字节,以下均采用SIMD指令。 |
1ऩC:89a |
第一步:将字符串反转,因为Intel是little-endian |
a98:76#&;5432#&1 |
第二步:采用字符串查找指令找到所有数字 |
.11.11...1111..1 |
第三步:找到所有“&#”,对应位置1 |
......1......1.. |
第四步:将第三步结果左移一位 |
.....1......1... |
第五步:将第二步与第四步结果相加 |
.11100..10000..1 |
第六步:将第五步结果和第二部结果取非值相异或 |
...100..10000... |
第七步:将第六部结果减第四部结果 |
....11...1111... |
第八步:找到所有“;”,对应位置1 |
........1....... |
第九步:将第六部结果和第八步结果相异或 |
...1............ |
经过以上运算,由第七步找到两个可能的特征项,而第九步结果表示其中一个是错误的,并提供了具体错误的位置。
我想通过以上的介绍,你一定会和我一样为SIMD技术在XML和其他数据处理领域所能发挥的作用而鼓舞。
网络参考链接: